一、什么是小程序平台
得物小程序平台致力于整合并管理微信、支付宝等渠道的得物数字资产,实现数字化管理。通过该平台,小程序和公众号等功能纳入公司工作流,以提升用户体验和管理效率。
![小程序1.jpeg]()
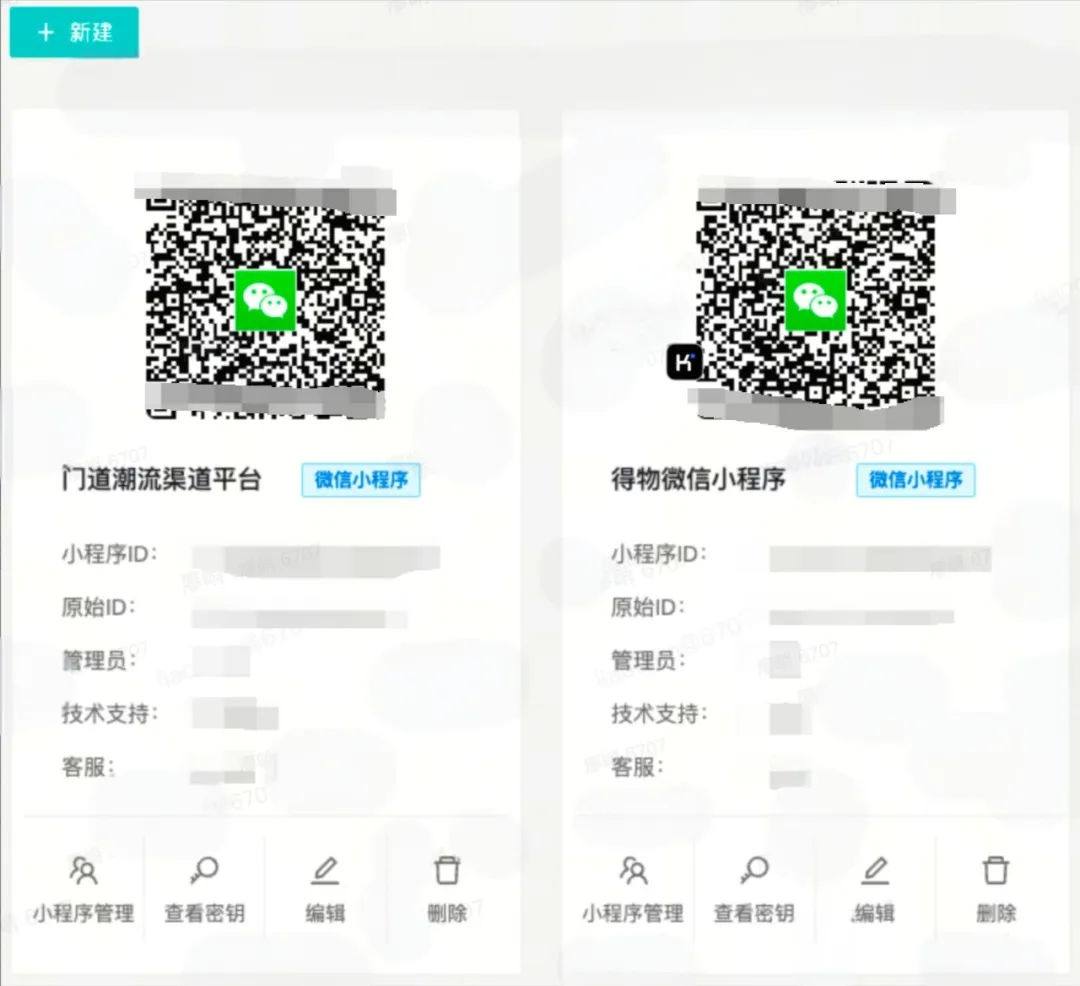
项目一期的成功推出,使得数字化管理得以实现,传统的线下沟通模式顺利迁移至线上。截至目前,平台已接入多个小程序,实现了用户自主申请角色的能力,以及迅速处理了多条用户投诉,并及时转发至技术支持部门。
多小程序管理 ![多小程序管理.jpeg]()
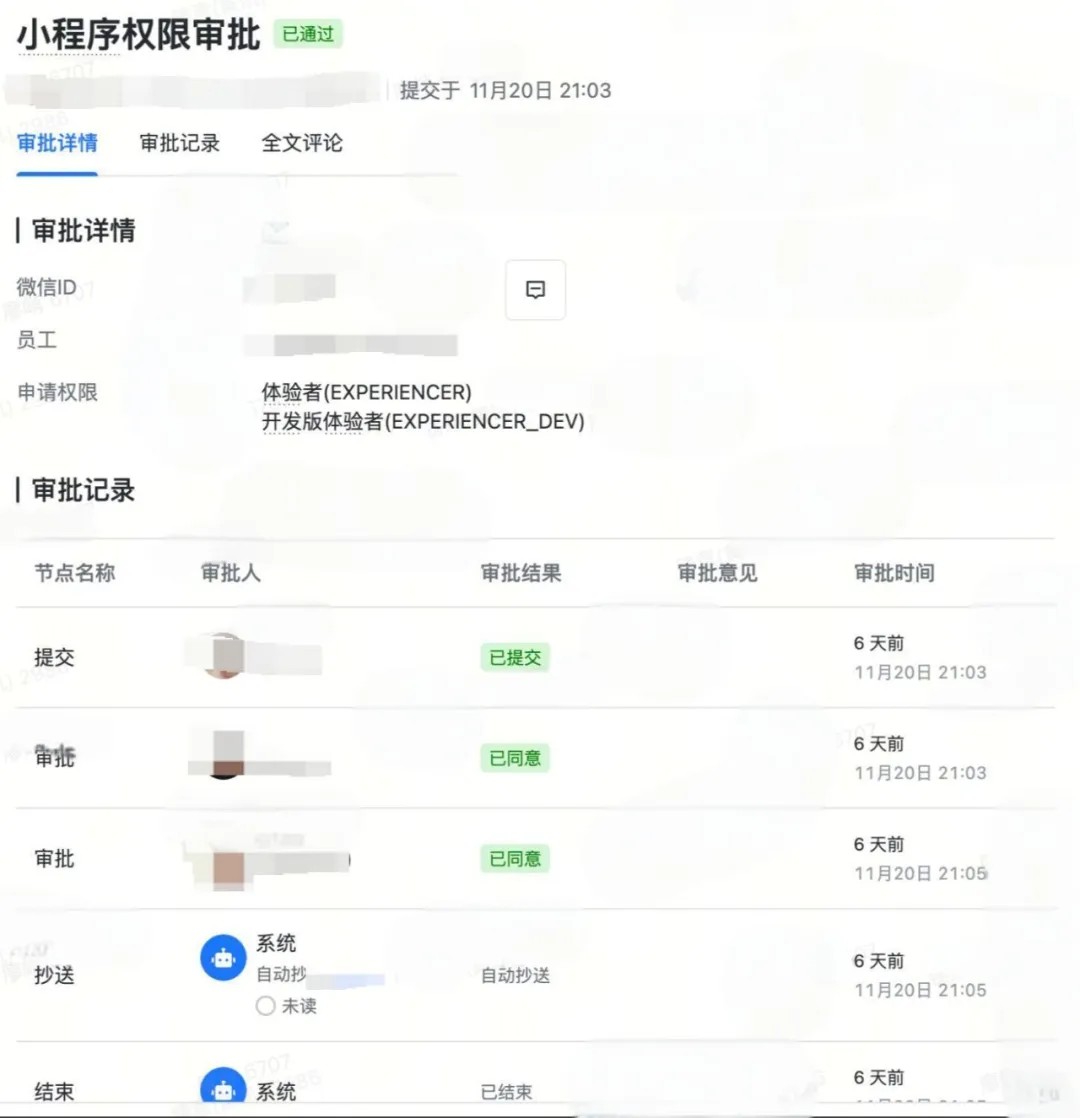
