前言
本篇文章,是一篇实战后续篇,是基于之前我发了一篇关于如何构建高并发系统文章的延伸: 高并发系统的艺术:如何在流量洪峰中游刃有余
而这篇文章,从实践出发,解决一个真实场景下的高并发问题:秒杀场景下的系统库存扣减问题。
随着互联网业务的不断发展,选择在网上购物的人群不断增加,这种情况下,会衍生出一些促销活动,类似抢购场景或者热销热卖场景,在高峰时段的下单数量会非常大,也意味着对数据库中畅销商品的库存操作十分频繁,需要频繁查库存和更新库存。这属于高读写场景,比起单独的并发读和并发写来说,业务场景更复杂一些。那么这种高并发为了保证库存数据一致性,一般会在数据库更新时进行加锁操作,以保证系统不会发生超卖情况。
我们应该如何应对呢?大家可以根据我之前那篇文章中的思维导图,跟随我的思路,一起来看如何解决当前场景下的高并发问题。
小试牛刀
面对库存扣减的场景,我们第一个考虑到是数据一致性问题,因为超卖会对我们的履约和客户信誉造成影响。所以一般情况下,在数据库更新时进行加锁操作,以保证系统不会发生超卖情况。所以更多方案是提高数据库性能方法,比如增加硬件性能,优化乐观锁,提升锁效率,优化SQL性能等。对于一些大型系统,也衍生出一些基于分片的库存方案,通过分库分表增加并发吞吐量。
当然那这样不够,因为MySQL数据库的读写的并发上线能力是有限的,我们还是需要再进一步优化我们的方案。这里就要参考之前我写的那篇文章中的思维导论了,这里常见解决方案就是,引入缓存机制。
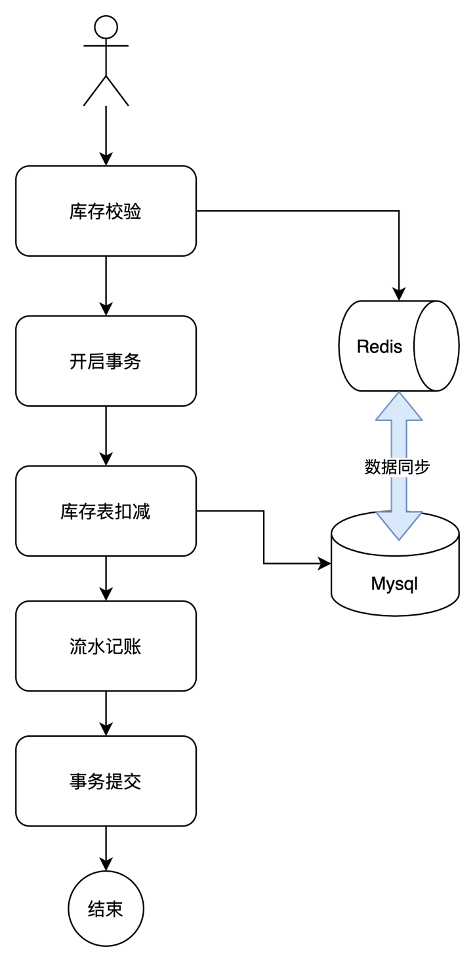
如下图所示,我们把读请求进行缓存,每次库存校验时,我们引入redis缓存,读请求通过缓存,增加接口性能,然后库存扣减时,在进行缓存同步。
