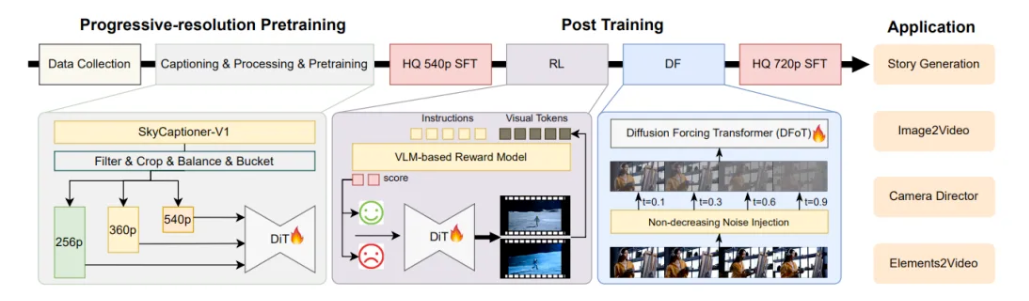
昆仑万维SkyReels团队正式发布并开源SkyReels-V2,据称为全球首个使用扩散强迫(Diffusion-forcing)框架的无限时长电影生成模型,其通过结合多模态大语言模型(MLLM)、多阶段预训练(Multi-stage Pretraining)、强化学习(Reinforcement Learning)和扩散强迫(Diffusion-forcing)框架来实现协同优化。
根据介绍,SkyReels-V2现已支持生成30秒、40秒的视频,且具备生成高运动质量、高一致性、高保真视频的能力。
![]()
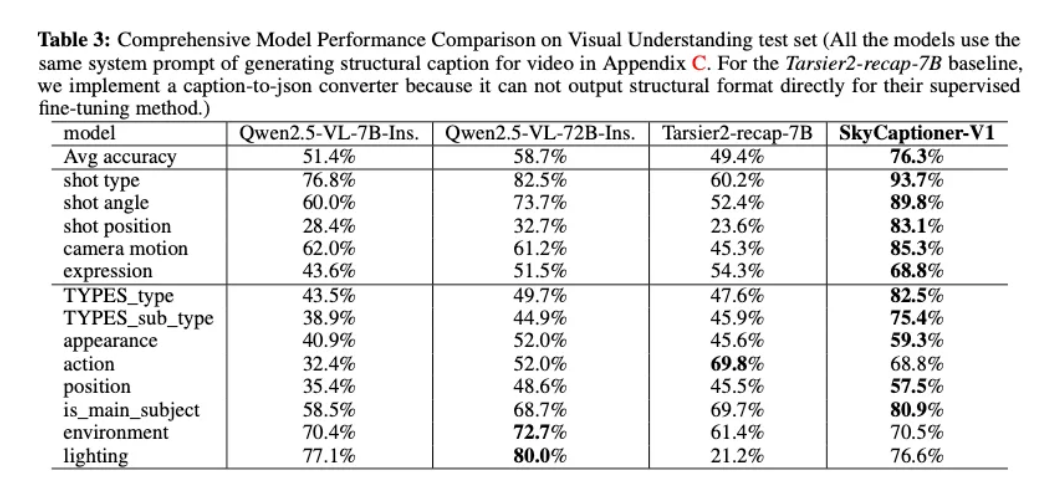
- 全面的影视级视频理解模型:SkyCaptioner-V1
为了提高提示词遵循能力,团队设计了一种结构化的视频表示方法,将多模态LLM的一般描述与子专家模型的详细镜头语言相结合。这种方法能够识别视频中的主体类型、外观、表情、动作和位置等信息,同时通过人工标注和模型训练,进一步提升了对镜头语言的理解能力。
同时,团队训练了一个统一的视频理解模型 SkyCaptioner-V1,它能够高效地理解视频数据,生成符合原始结构信息的多样化描述。通过这种方式,SkyCaptioner-V1不仅能够理解视频的一般内容,还能捕捉到电影场景中的专业镜头语言,从而显著提高了生成视频的提示词遵循能力。此外,这个模型现在已经开源,可以直接使用。
![]()
- 针对运动的偏好优化
现有的视频生成模型在运动质量上表现不佳,主要原因是优化目标未能充分考虑时序一致性和运动合理性。项目团队通过强化学习(RL)训练,使用人工标注和合成失真数据,解决了动态扭曲、不合理等问题。为了降低数据标注成本,设计了一个半自动数据收集管道,能够高效地生成偏好对比数据对。