小程序维护人员审批流 ![小程序维护.jpeg]()
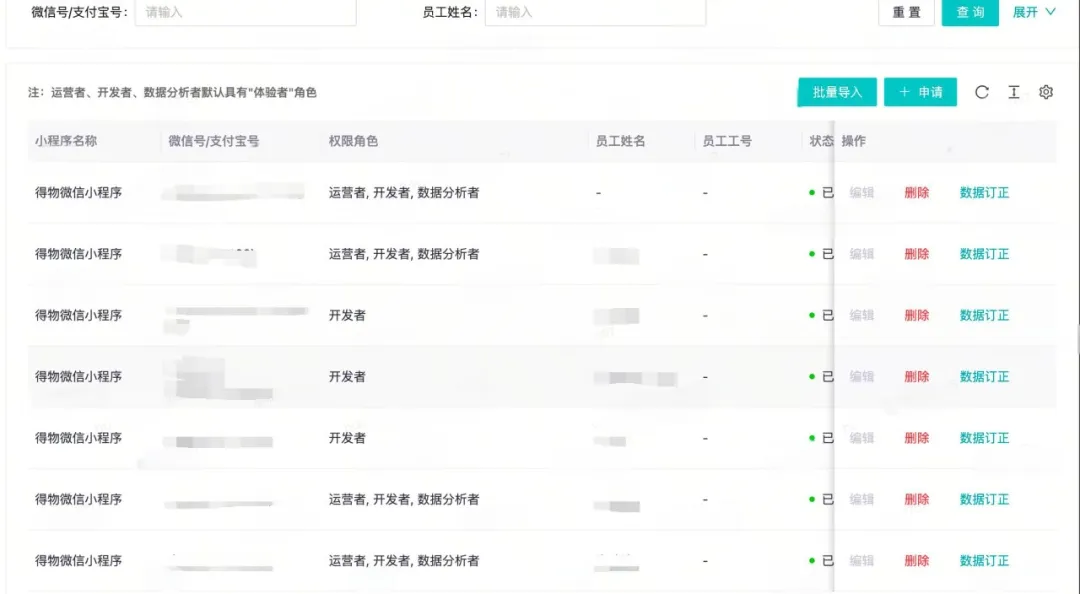
小程序维护人员列表 ![小程序维护列表.jpeg]()
二、为什么要做小程序平台
当前挑战
1.管理流程与效率
- 成员与开发者管理主要依赖手动操作,缺少自动化支持,这在人员变动时造成了权限更新的延迟。
2.消息处理与联动不足
- 现有的投诉与问题推送系统未能有效与管理流程对接,从而影响整体响应效率和用户体验。
3.数字资产透明度
- 数字资产管理尚缺乏透明度,追踪与管理资产使用情况变得复杂,这给管理带来了一定挑战。
改进方向
