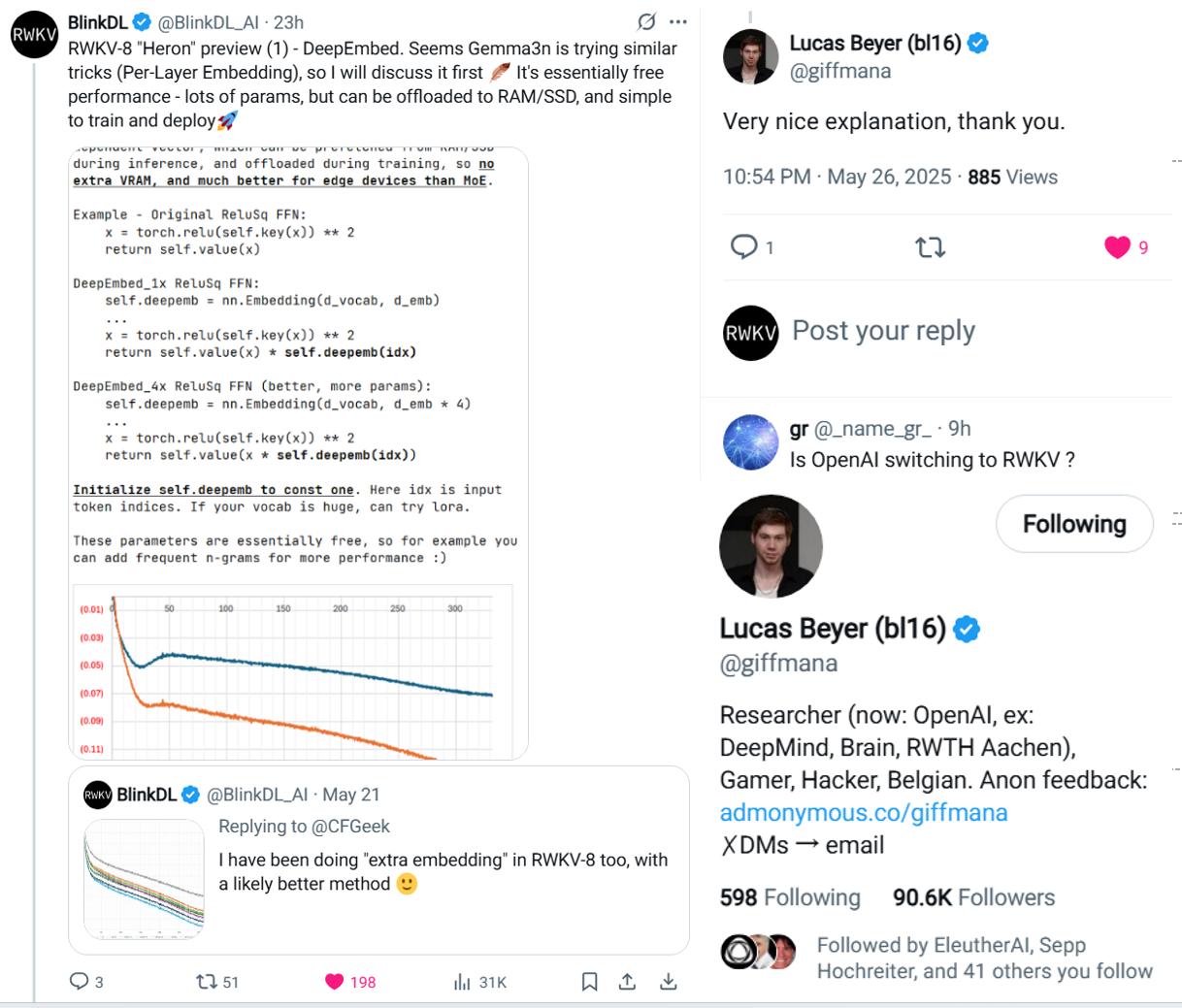
RWKV-8 "Heron" 是我们的下一代架构,具有多个全新技术。在此我们首先公布其中的 DeepEmbed 技术,它可以实现类似 MoE 的优秀推理性能,同时无需占用显存,甚至无需占用内存,可以让稀疏的大模型真正部署到所有端侧设备。
下文将详细介绍 DeepEmbed 的原理与实现:
什么是 DeepEmbed
DeepEmbed 在模型的每一层 FFN 中为词表中的每个 token 训练一个可学习的高维向量,这可以写成 Embed 层。这些向量在训练阶段可被学习,而在推理阶段可存储于 RAM/SSD 中,对于每个 token 只需预读极少量参数,从而显著减少显存占用。
推理时,模型根据 token index 可提前预读本层的 embedding 向量,用于对 FFN 输出进行逐通道的乘性调制(channelwise scaling)。
这些基于 token 的 embedding 向量构成了一个规模庞大但稀疏的知识库,能够显著提升模型存储和调用世界知识的能力。尽管这些向量看似增加了模型参数量,但不需要占用显存,且在训练过程中可通过 TP(Tensor Parallelism)避免 DP(Data Parallelism)中梯度同步的带宽开销,并可进一步 offload 至 RAM 或 SSD。
在端侧推理场景下,这些向量同样可存储于内存中,或通过 mmap 等机制直接从硬盘按需加载。每个 token 仅引入几十 KB 的额外访存开销,使该机制非常适合在边缘设备上部署。
DeepEmbed 代码示例
原始 ReLuSq FFN:
x = torch.relu(self.key(x)) ** 2
return self.value(x)
DeepEmbed_1x ReLuSq FFN:
self.deepemb = nn.Embedding(d_vocab, d_emb)
...
x = torch.relu(self.key(x)) ** 2
return self.value(x) * self.deepemb(idx)
DeepEmbed_4x ReLuSq FFN(效果更佳,参数更多):
self.deepemb = nn.Embedding(d_vocab, d_emb * 4)
...
x = torch.relu(self.key(x)) ** 2
return self.value(x * self.deepemb(idx))
从代码可以看出,self.deepemb 用于对 FFN 的输出或中间结果进行乘法缩放。这里的 idx 是输入的 token 索引。需要:注意将 self.deepemb 向量初始化为常数 1,以确保训练初期不会干扰模型行为。
self.deepemb 向量并不直接修改 FFN 的参数,而是以 token 为单位,替代了原本基于输入动态生成的门控向量在通道维度上的乘性调制功能,使模型对 token 的语义或类别具备更强的感知能力。
由于查表操作在推理时不占用 VRAM,这些向量在参数量层面几乎是"免费的"。因此,还可以进一步引入 n-gram(如 bigram、trigram),提升模型对词组/片段的建模能力。如果词表规模较大,也可结合 LoRA 技术降低显存和训练开销。
实验结果表明:相较于 baseline,更大规模的 DeepEmbed 能够带来更显著的 loss 改善。
DeepEmbed 技术在 twitter 公布后,引发多方关注, 包括 ViT 作者 Lucas Beyer。
未来我们会逐渐公布 RWKV-8 的更多创新技术。
![]()
加入 RWKV 社区
欢迎大家加入 RWKV 社区,可以从 RWKV 中文官网了解 RWKV 模型,也可以加入 RWKV 论坛、QQ 频道和 QQ 群聊,一起探讨 RWKV 模型。