引言
因高计算成本和复杂性,在例如移动设备和边缘计算场景等资源有限的环境中,限制了大语言模型的普及。如何在保留模型性能的同时提高计算效率并降低部署成本,已成为研究和工业界必须面对的关键挑战。
在此背景下,我们正式推出基于Qwen2.5的轻量化大模型系列DistilQwen2.5。该模型通过创新的双层蒸馏框架实现突破,基于数据优化策略重构指令数据集强化模型理解能力,并且采用参数融合技术实现细粒度知识迁移。实验表明,DistilQwen2.5 在多项基准测试中性能超越原模型,同时显著降低计算资源消耗。
![]()
DistilQwen2.5 蒸馏模型的 Checkpoint 已在Hugging Face及Model Scope全面开源。本文将介绍 DistilQwen2.5 的蒸馏算法、效果评测,以及 DistilQwen2.5 模型在阿里云人工智能平台 PAI 上的使用方法,并提供在各开源社区的下载使用教程。
DistilQwen2.5中的知识蒸馏技术
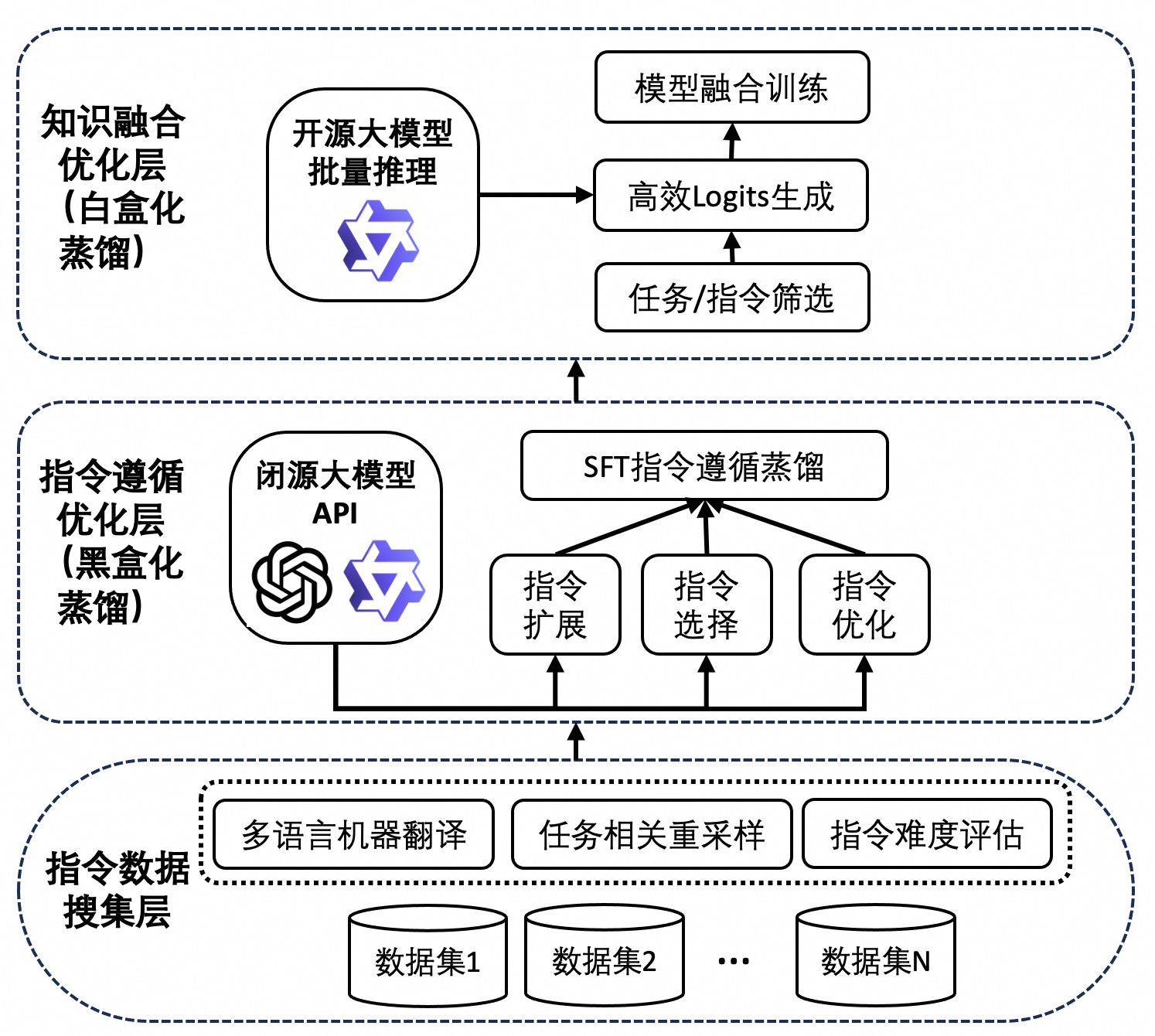
本节中,主要描述DistilQwen2.5模型训练中使用的黑盒化和白盒化的知识蒸馏技术。其中,DistilQwen2.5模型蒸馏的算法框架如下图所示。
![]()
指令数据搜集层
DistilQwen2.5模型蒸馏算法的首要步骤是指令数据收集层,旨在搜集大量高质量指令数据,以供后续教师模型使用。为了确保数据的多样性和高效性,整合了多个来源的数据集,包括开源数据集Magpie、Openhermes和Mammoth 2等。此外,还引入了大量私有合成数据集,以丰富指令样本的多样性。为有效整合数据源,确保指令语言主要涵盖中英文,同时对指令进行了难度打分和任务相关的重新抽样。
首先,在许多应用场景中,模型需要能够跨语言工作。为应对中文数据相对不足的挑战,利用Qwen-max进行了数据扩展。通过设计特定的Prompt,让Qwen-max生成了内容不同但任务类型相同的中英文指令,从而平衡了中英文数据的比例。
其次,任务多样性是实现模型全面能力的关键环节。借鉴WizardLM中对大语言模型能力的评估维度,在DistilQwen2模型蒸馏中继续使用之前的方法,定义了33种任务类型,涵盖广泛的应用场景。我们创建了一个包含3万条任务的分类数据集,并基于Deberta v3训练了任务分类器。该分类器在测试集上的准确性与ChatGPT相当,使得指令数据标注具备高度的可靠性和准确性。通过如此精细的任务标签,能够更好地控制数据集中不同任务类型的分布,确保模型在训练过程中获得全面和深入的能力。
