引言
当向 PostgreSQL 发送查询时,查询通常会经过几个处理阶段,并最终返回结果。这些阶段如下所示:
- 解析(Parse)
- 分析(Analyze)
- 重写(Rewrite)
- 计划(Plan)
- 执行(Execute)
在本文中,我们将仅关注"计划"阶段或"规划器(Planner)"模块,因为这是最有趣或最复杂的阶段。我将分享我对规划器模块的理解,并探讨它如何处理一个简单的顺序扫描。
规划器的目标非常简单:从可用路径中识别出最快的"路径",并根据此路径制定一个"计划",以便"执行器"模块在下一阶段执行它。然而,识别最快的"路径"就是造成规划器复杂的原因。
注:本文基于 PostgreSQL 16 撰写。
一切从哪里开始
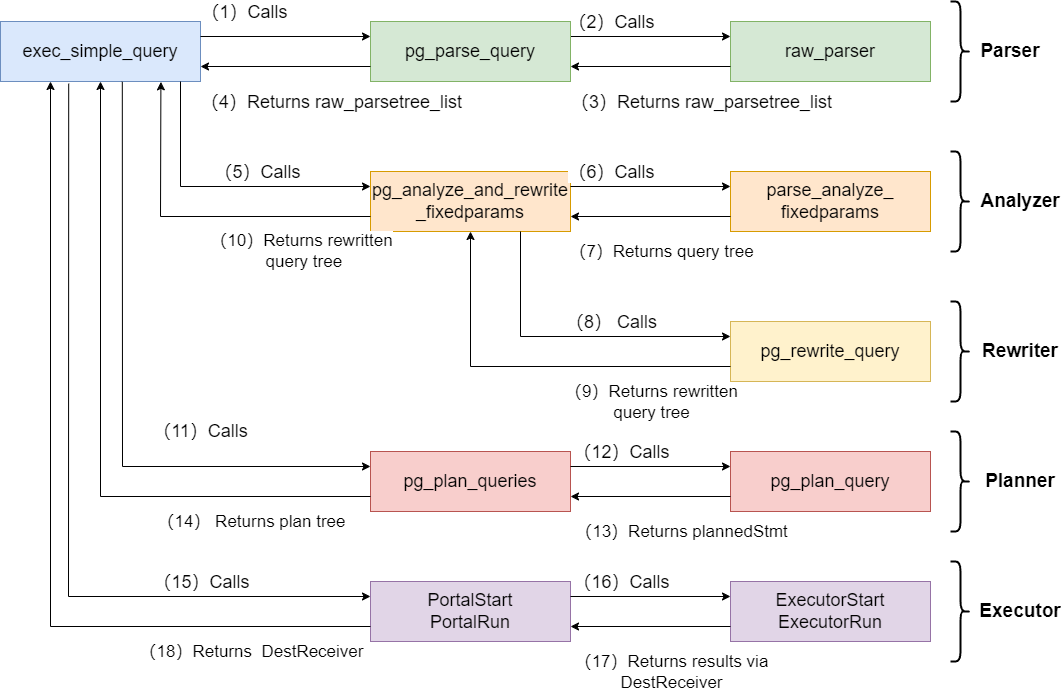
在 postgres.c 中的 exec_simple_query() 函数是查询处理阶段的起点。我们将关注它进入 pg_plan_query() 后发生的事情。下面我只会提到它会调用的重要函数。
![file]()
在 pg_plan_query() 背后发生了什么?