1.增强微信开放平台的对接能力,以提升工作效率。 2.提升小程序体系的基础能力,推动管理流程的数字化转型。
核心目标
实现多个小程序的统一线上管理,减少人为操作。具体目标包括:
- 降低因权限滥用导致的数据安全问题。
- 实现用户投诉的快速响应,以显著提升用户体验。
- 提高小程序的运营效率。
三、怎么做小程序平台
技术重点: 1.小程序在线标准化 2.多小程序多平台的统一管理
作为平台方,我们需有效整合内部工作流与外部微信和支付宝平台,具体拆解如下:
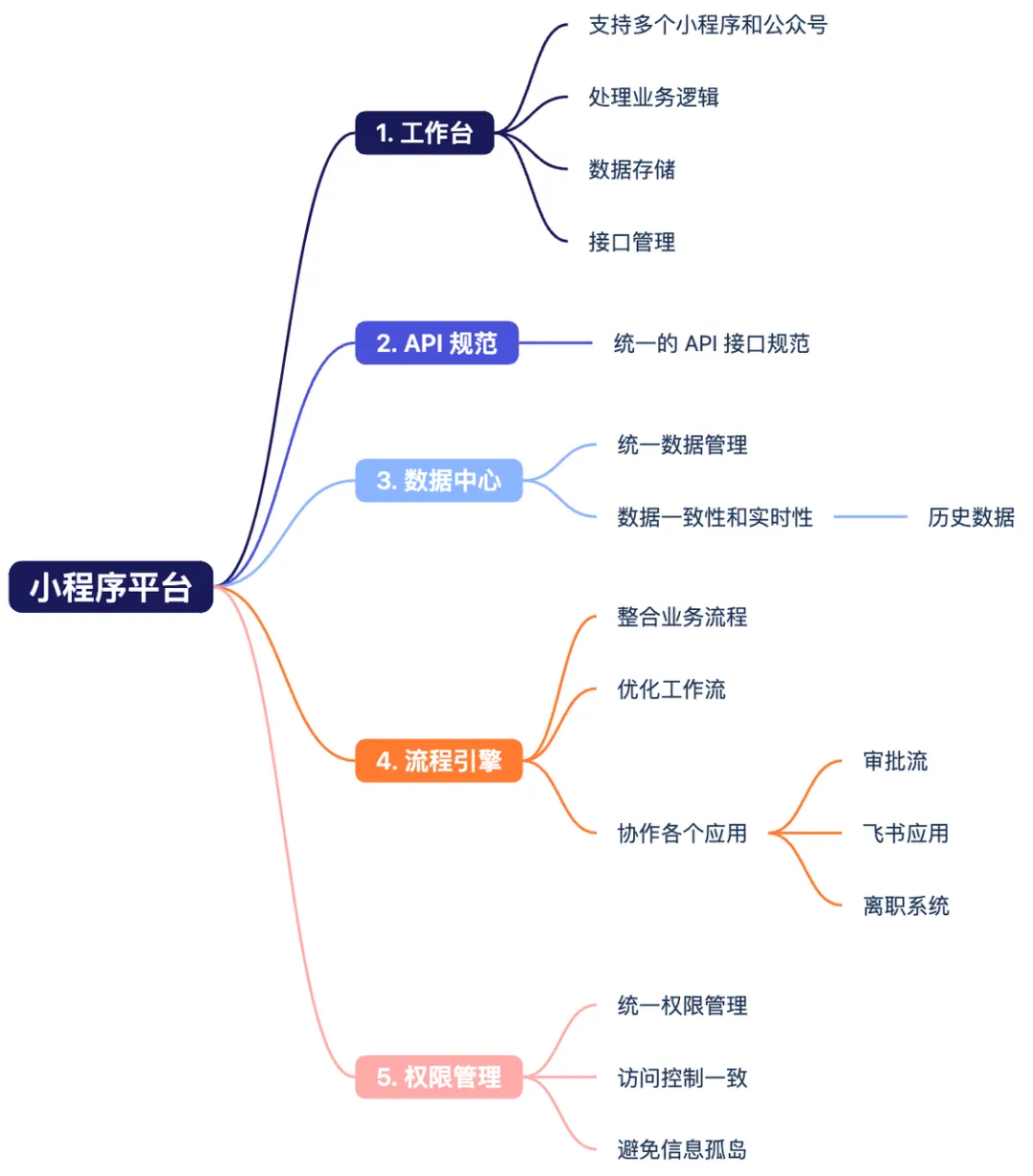
1.工作台: 提供一站式工作平台,不同用户角色通过该平台进行小程序的在线管理。普通用户可轻松申请体验权限,客服专员则聚焦于处理客户投诉与反馈,管理员负责管理小程序资产。