此外,在评估指令数据的难易程度时,采用了LLM-as-a-Judge的范式。利用教师模型对指令执行的准确性、相关性、帮助性和详细程度进行评分,这为模型提供了一种客观的指令难度评估机制。具体而言,我们引入了一种名为模型拟合难度分数(MFD Score)的指标来衡量每条指令在蒸馏训练中的价值。MFD分数是根据学生模型得分与教师模型得分之间的差值计算得出的。如果某条指令的MFD分数较高,则说明该指令对蒸馏训练更具价值,而低难度的指令则可以从训练集中移除。
指令遵循优化层(黑盒化蒸馏)
黑盒化蒸馏主要依赖于教师模型的输出,而非其内部表征。我们选择采用黑盒化蒸馏算法的原因有两个:首先,这种算法的训练速度比白盒化蒸馏更快,有助于节省训练时间和计算资源;其次,黑盒化蒸馏适用于开源和闭源的大型模型。在指令遵循优化层中,我们并不直接通过蒸馏微调的方法来优化学生模型,而是利用教师大模型,首先引入一种Multi-Agent模式,以对指令数据进行大幅度提升和优化。
-
指令扩展:在这一过程中,教师大模型充当指令扩展的Agent,生成与输入指令相似的新指令。在扩展指令时,我们要求该Agent始终保持原始任务的自然语言处理类别不变,以避免产生不必要的幻觉。例如,当输入的指令为“简要概述牛顿第一运动定律”时,输出可以是“解释开普勒第三定律的含义”,而不是“介绍爱因斯坦的生平”。
-
指令选择:指令选择Agent的目标是筛选出对模型训练具有高度价值的指令,筛选标准包括信息量、实用性和泛化潜力等。这一过程不仅保证了增强数据集的质量,也有效过滤了对模型蒸馏训练帮助不大的指令数据。
-
指令改写:在经过指令扩展和选择后,指令改写Agent进一步提升数据的质量和多样性,同时保持指令意图不变。例如,将“提供气候变化经济影响的总结”改写为“解释气候变化如何影响经济”。此外,对于复杂任务如逻辑推理、数学问题和编程等,我们鼓励生成链式思维(Chain-of-Thought, CoT)输出,以进一步提升小模型的推理能力和解决问题的逻辑性。
黑盒化蒸馏过程遵循监督学习范式,以增强的指令响应对作为训练样本。学生模型能够在有限的参数量下,充分吸收和理解来自大模型的知识。这种方法不仅增强了学生模型解决任务的能力,也使其能够在多任务环境中取得更好的效果。
知识融合优化层(白盒化蒸馏)
黑盒化知识蒸馏仅依赖教师模型输出的概率最高的token,而白盒化知识蒸馏则更关注教师模型输出logits的分布,从而为学生模型提供更丰富的信息。通过模仿教师模型的logits分布,白盒化蒸馏可以更有效地传递知识,进一步提升学生模型的性能。
![]()
传统的白盒化蒸馏算法对于工业大规模数据的蒸馏场景是不可行的,原因有三个:
-
GPU内存消耗过高:如果在训练学生模型的同时进行教师模型的前向传播,所需的计算资源将显著增加。对于拥有32B或者72B参数的巨型教师模型,GPU内存甚至可能无法承受。这种情况严重限制了模型的训练效率。
