在数据处理领域,Apache Flink 一直以其强大的实时流处理能力而闻名。3 月 24 日,Flink 2.0 正式发布,这不仅是对以往版本的一次重大升级,更是实时数据处理领域的一次史诗级革新。本文将带你深入了解 Flink 是什么,它的适用场景,以及 Flink 2.0 中那些值得关注的新特性。
Apache Flink Apache Flink 是一款分布式流处理框架,专为有状态计算设计,能够高效处理无界和有界数据流。自 2014 年成为 Apache 顶级项目以来,Flink 凭借其低延迟、高吞吐、精确一次(Exactly-Once)语义和流批一体化能力,成为全球实时计算领域的标杆技术。
核心特性:
流处理优先 :原生支持事件时间(Event Time)处理和状态管理,适用于动态数据流场景。
流批一体 :同一套 API 同时支持流式与批量数据处理,简化开发流程。
高容错性 :基于分布式快照(Checkpoint)和保存点(Savepoint)实现故障恢复与版本升级无缝衔接。
灵活部署 :支持 YARN、Kubernetes、独立集群等多种部署模式,适配云原生架构。
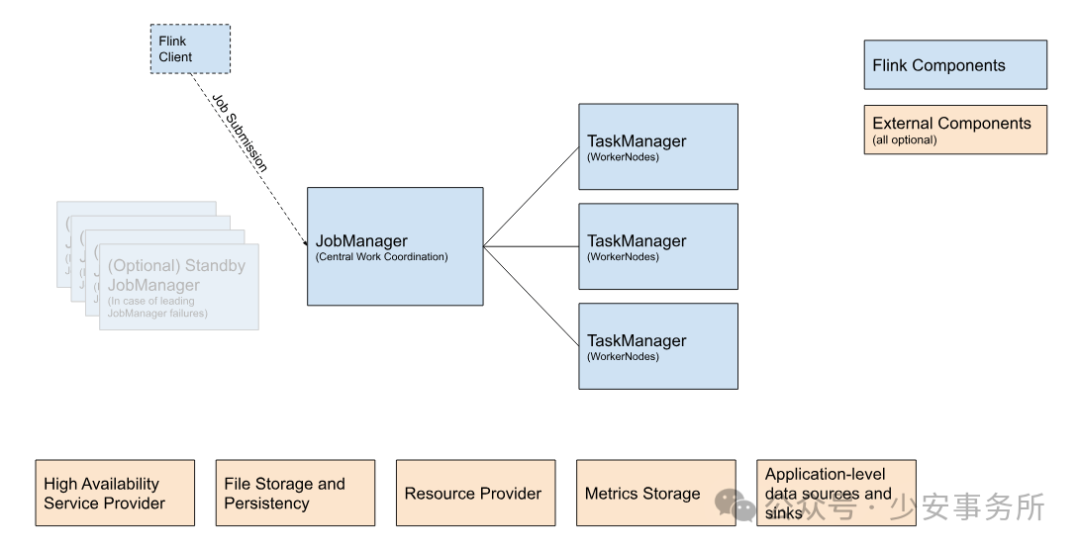
Flink 的架构核心包括 JobManager(负责资源协调与任务调度)和 TaskManager(执行具体计算任务),通过 Task Slot 机制实现资源隔离与高效利用。
Flink 的典型应用场景 Flink 的适用场景覆盖从实时分析到复杂事件驱动的全链路需求,以下是其核心应用领域:
1. 实时数据分析 Flink 在实时数据分析领域有着广泛的应用。它可以处理来自各种数据源的实时数据流,如日志文件、传感器数据、社交媒体数据等,并进行实时的聚合、过滤和转换操作。例如,电商企业可以通过 Flink 实时分析用户的购买行为,及时调整推荐策略,提高销售额。
2. 事件驱动型应用 事件驱动应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。Flink 的状态管理和时间处理能力使其成为构建事件驱动应用的理想选择。例如,在金融领域,Flink 可以用于实时监测交易事件,防范欺诈行为。
3. 数据管道与 ETL Flink 可以作为数据管道和 ETL(提取、转换、加载)工具,将数据从一个系统传输和转换到另一个系统。它支持多种数据源和数据格式,能够灵活地进行数据集成和转换。例如,企业可以使用 Flink 将数据从传统的数据库实时同步到数据仓库或数据湖中,为后续的数据分析和挖掘提供支持。
4. AI 与机器学习 Flink 可用于实时模型推理、特征工程,如自动驾驶中的实时路况预测。Flink 2.0 新增原生 AI 算子,支持流式数据与 TensorFlow/PyTorch 模型无缝对接。
Flink 2.0 的核心革新 作为自 2016 年 1.0 版本以来的最大更新,Flink 2.0 在架构、性能与生态融合上实现突破,引领实时计算进入新纪元:
1. 分离式状态管理 Flink 2.0 引入了分离式状态存储与管理,利用分布式文件系统(DFS)作为主要存储介质。这种架构上的创新解决了云原生环境带来的关键挑战,如容器化环境中本地磁盘的限制、Compaction 导致的计算资源尖峰、大状态作业的快速重缩放以及轻量级快速检查点的实现。分离式状态管理使得 Flink 在云原生环境中更高效地利用资源,同时保持高性能和低延迟。