实际上,发生了很多事情,例如:
- 识别子查询、分区表、外部表、连接等
- 通过表访问方法估算所有涉及的表的大小
- 识别完成查询的所有可能路径
- 顺序扫描、索引扫描、TID 扫描、并行工作线程等
- 在所有路径中,找到最佳路径,通常是成本最低的
- 根据此路径制定计划
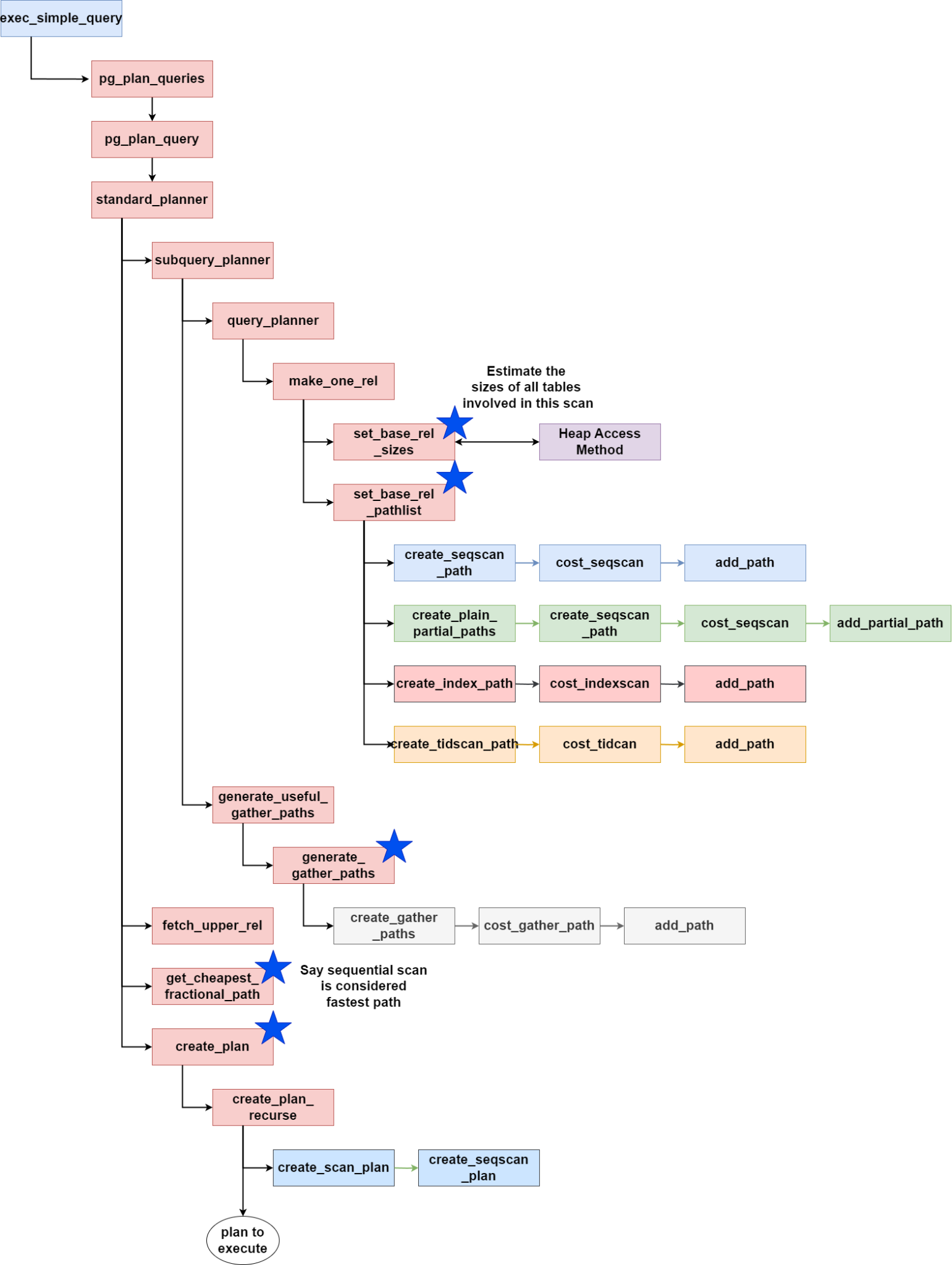
以一个简单的 SELECT 查询为例,该查询只涉及一个表,没有连接或子查询,下面是大致的调用栈:
![file]()
这个调用栈图进行了极简化,但展示了规划器模块的几个关键元素。带有蓝色星号的块将在下一节中详细解释。
set_base_rel_sizes()
顾名思义,这是估算所有关系(表、视图、索引等)大小的主要入口。大小包括估算的行数(元组)和列数。通常需要通过"堆访问方法"来获取这些信息,这样它就可以访问"缓冲区管理器"和"存储管理器",以提供对大小的估算。
总大小将是所有相关表的大小。这对后续的"成本估算"阶段非常重要。
set_base_rel_pathlist()
对于一个简单表的顺序扫描,程序将在此处结束。对于更复杂的查询,将有不同的路径构建技术。有关其他路径构建技术,请参阅 allpaths.c 中的 set_rel_pathlist()。
当前,默认添加了 4 种扫描路径:
- 顺序扫描(Sequential Scan)
- 部分顺序扫描(Partial Sequential Scan)
- 由于要通过"聚合"节点(在下一阶段处理)进行聚合,因此被标记为"部分"。这本质上意味着并行顺序扫描。
- 仅在关系或查询被认为是并行安全时添加
- 索引扫描(Index Scan)
- TID 扫描(TID Scan)
- 如果查询包含范围限制子句(如
WHERE ctid > '(1,30)' AND ctid < '(30,5)'),则可以选择 TID 扫描
所有这些路径都涉及一些成本,通过元组或页面的数量以及每个元组/页面的成本因子来估算,成本因子配置如下:
# Planner Cost Constants
- `seq_page_cost` = 1.0 # 任意尺度
- `random_page_cost` = 4.0 # 与上述相同的尺度
- `cpu_tuple_cost` = 0.01 # 与上述相同的尺度
- `cpu_index_tuple_cost` = 0.005 # 与上述相同的尺度
- `cpu_operator_cost` = 0.0025 # 与上述相同的尺度
- `parallel_setup_cost` = 1000.0 # 与上述相同的尺度
- `parallel_tuple_cost` = 0.1 # 与上述相同的尺度
不同的路径方法有不同的成本计算,它们会调用以下方法来计算"启动成本"和"运行成本":
cost_seqscan()cost_indexscan()cost_tidscan()
你可以通过调整这些成本来影响规划器在选择最理想路径时的决策。例如,如果你希望规划器更多地使用并行扫描,可以考虑降低并行扫描元组的成本,例如将 parallel_tuple_cost 设置为更小的值,如 0.001。
add_path 被调用来将路径添加到潜在路径列表中,但请记住,规划器的路径构建机制具有驱逐机制。这意味着如果我们打算添加一个明显优于当前路径的新路径,规划器可能会丢弃所有现有路径,接受新的路径。类似地,如果要添加的路径明显较差,它将不会被添加。
如果规划器认为并行顺序扫描是安全的,则会调用 add_partial_path。这种顺序扫描被称为"部分"扫描,因为它需要收集和聚合数据以形成最终结果,因此会产生额外的成本,那么就会造成并行性并不总是理想的结果。这里有个经验法则:
- 如果 PostgreSQL 必须扫描大量数据,但我们只需要其中一小部分,使用并行扫描可以提高效率;
- 如果 PostgreSQL 必须扫描大量数据,而且大部分数据都是我们需要的,并行扫描可能会更慢。
generate_gather_paths
如果已经添加了某些部分路径(通常是顺序扫描子路径),则会调用该函数。这个例程添加了一种新的路径类型"gather",它包含一个子路径"顺序扫描"。聚合路径需要考虑每个子路径的成本,以及从并行工作线程获取元组并聚合数据的成本。
get_cheapest_fractional_path 和 create_plan
一旦所有潜在路径候选项被添加后,调用这个函数来选择最便宜的路径,即具有最低总成本的路径。然后,这个选择的路径将被传递给 create_plan,在这里路径(及其子路径,如果有的话)将被递归创建,并形成最终的计划结构,供执行器理解和执行。
审查计划
我们可以在查询前使用 EXPLAIN ANALYZE 来检查规划器选择的最便宜计划及其成本细节。以下示例是一个查询计划,它包含一个名为"gather"的主计划,里面有一个名为"顺序扫描"的部分计划,并且有 2 个工作线程。你可以通过箭头(->)来判断哪个是子路径。
postgres=# explain analyze select * from test where a > 500000 and a <600000;
QUERY PLAN
------------------------------------------------------------
Gather (cost=1000.00..329718.40 rows=112390 width=36) (actual time=62.362..5106.295 rows=99999 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on test (cost=0.00..317479.40 rows=46829 width=36) (actual time=58.020..3416.544 rows=33333 loops=3)
Filter: ((a > 500000) AND (a < 600000))
Rows Removed by Filter: 13300000
Planning Time: 0.489 ms
Execution Time: 5110.030 ms
(8 rows)
如果规划器选择顺序扫描主路径且没有任何子路径,查询计划将如下所示:
postgres=# explain analyze select * from test where a > 500000;
QUERY PLAN
------------------------------------------------------------
Seq Scan on test (cost=0.00..676994.40 rows=39571047 width=6) (actual time=0.011..7852.896 rows=39500000 loops=1)
Filter: (a > 500000)
Rows Removed by Filter: 500000
Planning Time: 0.115 ms
Execution Time: 9318.773 ms
(5 rows)
总结
PostgreSQL 规划器的内部机制较为复杂,但通过本文解析,您应已掌握其核心运行逻辑。若您需要针对特定场景定制优化查询性能(例如调整代价模型参数)或扩展功能(如引入新的扫描路径策略),至少能基于现有原理明确切入点。
本文由博客一文多发平台 OpenWrite 发布!