-
长时间的存储和读取:对于离线生成的教师模型logits,其存储和读取通常需要占用大量的时间。尤其是当数据集非常庞大时,磁盘空间的消耗也变得难以忽视。这种高昂的存储和读取开销成为了系统瓶颈。
-
词汇表不匹配问题:教师模型和学生模型通常使用不同的词汇表,导致它们的logits张量无法直接匹配。这种不匹配阻碍了知识的准确传递,降低了蒸馏过程的有效性。
我们在教师模型的输出中观察到,前10个token的概率之和几乎为1,这表明教师模型的所有知识几乎都包含在前10个token中。因此只保存教师模型每个序列位置中概率最大的10个token的概率。由此我们构建了一个对于大模型和大数据量下可扩展的白盒化知识蒸馏系统,支持以下功能:
![]()
DistilQwen2.5模型效果评测
在本节中,从多个角度评测DistilQwen2.5蒸馏小模型的实际效果;同时,我们对使用不同规模的教师大模型进行模型融合训练的效果进行评测。
模型综合能力评测
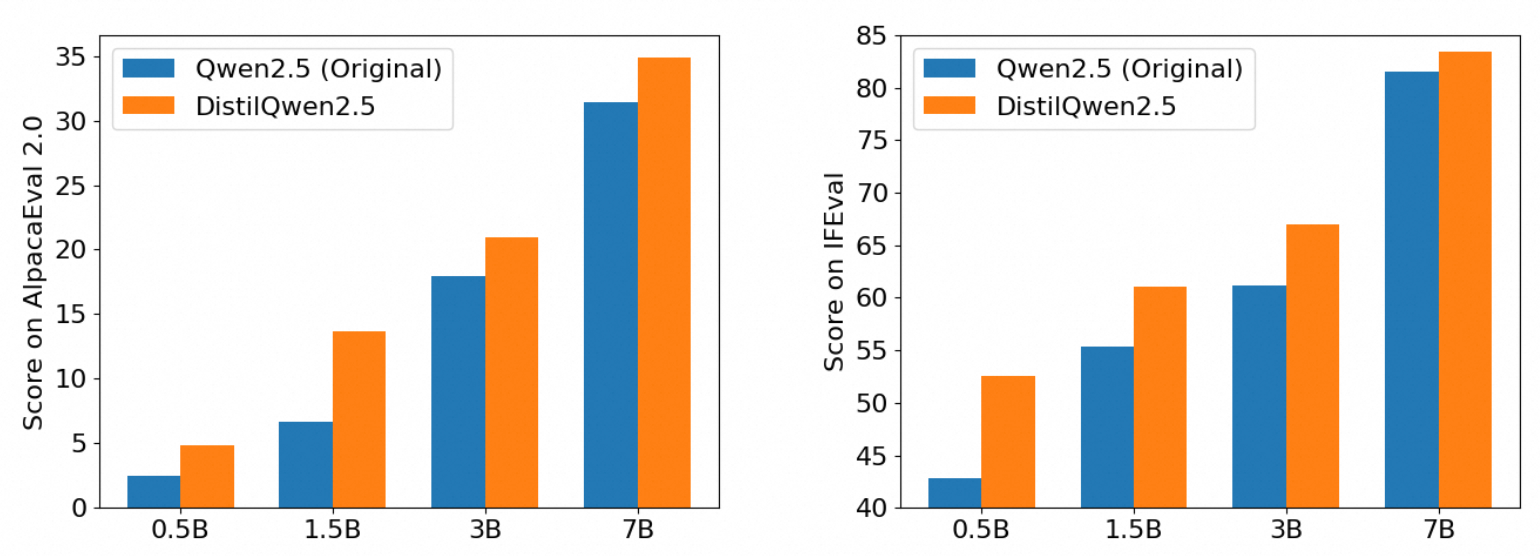
我们在多个权威指令遵循评测基准上测试了DistilQwen2.5蒸馏小模型的能力。AlpacaEval 2.0使用GPT-4作为评判员来评估生成回复的质量。特别地,AlpacaEval 2.0引入了长度控制的胜率(Length-controlled Win Rates),以避免GPT-4偏向于较长回复,从而减少评估偏差。MT-Bench是包括来自8个类别的80个任务,同样使用GPT-4作为评判标准,并提供两种不同的评估模式:多轮对话和单轮对话。IFEval专注于使用“可验证的指令”进行模型效果的评估,这使得结果更加客观。根据所使用的Prompt不同,IFEval提供了instruction-loose和strict-prompt两种评估模式。如下表所示,DistilQwen2.5在0.5B、1.5B、3B和7B四个参数量级的模型中,与原始Qwen2.5模型的效果进行了对比。可以看出,本文描述的知识蒸馏算法显著提升了现有大语言模型的指令遵循能力,并在多个评测基准上取得了一致而明显的效果提升。
模型细粒度能力评测
我们进一步使用MT-bench基准测试对DistilQwen2.5模型的各项细粒度能力进行评测,例如文本生成、代码生成、数学问题、角色扮演等,每个任务都旨在从不同的角度测试模型的能力。通过对DistilQwen2.5模型模型在MT-bench基准测试中的表现进行分析,我们可以准确量化DistilQwen2.5模型在各个方面的细粒度能力,并将其与原始模型进行比较。从实验结果可以看出,在绝大部分细粒度能力层面,DistilQwen2.5模型比原始Qwen2.5模型有明显的提升。下图给出0.5B和1.5B模型在各个细粒度能力的对比。