通过这种方式,SkyReels-V2在运动动态方面表现优异,能够生成流畅且逼真的视频内容,满足电影制作中对高质量运动动态的需求。
![]()
- 高效的扩散强迫框架
为了实现长视频生成能力,SkyReels团队提出了一种扩散强迫(diffusion forcing)后训练方法。与从零开始训练扩散强迫模型不同,通过微调预训练的扩散模型,将其转化为扩散强迫模型。这种方法不仅减少了训练成本,还显著提高了生成效率。
采用非递减噪声时间表,将连续帧的去噪时间表搜索空间从 O(1e48) 降低到 O(1e32),从而实现了长视频的高效生成。这一创新使得SkyReels-V2能够生成几乎无限时长的高质量视频内容。
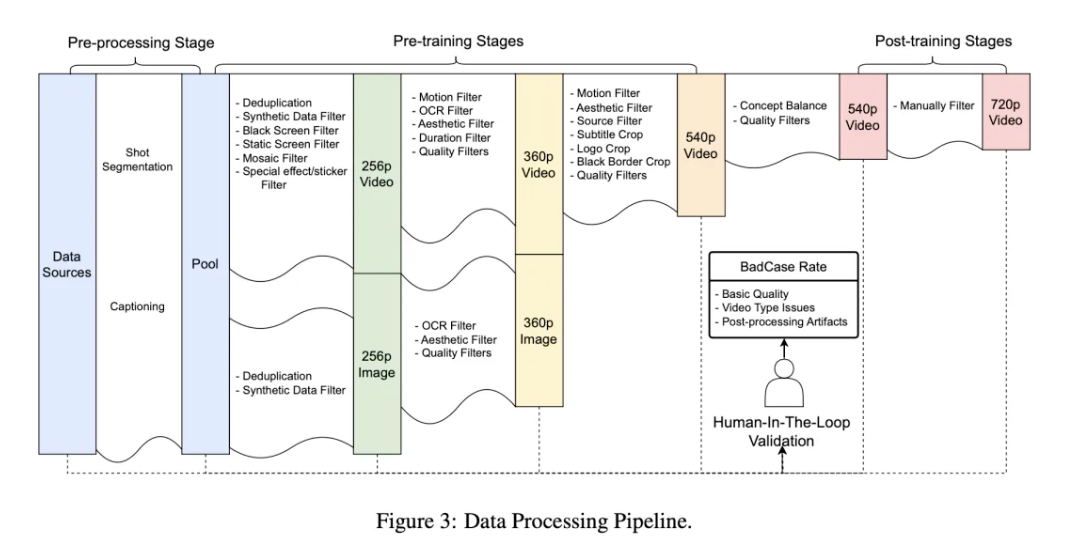
- 渐进式分辨率预训练与多阶段后训练优化
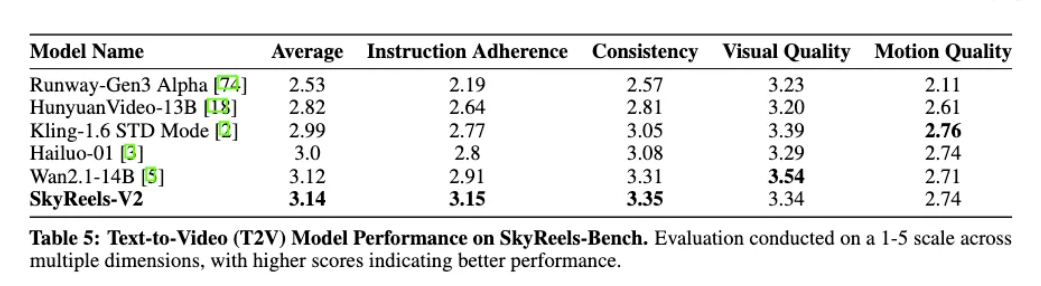
为了全面评估SkyReels-V2的性能,SkyReels团队构建了SkyReels-Bench用于人类评估,并利用开源的V-Bench进行自动化评估。
![]()
SkyReels-Bench包含1020个文本提示词,系统性地评估了四个关键维度:指令遵循、运动质量、一致性和视觉质量。该基准旨在评估文本到视频(T2V)和图像到视频(I2V)生成模型,提供跨不同生成范式的全面评估。
在SkyReels-Bench评估中,SkyReels-V2在指令遵循方面取得了显著进展,同时在保证运动质量的同时不牺牲视频的一致性效果。
![]()
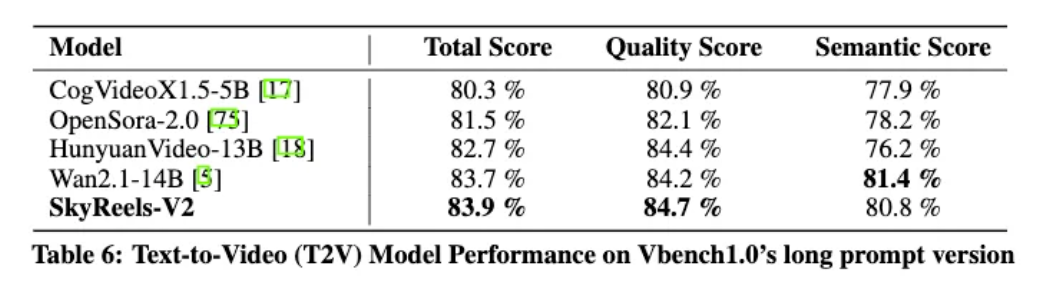
在VBench1.0自动化评估中,SkyReels-V2在总分(83.9%)和质量分(84.7%)上均优于所有对比模型,包括HunyuanVideo-13B和Wan2.1-14B。
![]()