DeepSeek 的横空出世,让国人看到了 AI 大模型领域的中国式创新 —— 无需过度依赖高端芯片,通过算法、系统与算力层的协同优化,同样有望打造出媲美 OpenAI 的超级应用。就在全民抢抓人工智能变革机遇的当下,国产大模型应用正在加速落地,算力层的技术创新与突破也呼之欲出。
“放大系统集群优势,弱化单卡性能依赖。” 正成为中国 AI 算力发展的更优解与核心趋势。如何紧扣这一趋势,以 “黑科技” 推动应用效果扎实落地?昇腾超节点给出了最佳示例。
昇腾超节点破局算力瓶颈
简单来说,由服务器、存储、网络等设备堆叠起来的传统算力集群,在面对大模型训练时,通常会因为资源利用率低、故障频发,阻碍 AI 的发展与创新。同时,随着大模型 Token 体量的不断增加,“小作坊” 式的服务器级算力供给模式,也很难支持千亿级大模型训练和推理时的海量算力支持。
针对这一痛点,华为推进全面智能化战略( All Intelligence ),基于实际可获得的芯片制造工艺,计算、存储和网络技术协同创新,打造 “超节点 + 集群” 系统算力解决方案,长期持续满足大模型迭代所带来的算力需求。
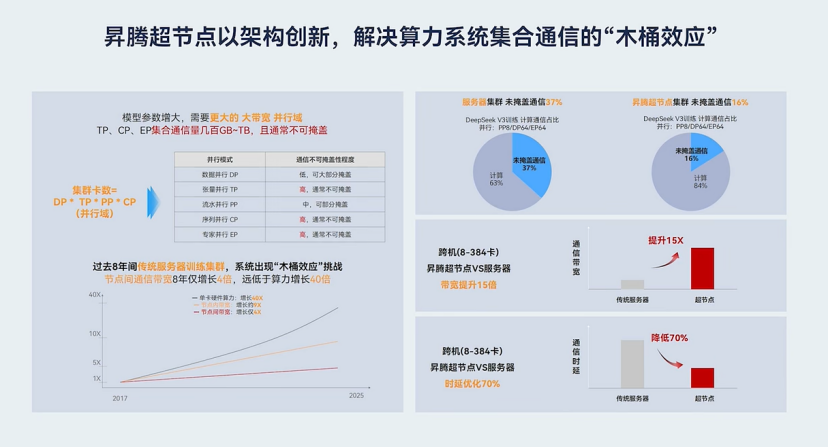
昇腾超节点作为新一代 AI 基础设施架构的创新典范,通过自研高速总线链接多颗 NPU ,突破互联瓶颈,让集群像一台计算机一样工作。跨节点通信带宽提高 15 倍;通信时延从 2μs 降至 0.2μs ,下降 10 倍;最大可实现 384 颗 NPU 点到点超大带宽互联,是目前业界唯一支持 DeepSeek V3/R1 在一个超节点域内即可完成所有的专家并行( EP )的方案。
![]()
从当前行业实践和技术发展来看,MoE(混合专家)模型已然成为构建超大 AI 系统的主流架构之一,尤其是在自然语言处理( NPL )、多模态交互和工业级 AI 应用中展现出不可替代的优势。
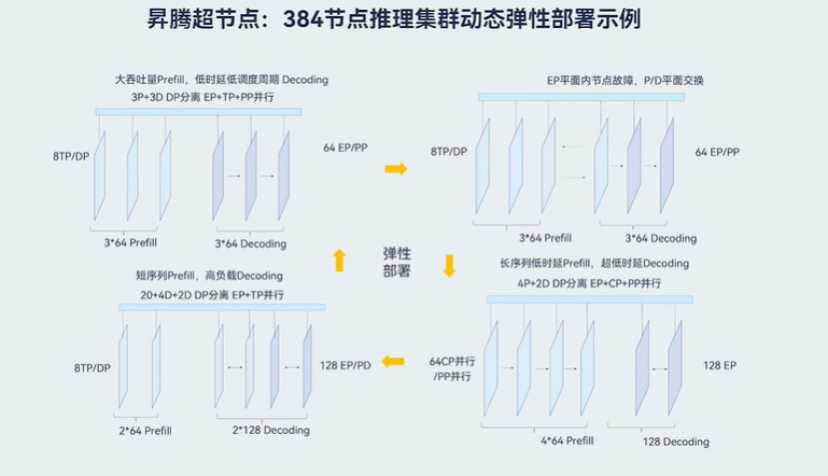
而昇腾超节点架构能够依据 MoE 结构中的专家分布以及每层的计算需求,精细地将各模型切分至不同节点,更合理分配资源,提高整体资源利用率,同时可运行多种并行策略并动态调整,针对实时的负载情况精准分配计算资源,加速训练 / 推理进程,可谓是当下 MoE 模型的最佳训练 / 推理方案。
同时,昇腾超节点解决方案中还包括了多款训练和推理产品,基于超节点的创新架构,更好地满足模型训练 / 推理对低时延、大带宽、长稳可靠的需求。
除此之外,华为充分发挥计算、网络、存储等 ICT 硬件领域的工程经验,推出 Atlas 900 A3 SuperCluster AI 集群,突破 Scale Up 物理节点计算瓶颈,让成百上千个 NPU 以 TB 级带宽超高速互联、内存统一编址,就像一个节点一样高效工作。此外,基于超节点架构,华为还推出了 Atlas 900 昇腾 384 超节点产品和 Atlas 800 A3 超节点产品配合专家并行加速算法,通过将专家模型拆解成多个子专家,并分配到不同的计算节点上独立执行,实现了低时延下更大的吞吐量,为大规模推理场景提供解决方案,进一步创新突破大模型训练、推理算力瓶颈。
![]()
昇腾超节点的优势
上文粗略为大家展现了昇腾超节点的核心优势,接下来让咱们深入应用场景,谈谈昇腾超节点有哪些 “黑科技”?