与其他模型能力对比
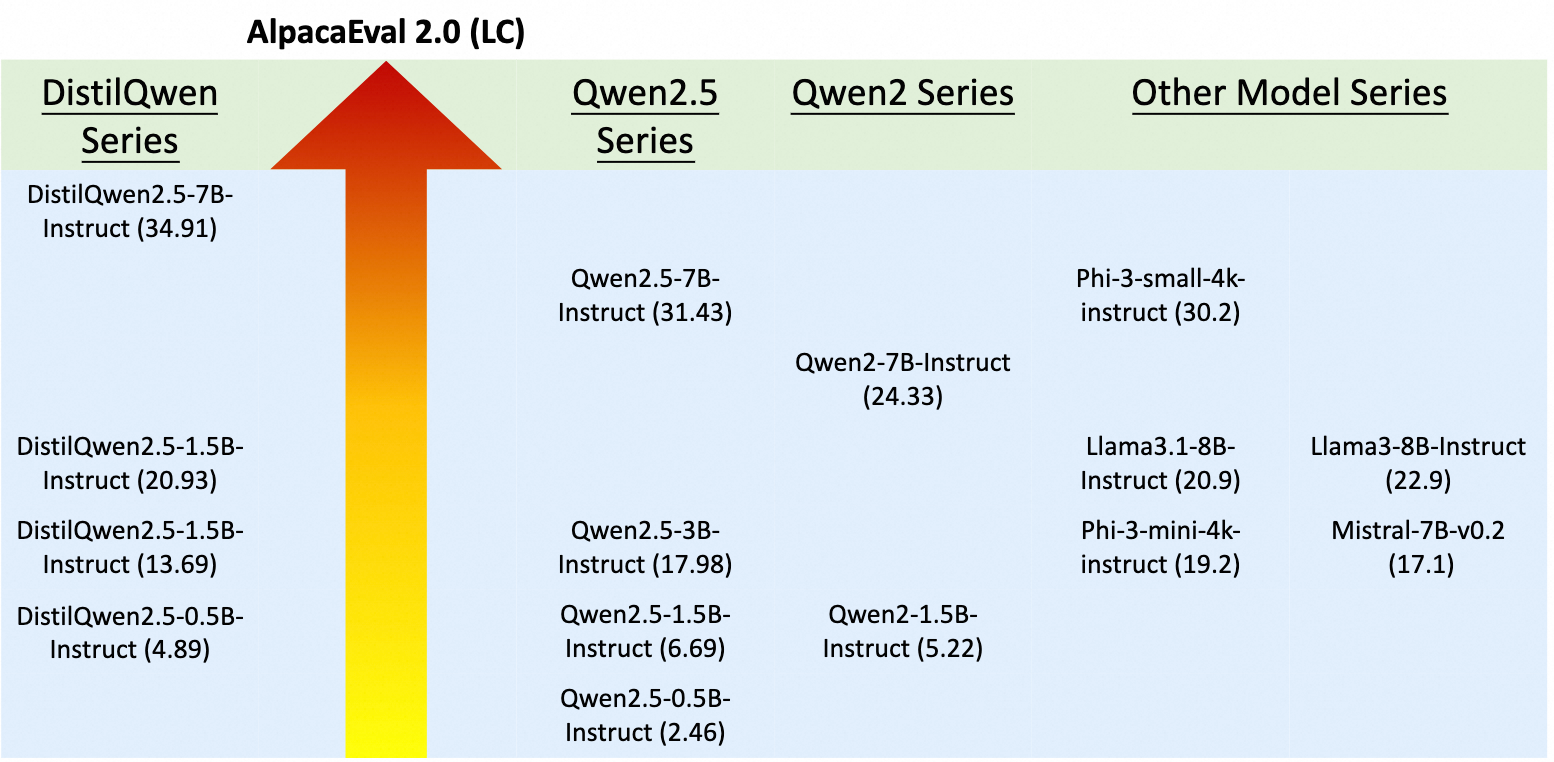
为了横向比较同期发布的不同参数规模的模型效果,下表展示了这些模型在AlpacaEval 2.0的评测结果,对于每个参数量级,从低到高进行排序。我们重点对比了Qwen2、Qwen2.5以及先前发布的DistilQwen2模型。对于英文模型,我们也横向对比Llama、Phi3、Mistral等系列模型。模型效果排序如下所示。可以看出,DistilQwen2.5系列模型对比其他各类模型,具有很高的性价比,其效果接近了参数量接近或大于其参数量两倍的模型。
![]()
模型融合实验评测
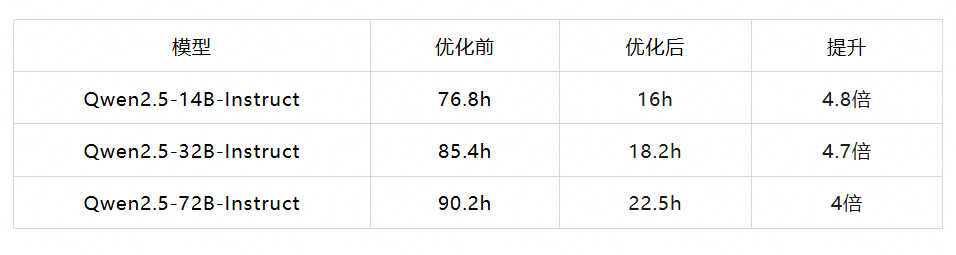
经过对大模型logtis生成速度的优化,我们对logits的推理速度提升了至少4倍,节省存储空间为原本的1/1000。使用5万条数据时,时间具体耗时如下:
![]()
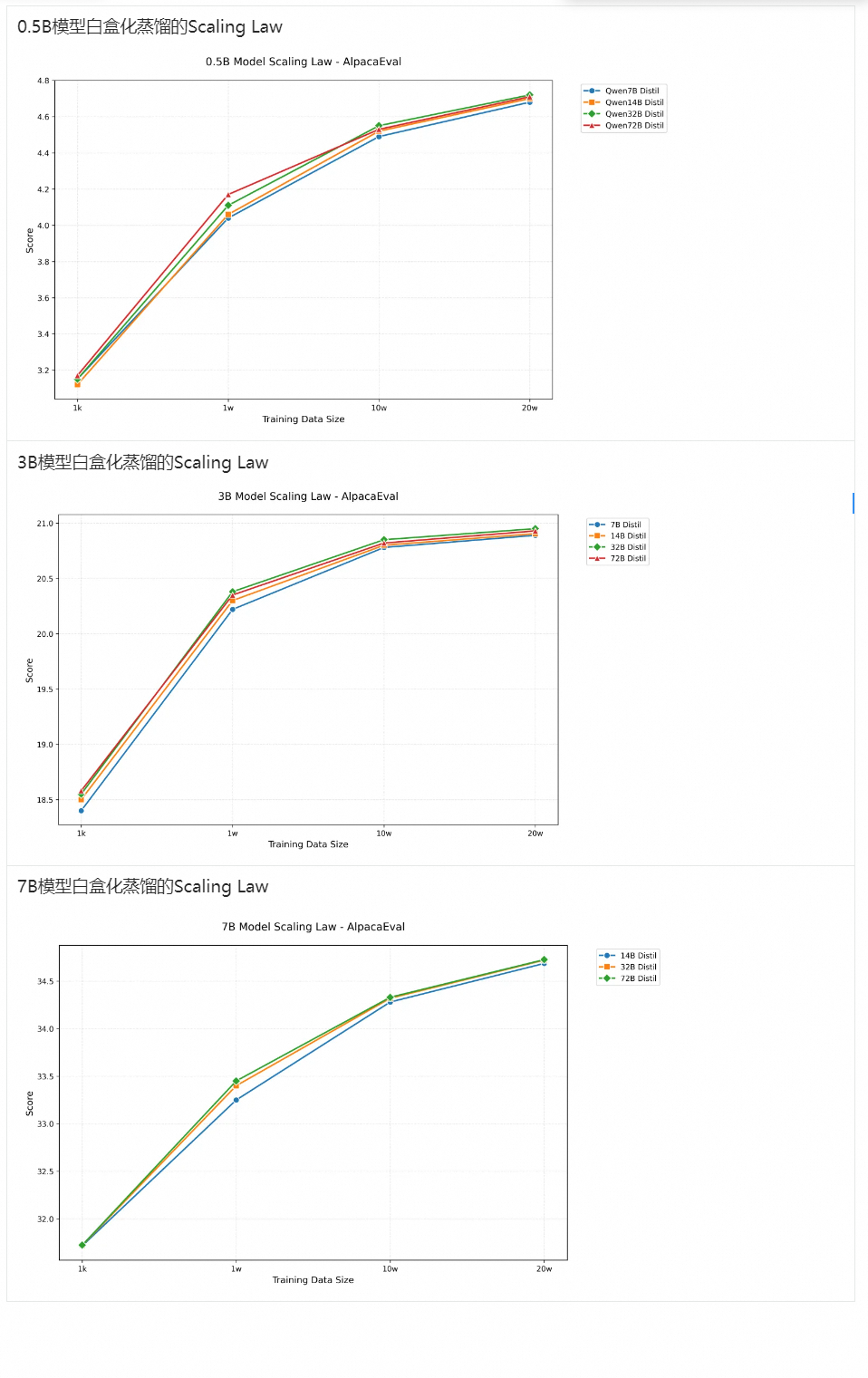
针对不同训练数据量级(1K/10K/100K/200K)下和不同教师模型(7B/14B/32B/72B)大小的蒸馏效果,我们也进行了探索,效果如下图所示,从中可以得到一些关于蒸馏数据量和教师模型参数量大小的结论:
-
数据量和模型大小都存在边际效应,随着数据量的成倍提升,效果提升减缓;随着模型规模的上升(32B/72B)并没有对比14b模型带来更明显的提升。这表明,学生模型和教师模型在参数量差距过大的情况下,对教师模型的学习能力有限。
-
在小数据量(~1K)或充分数据量(>200K)的情况下,提升教师模型规模带来的效果提升不明显。在10K-100K条数据量下,不同规模的教师模型提升较为明显。这可能是由于在小数据的场景下,学生模型对教师模型的能力还没有充分学习;而在大数据场景下随着数据量大饱和,学生模型已经能从数据中学习到充分的知识。
![]()
模型输出案例
对于同一指令,我们对比了DistilQwen2.5-7B-Instruct和GPT-4o、DeepSeek-V3、Qwen2.5-Max、Qwen2-7B-Instruct回复对比结果,特别是知识性和逻辑推理类问题。从输出结果可以看出,DistilQwen2.5-7B-Instruct的输出在一些场景上具有更好的事实正确性和逻辑推理能力。
示例一:知识性问题
![]()
示例二:知识性问题
![]()
示例三:逻辑推理类问题
![]()
模型下载和使用
DistilQwen2.5在阿里云人工智能平台PAI上的实践