但这种方式存在很大问题: 所有请求都会在这里等待锁,获取锁有去扣减库存。在并发量不高的情况下可以使用,但是一旦并发量大了就会有大量请求阻塞在这里,导致请求超时,进而整个系统雪崩;而且会频繁的去访问数据库,大量占用数据库资源,所以在并发高的情况下这种方式不适用。同时这个方案还会存在mysq和redis的数据同步不一致的情况,导致高并发情况下,出现超卖。
所以这种方案虽然简单,但是无法满足高并发场景,我们必须得pass。
循序渐进
为此,我们可以进行一次优化,通过架构维度进行调整。
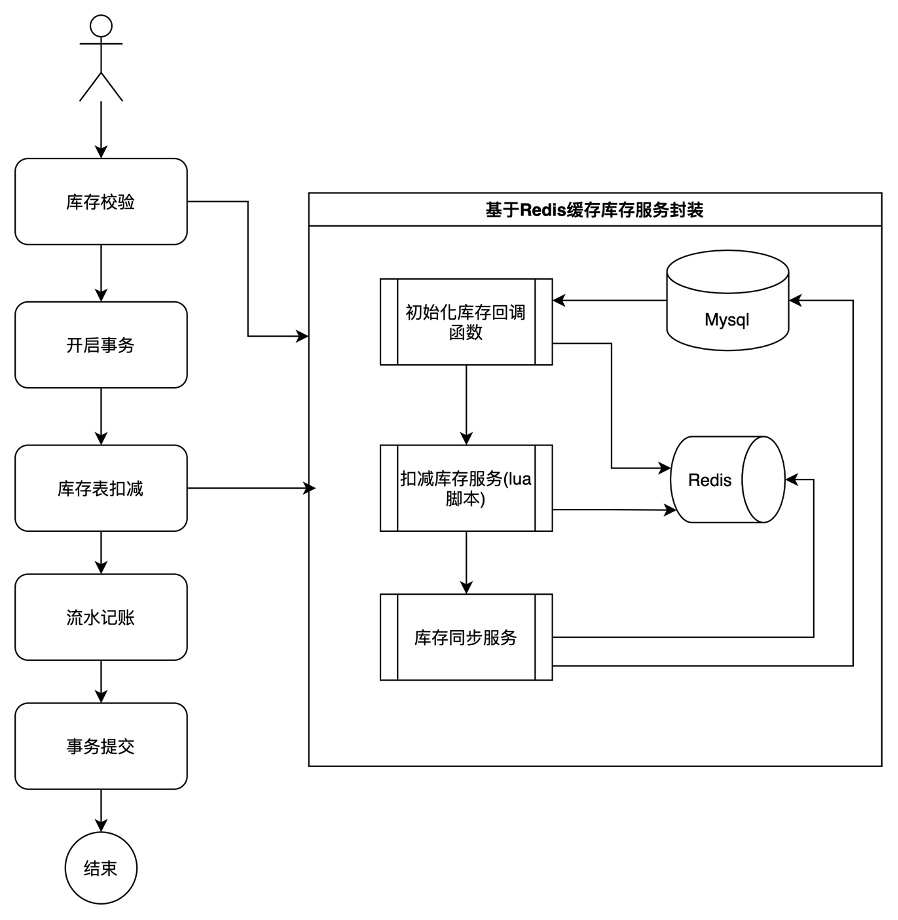
在这个方案中,我们将库存操作封装成一个单独模块,这个方案的优化点在于,所有库存的查询和扣减都围绕redis进行。当发生库存扣减操作时,会直接更新redis,同时采用异步流程,更新MySQL数据库。这样以来,我们的性能会比直接访问MySQL数据库高效不少,并发能力会有不少提升。
流程如下:
但这个方案依然有缺陷,它的点在于redis的单点性能问题。该方案的最大并发性能取决于redis的单点处理能力。而如果想要进一步提升并发能力,该方案不具备水平扩展能力。那么,这个方案,依然不是我们最优的选择。
大显身手
那么接下来,我们需要考虑的是如何可以实现我们业务系统并发能力的水平扩展能力。当然这里也不是凭空来想,我们可以思考一下,业内成熟的一些中间件是如何实现高并发的,这里我们可以两个我们常见的框架:kafka和elasticsearch。
上述我们常见的两个中间件框架,都以可以水平能力扩展著称。那么仔细思考一下他们的技术架构不难发现,他们的核心其实都是采用了一种所谓的分片实现的。那么问题来了,我们的库存扣减,能不能实现分片呢?或者换一个思路思考这个问题:我们的库存逻辑是否可以转化为分布式库存进行存储和扩展呢?
