腾讯混元联合上海 AI Lab、复旦大学、上海创智学院,于近日正式推出了全新研究成果 —— 统一多模态奖励模型(Unified Reward-Think)。“首次让奖励模型在各视觉任务上真正 “学会思考”,实现对复杂视觉生成与理解任务的准确评估、跨任务泛化与推理可解释性的大幅提升。”
目前该项目已全面开源:包括模型、数据集、训练脚本与评测工具。“UnifiedReward-Think 展示了奖励模型的未来方向 —— 不仅仅是一个 “打分器”,而是一个具备认知理解、逻辑推理与可解释输出能力的智能评估系统。”
一、背景与动机:奖励模型也需要 “思考”
当前的多模态奖励模型大多只能对结果进行 “表面判断”,缺乏深度推理与可解释的决策依据,难以支撑对复杂视觉任务的精准评估。该工作研究团队提出关键问题:是否可以引入 “长链式思考”(Chain-of-Thought, CoT)机制,赋予奖励模型更强的推理能力?
挑战在于,当前缺乏高质量的多模态 CoT 奖励推理数据,传统 SFT 等训练范式难以直接教会模型掌握推理过程。他们认为,多模态大模型本身具备深层、多维度的推理潜力,关键在于设计一套高效训练范式去激发并强化奖励模型的 “思考能力”。
![]()
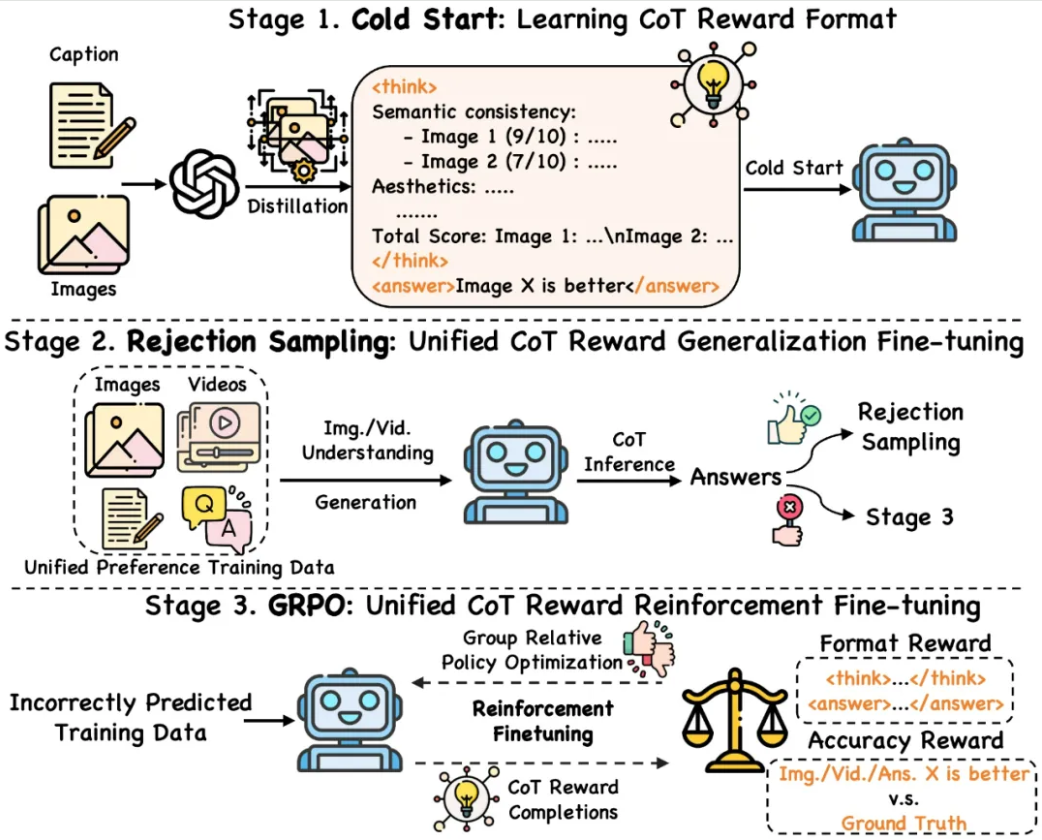
二、解决方案:三阶段训练范式,逐步进化奖励模型推理能力
该研究提出一套新颖的 “三阶段” 训练框架,分为 “激发 → 巩固 → 强化”,层层推进模型的推理进化:
阶段一:冷启动激发(Cold Start)
使用仅 5K 图像生成任务的高质量 CoT 奖励推理数据,让模型学会基本的推理格式与结构。实验表明,这一阶段就能激发模型在多个视觉任务中的推理能力。
阶段二:拒绝采样巩固(Rejection Sampling)
利用冷启动后的模型在各视觉任务的泛化能力,对大规模多模态偏好数据进行推理,通过拒绝采样剔除逻辑错误样本,强化模型对正确思维链的推理模式。
阶段三:GRPO 强化(Group Relative Policy Optimization)
针对推理错误样本,引入 GRPO 强化学习机制,引导模型探索多样化推理路径,从错误中学习,逐步收敛到正确逻辑思考。
三、实验亮点:奖励模型不仅能 “显示长链推理”,还能 “隐式逻辑思考”
UnifiedReward-Think 在多个图像生成与理解任务中进行了系统评估,结果表明该模型具备多项突破性能力:
- 更强可解释性:能够生成清晰、结构化的奖励推理过程;
- 更高可靠性与泛化能力:各视觉任务均表现出显著性能提升;
- 出现隐式推理能力:即使不显式输出思维链,模型也能作出高质量判断,表明推理逻辑已 “内化” 为模型能力的一部分。
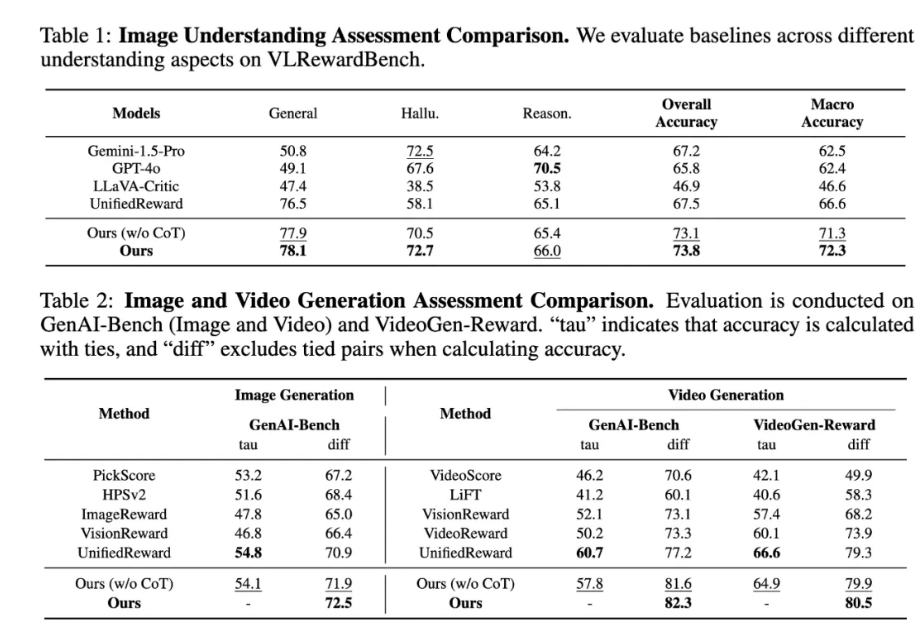
- 定量实验:长链推理带来全面性能飞跃
![]()