以下HuggingFace transformers库为例,简要介绍如何在PAI-DSW上使用DistilQwen2.5模型。首先需要保证PAI-DSW镜像内transformers版本大于等于4.37.0,否则会在加载模型时报错:
KeyError: 'qwen2'
以DistilQwen2.5-7B-Instruct为例,我们可以使用如下代码调用模型:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "alibaba-pai/DistilQwen2.5-7B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "请给我简单介绍一下杭州西湖。"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
DistilQwen2.5在开源社区的下载
我们在HuggingFace和ModelScope上开源了我们蒸馏后的模型,分别为alibaba-pai/DistilQwen2.5-0.5B-Instruct、alibaba-pai/DistilQwen2.5-1.5B-Instruct、alibaba-pai/DistilQwen2.5-3B-Instruct和alibaba-pai/DistilQwen2.5-7B-Instruct。以HuggingFace为例,用户可以使用如下代码下载这两个模型:
from huggingface_hub import snapshot_download
model_name = "alibaba-pai/DistilQwen2.5-0.5B-Instruct"
snapshot_download(repo_id=model_name, cache_dir="./DistilQwen2.5-0.5B/")
model_name = "alibaba-pai/DistilQwen2.5-1.5B-Instruct"
snapshot_download(repo_id=model_name, cache_dir="./DistilQwen2.5-1.5B/")
model_name = "alibaba-pai/DistilQwen2.5-3B-Instruct"
snapshot_download(repo_id=model_name, cache_dir="./DistilQwen2.5-3B/")
model_name = "alibaba-pai/DistilQwen2.5-7B-Instruct"
snapshot_download(repo_id=model_name, cache_dir="./DistilQwen2.5-7B/")