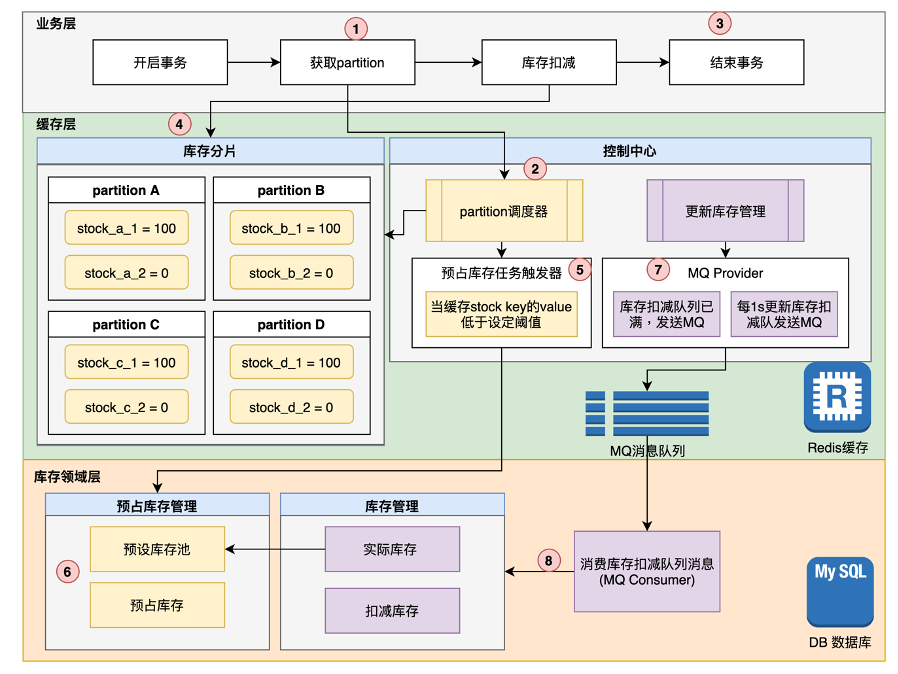
有了以上的思路,我们就可以开始构建我们的架构方案了。接下来,我先把架构图贴出来:
在这个架构方案中,是以Redis缓存为实现基础,结合Mysql数据存储,通过一套控制机制,保证库存的分布式管理。在该方案中,有一些特定的业务模块单元需要说明。
1. partition
熟悉kafka的人对partition一定不陌生。在本架构方案之中,该业务架构中的partition的概念是一组基于redis来实现的库存分片,分别存储一部分库存大小。
在一个partition中,会存有一定量的预占库存量,当有请求服务进行库存扣减时,只需要选择其中一个partition即可,这样以来,就可以减轻单节点的压力,同时可以基于redis集群的可扩展性,实现partition的水平扩展。
分布式系统常见的一个问题就是数据倾斜问题,因为严重的数据倾斜,会让我们分布式方案瞬间瓦解,导致单点承担高并发。那么该方案下的数据倾斜问题如何解决呢?
最终,我想到的解决方案类似养宠物狗时买的那种定时投喂仪器,每天通过定时定量投喂,来保证宠物狗不会被饿到或者吃撑。
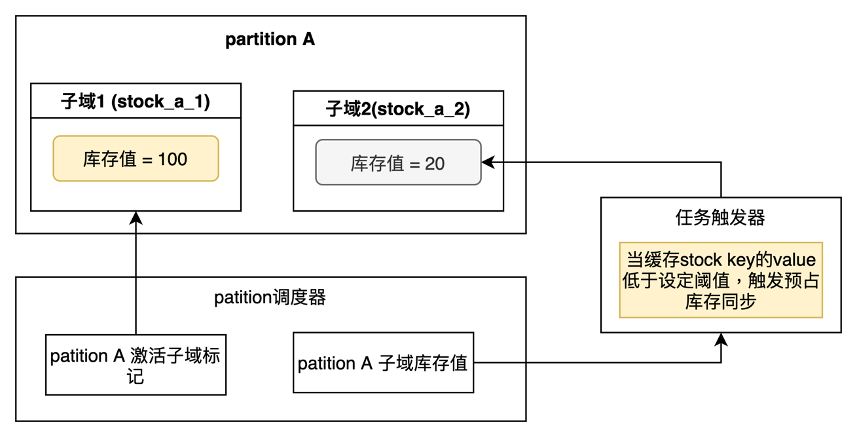
如果最初把所有库存全部平均到每个partition中,当有多个大库存扣减打到一个partition上时,会造成该partition上出现库存被消耗光,而失去后续提供库存扣减能力。为了解决这个问题,我在partition中采取的是动态库存注入和子域隔离的方案。具体方案如下图:
每个partition会有两个子域,调度器中会记录每个partition当前激活的子域,每次库存扣减,会扣减激活的子域中的库存值。而当激活的子域库存值低于设定阈值是,会切换子域,冷却当前子域,激活另一个子域。被冷却的子域会触发任务触发器,实现预占库存的数据同步。
子域中会存储一定额度的库存值,不会存储很大的量,这样就可以保证动态的预占库存实现,从而解决库存倾斜的问题。
当然为了更好的管理partition,我们需要单独开发一个partition调度器模块,来负责管理管理众多partition资源,那么这个调度器的具体功能包括:
1. 调度器中有一个注册表,会记录 Partition的key值,外部服务获取partition key是需要通过调度器获取,调度器会记录每个partition的库存余量和partition和子域信息。