2. 物化表的引入和改进 物化表(Materialized Table)是 Flink 2.0 中的一个重要特性,它允许用户通过单个数据处理流程同时管理实时数据和历史数据。物化表支持表结构和查询语句的更新,无需重新处理历史数据即可无缝迭代业务逻辑。此外,Flink 2.0 还增强了物化表的生产级可操作性,如对 Kubernetes 和 Yarn 的支持,以及与 Apache Paimon 的深度集成,为用户提供更便捷的开发和管理体验。
3. 自适应批处理执行 Flink 2.0 在批处理执行方面进行了优化,引入了自适应 Broadcast Join 和自动优化数据倾斜的 Join 等新功能。这些优化能够根据运行时信息动态调整执行计划,提高批处理性能。在 10TB TPC-DS 数据集上的基准测试显示,Flink 2.0 相比之前版本有显著的性能提升。
4. 流式湖仓架构的强化 Flink 2.0 与 Apache Paimon 的深度集成强化了流式湖仓架构。这一架构使得 Flink 成为实时数据湖应用场景的领先解决方案,支持嵌套 projection 下推、Lookup Join 性能提升以及通过 Flink SQL 轻松执行 Paimon 的维护性操作。
5. AI 原生支持 随着人工智能和大语言模型的兴起,Flink 2.0 在性能、资源效率和易用性方面的进步使其成为人工智能工作流的强大基础。Flink CDC 3.3 引入了动态调用人工智能模型的能力,而 Flink SQL 也为 AI 模型引入了专门的语法,方便用户在 SQL 语句中调用人工智能模型,实现复杂数据处理工作流与人工智能模型的无缝集成。
未来展望 Flink 2.0 的发布不仅是技术升级,更是实时计算范式的重新定义。随着 AI、物联网、多模态数据的爆发,Flink 的存算分离与湖仓一体架构将推动企业从“事后分析”转向“即时决策”。对于开发者,建议尽早学习 Flink 2.0 的新 API 与生态工具(如 Fluss 流存储引擎),还需注意 Flink 2.0 与 1.0 不兼容之处。对于数据架构师来说,Flink 2.0 提供了一个更强大、更灵活的平台,助力企业在实时数据处理领域实现更大的价值。
相关阅读 【白皮书】基于 TiDB + Flink 的实时数仓最佳实践
在这本白皮书中,你将学习到:
1. HTAP 架构的实战应用
如何通过 TiDB 的 HTAP(混合事务/分析处理)能力,在单一平台上同时支持高并发 OLTP 事务与复杂 OLAP 分析,打破传统数仓的隔阂。
深入理解 TiDB 的行列混合存储(TiKV + TiFlash)设计,优化实时查询性能。
2. Flink 实时数据处理与 TiDB 无缝集成
利用 Flink CDC 实现 MySQL/TiDB 数据的实时捕获与同步,构建端到端实时数据管道。
通过 Flink-TiDB Connector 实现流批一体数据处理,将实时计算结果高效写入 TiDB。
3. 企业级实时数仓架构设计
从传统 Lambda 架构向实时数仓演进,简化技术栈并降低运维复杂度。
结合 TiSpark 与 Flink 实现 T+0 实时分析,提升数据时效性与业务决策效率。
4. 典型场景的优化实践
大规模 Join 查询的性能调优、Flink 状态管理与 TiDB 分布式事务的协同设计。
TiDB 与 BI 工具(如 Tableau、Grafana)的深度集成,快速响应多维分析需求。
点击 阅读原文 ,免费下载完整版《基于 TiDB 与 Flink 的实时数仓最佳实践》白皮书。
Have a nice day ~ ☕
🌻 往期精彩 ▼
-- / END / --
👉 这里可以找到我
👉 这里有得聊
如果对国产基础软件(操作系统、数据库、中间件)感兴趣,可以加群一起聊聊。 关注微信公众号:少安事务所,后台回复[群],即可看到入口。
如果这篇文章为你带来了灵感或启发,请帮忙『 三连 』吧,感谢!ღ( ´・ᴗ・` )~