数据集下载和使用
为了支持社区开发者在微调DistilQwen2.5模型时避免“灾难性遗忘”(catastrophic forgetting)现象,我们开源了部分用于模型训练的数据集。这一数据集旨在为模型微调提供坚实的基础,有助于提升模型在新任务上的适应性的同时,保持在之前任务上的性能。此外,在微调其他类似大语言模型时,也可以利用这一数据集进行指令遵循能力的增强。以下是关于数据集的信息和下载使用说明。
数据格式等相关信息
该部分数据包含了数学、代码、知识问答、指令遵循、创意生成等内容,总数据量为100K。用户可以在用自己的数据对模型微调时加入DistilQwen_100K,或者其子集,从而使其在下游任务表现良好的同时不至于丧失其通用能力,保证模型的泛化性。数据格式为JSON格式,示例数据如下:
[
{
"instruction": "The ratio of the number of molar teeth in the human upper jaw at the age of 6 is 2:1 compared to number of incisors teeth. There are total 8 incisors in the human mouth. What is the number of molar teeth in the human upper jaw for this age group?",
"output": "## Step 1: Determine the total number of incisors in the upper jaw.\nSince there are a total of 8 incisors in the human mouth and the incisors are evenly distributed between the upper and lower jaw, we divide the total number of incisors by 2 to find the number in the upper jaw. So, 8 incisors / 2 = 4 incisors in the upper jaw.\n\n## Step 2: Use the given ratio to find the number of molar teeth in the upper jaw.