定量结果表明,在图像与视频生成奖励任务中,全面优于现有方法;在图像理解类奖励任务上,长链思维链推理带来显著性能提升,验证了复杂视觉理解对深度推理能力的高度依赖;即便在不显式输出思维链的情况下,模型仍能通过隐式逻辑推理保持领先表现,相比显式 CoT 推理仅有轻微下降,展现出强大的 “内化逻辑” 能力;与基础版本 UnifiedReward 相比,加入多维度、多步骤推理带来了多任务的全面性能跃升,验证了 “奖励模型也能深度思考” 的价值。
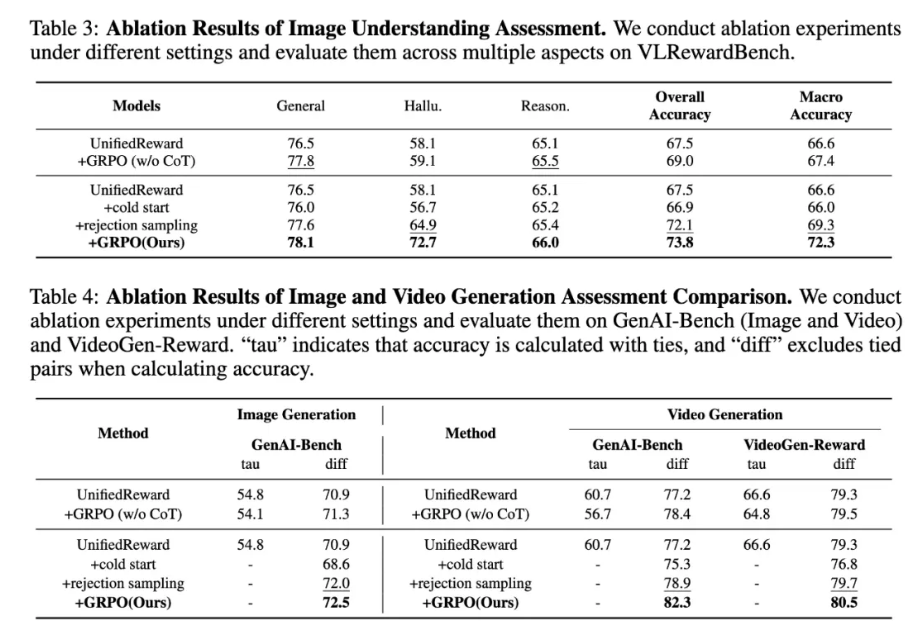
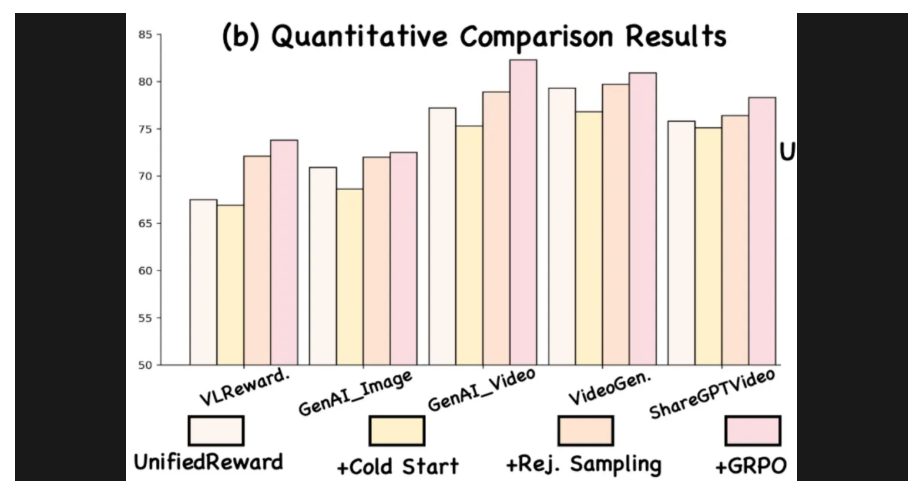
消融实验:三阶段训练策略缺一不可
该工作进行了系统的消融实验,验证三阶段训练范式中每一步的独立贡献:
- 冷启动阶段:模型学会了 CoT 推理的结构,但对奖励预测的准确性仍较有限;
- 拒绝采样阶段:通过筛除推理错误样本,显著提升了模型对 “正确思维链” 的偏好,有效增强了模型的稳定性与泛化性;
- GRPO 阶段:提升幅度最大,模型聚焦于错误推理样本,通过多路径推理探索,逐步收敛至更精确的推理过程,体现出该阶段对 “推理纠错” 的关键作用。
无推理路径的 GRPO 版本效果显著下降。进一步验证:若去除 CoT 推理、让奖励模型仅对最终答案进行 GRPO 强化,虽然略优于 baseline,但提升比较有限。说明仅优化结果远不足以驱动深层推理能力的形成。
结论:显式建模思维链推理路径,是强化奖励模型泛化与鲁棒性的关键。GRPO 训练阶段之所以有效,根源在于 “强化正确推理过程”,而非仅仅是 “强化正确答案”。
![]()
![]()
更多详情可查看官方公告。