2025年3月7日,Google Developers Blog 宣布了一款全新的实验性 Gemini 嵌入文本模型(gemini-embedding-exp-03-07),现已通过 Gemini API 向全球开发者开放试用。此次发布标志着 Google 在文本嵌入技术领域取得了显著进步,为众多应用场景带来了前所未有的语义理解和性能提升。
卓越的模型表现
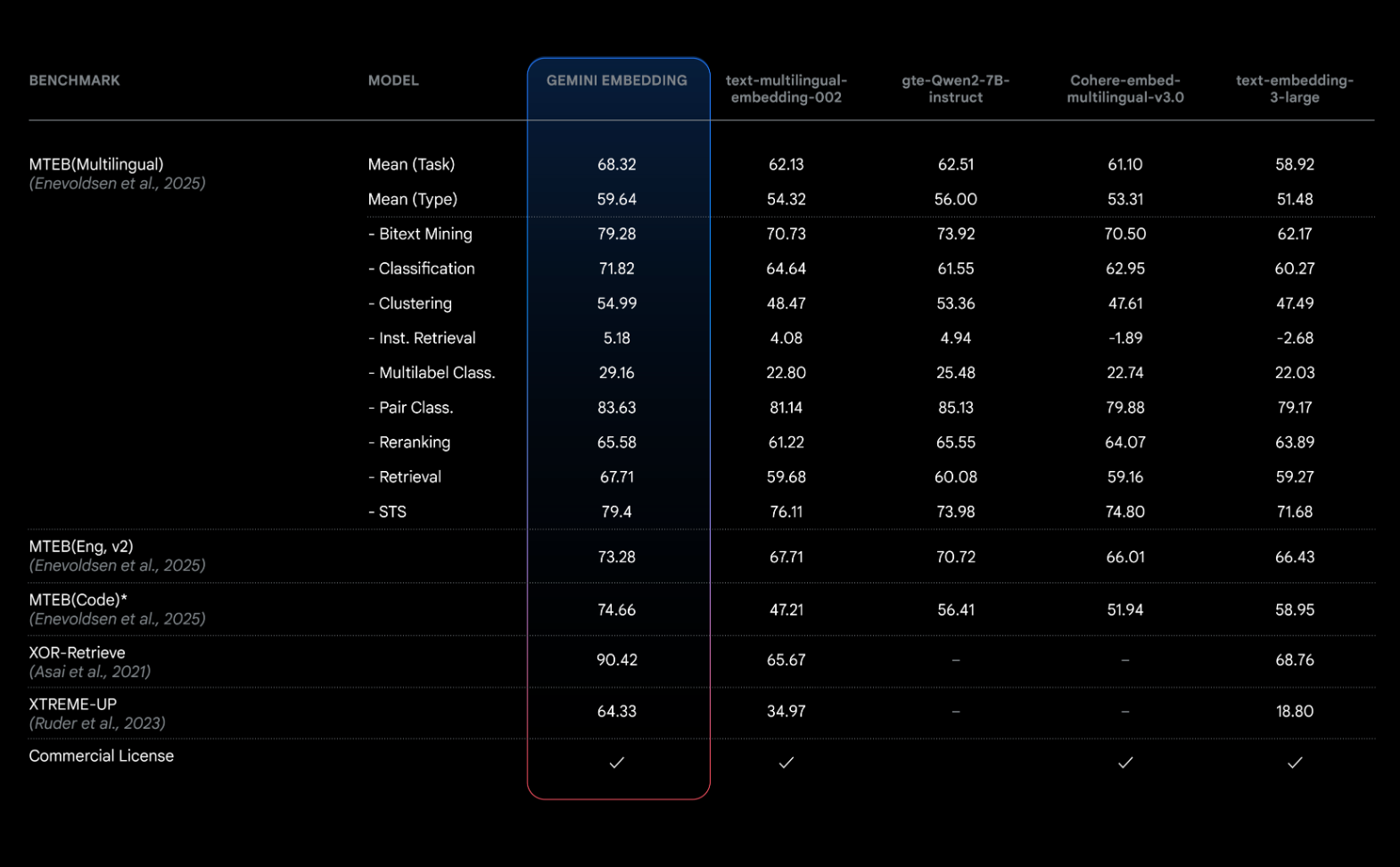
这款基于 Gemini 模型本身训练的嵌入模型,凭借其对语言和语境的深刻把握,已在 Massive Text Embedding Benchmark(MTEB)多语言排行榜上以平均得分68.32的成绩遥遥领先,超过竞争对手5.81分。其出色的表现不仅证明了模型的高通用性,也使其在金融、科学、法律、搜索等多个领域具备广泛的应用潜力。
![]()
关键技术与新特性
- 更长的输入支持:模型支持高达8K个 token 的输入,这一提升允许开发者处理更大规模的文本数据,无论是长篇文章、代码片段还是复杂的文档,都能得到有效嵌入。
- 高维输出:输出维度达到3000维,相比以往的模型,嵌入向量更高维,能捕捉到更细致的语义信息。
- Matryoshka Representation Learning (MRL):该技术允许用户根据实际存储需求,对高维嵌入向量进行截断,灵活调整数据表示的精度与存储成本。
- 扩展的语言支持:目前模型支持的语言数量已扩展至100多种,显著提升了多语言文本处理能力,为全球化应用提供坚实支持。
- 统一模型架构:新模型在质量上超越了之前的多任务、多语言以及代码专用模型,成为了一个更为通用且高效的文本嵌入解决方案。
开发者早期试用与未来展望
目前,该 Gemini 嵌入模型仍处于实验阶段,容量有限,但 Google 已经通过 Gemini API 的 embed_content 接口开放了早期试用通道。开发者可以通过简单的 API 调用,快速实现智能检索、文本分类、推荐系统、文档聚类等多种应用场景。示例代码如下:
from google import genai
client = genai.Client(api_key="GEMINI_API_KEY")
result = client.models.embed_content(
model="gemini-embedding-exp-03-07",
contents="How does alphafold work?",
)
print(result.embeddings)
此外,在 Vertex AI 平台上,该模型以 “text-embedding-large-exp-03-07” 名称进行部署。未来,随着实验版向稳定版本过渡,Google 将持续优化这一技术,力求在性能和可用性上实现更大突破。
Google 团队诚邀开发者通过反馈帮助改进产品,共同推动文本嵌入技术的发展,为人工智能应用注入新的活力。