2. 当partition无法再获取预占库存,且库存耗尽时,调度器会从注册表中摘除该partition信息。
3. 调度器可以采用随机或者轮训的方式获取partition,同时每次也会校验partition剩余库存是否满足业务扣减数量,如果剩余库存小于业务扣减数量,将会跳过该partition节点。
2. 异步更新库存
第二个核心模块就是更新库存管理了,这块你可以理解为异步流程机制,通过异步化操作,来减轻系统的高并发对数据库的冲击。
更新库存会有一个明细表,记录每个partition库存扣减信息,明细表会有一个同步状态,有两种情况可以出发库存同步MQ消息:
第一. 当每个partition中的明细数据条数超过设定阈值,会自动触发一次MQ消息。
第二. 每间隔额定设定时间(默认设置1秒), 会触发一次当前时间段内每个partition产生的库存扣减明细信息,然后发送一次MQ消息。
两中触发方案相互独立,互不影响,通过同步状态和明细ID实现幂等。
3. 预占库存管理和库存管理
接下来就是关于库存的底层数据结构设计了。这里会引入一个在电商行业很共识的概念:预占库存。
在库存领域层中,库存分为预占库存和库存两个模块,这里面的库存关系实例如下:
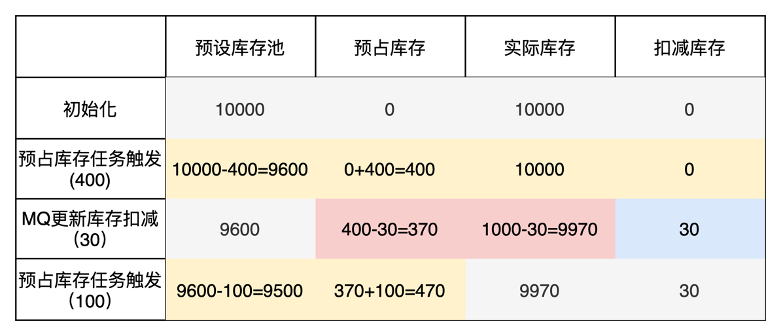
假设当前商品的库存值为10000件,当前partition触发一次预占库存任务,领取400件, 然后假设此时收到MQ库存消费更新消息,更新30件。随后partition又触发一次预占库存任务,零陵区了100件。库存变化如下图所示:
其中 实际库存= 预设库存池 + 预占库存。
每次预占库存任务触发,会从预设库存池中扣减,如果预占库存池清空,则partition就无法在获取预占库存,调度器会将它从注册表中摘除。
而每次MQ更新库存消息,会更新实际库存量,同时对预占库存和扣减库存值进行修改,这个操作具有事务性。
总结
通过这次的案例分析,我们其实是通过方法论结合实际业务场景的方式出发,设计了我们的系统架构。剥离业务场景,其实本质就是通过缓存和异步流程来实现系统的高并发,同时让系统具备拥有水平扩展的能力。但这个方法论在与实际业务结合时,还是会有很多很多需要思考和细化的点,比如分布式思想的使用,比如预占库存的逻辑设计等等。