高速互联:
大模型(特别是千亿参数级的 MoE 模型)的训练需要多芯、多节点协同工作,通过分布式训练将计算负载分摊到不同设备。此时,设备之间的数据通信效率就成为了核心瓶颈。传统集群方案依托于以太网、PCle 等通用互联技术,通信带宽低、延迟高,在模型并行训练中,不同芯片之间需要频繁交换中间层参数(如 Transformer 的多头注意力输出),通信耗时可能占到整体训练时间的 50% 以上。
而昇腾超节点,凭借其架构的高速互联能力,大幅提升并行计算时的通信效率,且 All 2 All 集合通信性能可提升 5 倍,send/recv 集合通信性能可提升 7 倍,大幅降低整体通信占比,让计算少等待、不等待。较之传统集群,整体训练效率、推理吞吐可提升 3 倍。
精准分配:
昇腾超节点的核心突破在于,根据 MoE 的 “专家特性” 和 “层特性” 进行动态、精细化的资源调度,而非采用统一的切分策略。在实际应用中,超节点根据 MoE 结构中专家分布(例如:计算密集型专家、参数密集型专家、低频专家等),以及每层的计算需求,精细地将各模型切分至不同节点,实现合理资源分配。
同时,在实际工作中,超节点还可针对实时的负载情况,合理调节各节点的计算负载、内存占用等指标,有效加速模型训练 / 推理速度。例如,当某节点的专家计算过载时,自动将部分输入路由至其他节点的冗余专家(如热备份专家)。
![]()
全局内存统一编址:
昇腾超节点在内存管理与通信架构上同样实现了技术突破,其核心通过全局内存统一编址,具备更高效的内存语义通信能力。通过更低时延指令级内存语义通信,可满足大模型训练 / 推理中的小包通信需求,提升专家网络小包数据传输及离散随机访存通信效率。
更稳底座:
无论是训练,还是推理,断点故障永远是各大模型的沉默成本。昇腾超节点采用多平面的链路设计、链路故障秒级切换、算子级重传等可靠性能力,确保大模型训练不中断,平均无故障运行时长从几小时提升到几天;同时支持更敏捷的断点续训,故障恢复时长从小时级降低至 30 分钟。
在多维度的优势下,昇腾超节点在很多智能应用场景下都表现出不俗实力。例如,在智慧金融的实时风控模型训练中,能快速处理海量数据,精准识别风险;在智慧医疗的影像分析推理场景下,能快速完成对大量医学影像的分析;在在自动驾驶的多传感器融合训练中,高效处理复杂的传感器数据,提升自动驾驶模型的准确性和可靠性等等。
从技术创新到生态跃迁
华为创新,实干兴邦。在 AI 竞赛的激烈战场上,算力基础无疑是智能应用发展的根基,随着 2025 AI 应用大爆发,高速、高效、稳定的算力基础设施建设更是 AI 发展的必由之路。
昇腾超节点的诞生,不仅是算力层技术上的突破,更是中国算力自主化进程中的重要里程碑。它标志着中国在 AI 算力领域不再受制于人的局面正在逐步改变,为国产大模型的发展提供了坚实的支撑。
然而,今天的超节点仅仅只是一个起点。在未来的道路上,华为将始终保持不断探索和创新人工智能技术的姿态,持续加大在算力领域的研发投入,推动技术的不断升级与迭代。随着相关产业生态的日益完善,一场关于算力与智能的变革正悄然来临。
值得关注的是,即将举办的 KADC 鲲鹏昇腾开发者大会 2025 将成为窥探算力产业趋势的重要窗口。区别于往年,今年的 KADC 采用线上 & 线下同步进行的方式,在正式线下大会之前举办 “鲲鹏昇腾创享周”(线上直播)活动,邀请资深研发专家讲解硬核技术,解密代码背后的故事。
|
鲲鹏:RAG 解决方案、AlAgent、推理能力等内容;
异腾:推理加速、大规模专家并行、RL、MLA 融合算子和通信算法发布等内容。 |
届时,业界专家、开发者们将汇聚一堂,共同探讨昇腾技术的最新进展和产业应用前景,为 AI 的广泛应用和产业的蓬勃发展注入新的活力。在 AI 应用大爆发的时代,昇腾超节点正以其强大的实力和创新的姿态,引领着中国 AI 产业迈向更加广阔的未来,让我们共同期待华为在算力领域续写更多的传奇,为国产算力的崛起贡献更多的力量。