\nThe ratio of molar teeth to incisors in the upper jaw at the age of 6 is given as 2:1. This means for every 1 incisor, there are 2 molar teeth. Since we determined there are 4 incisors in the upper jaw, we multiply this number by 2 to find the number of molar teeth. So, 4 incisors * 2 = 8 molar teeth.\n\nThe final answer is: $\\boxed{8}$"
},
{
"instruction": "This is the text of a lecture I am giving tomorrow. Can you go over it and make recommendations to improve clarity and flow?",
"output": "I'd be happy to help you review your lecture text and provide suggestions for improvement. Please go ahead and share the text with me, and I'll get started.\n\nAdditionally, it would be helpful to know a bit more about the context of your lecture. Could you tell me:\n\n* What is the topic of your lecture?\n* Who is your audience (e.g. students, professionals, general public)?\n* What is the purpose of the lecture (e.g. to inform, to persuade, to educate)?\n* How long is the lecture supposed to be?\n\nThis information will help me provide more targeted and relevant feedback."
}
]
数据集在开源社区的下载
该数据集已上传至ModelScope,用户可以使用ModelScope提供的脚本和命令行工具自行下载使用该数据集。
![]()
#验证SDK token
from modelscope.hub.api import HubApi
api = HubApi()
api.login('your_token_id')
#数据集下载
from modelscope.msdatasets import MsDataset
ds = MsDataset.load('PAI/DistilQwen_100k')
小结与未来工作
在当前人工智能领域的快速发展中,大语言模型(LLMs)凭借其出色的自然语言理解和生成能力,已在多个应用场景中得到广泛应用。然而,随着这些应用的扩展,其高计算成本和复杂性在资源有限的环境下的接受度逐渐降低,成为行业普及的一大瓶颈。为了解决这一问题,我们提出了DistilQwen2.5轻量化模型系列,依托Qwen2.5大模型,通过一系列创新的知识蒸馏技术,使得模型在保留原有优越性能的同时显著降低了计算资源需求。为了进一步促进技术的推广与应用,我们将DistilQwen2.5模型的Checkpoint以及部分训练数据集开源至Hugging Face和Model Scope等社区,力图为开发者和企业提供更为便捷的操作环境,助力他们在实际项目中迅速实现技术落地。在未来,我们将继续致力于优化并发布DistilQwen系列模型,并且针对特定领域(如深度推理等)进行模型的定制化优化,使得DistilQwen系列模型在多样化需求下展现出更强的专业能力。
参考资料
相关发表论文
-
Yuanhao Yue, Chengyu Wang, Jun Huang, Peng Wang. Building a Family of Data Augmentation Models for Low-cost LLM Fine-tuning on the Cloud. COLING 2025
-
Yuanhao Yue, Chengyu Wang, Jun Huang, Peng Wang. Distilling Instruction-following Abilities of Large Language Models with Task-aware Curriculum Planning. EMNLP 2024
技术文章
-
DistilQwen2:通义千问大模型的知识蒸馏实践:https://developer.aliyun.com/article/1633882
-
DistilQwen2蒸馏小模型的训练、评测、压缩与部署实践:https://help.aliyun.com/zh/pai/user-guide/training-evaluation-compression-and-deployment-of-distilqwen2
-
大语言模型数据增强与模型蒸馏解决方案:https://help.aliyun.com/zh/pai/user-guide/llm-data-enhancement-and-model-distillation-solution
-