2.API规范: 通过中间层对接SDK,消除微信和支付宝开放平台之间的技术壁垒。
3.数据中心: 作为核心模块,统一管理公司内部数据,确保小程序信息、用户、角色、投诉等数据实时同步。
4.流程引擎与权限管理: 结合工作台,通过飞书进行流程管理和消息实时推送。
![流程引擎.jpeg]()
总体设计
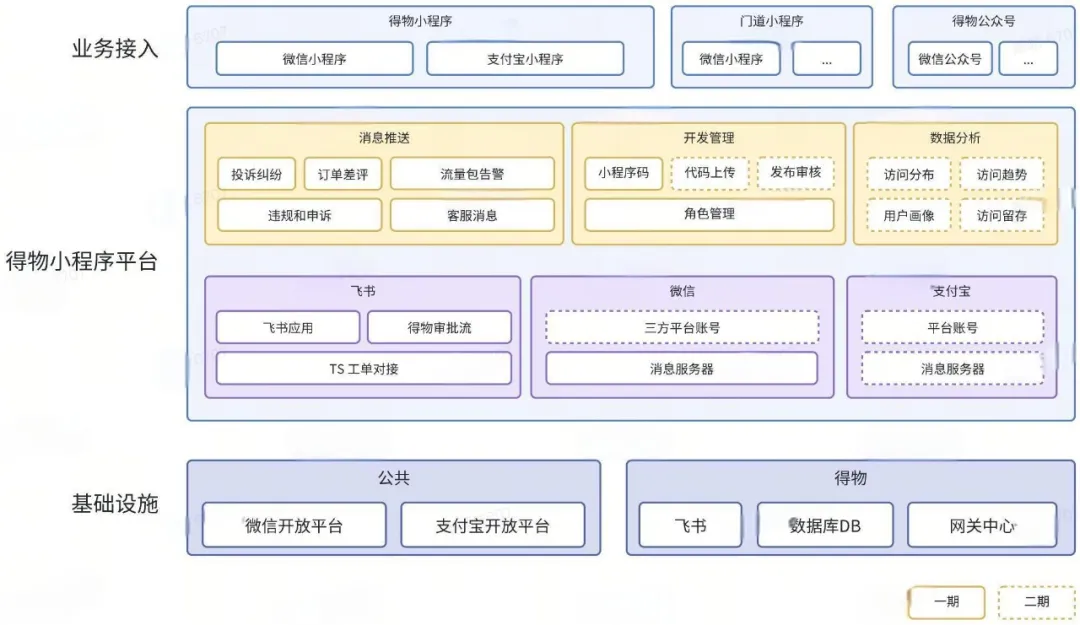
基于线上化目标,从实际痛点和公司基建现状出发,得物小程序平台的核心内容包括:
1.主工作台:
- 开发管理:角色管理、成员管理、小程序体验码等
- 消息推送:投诉/违规消息提示、告警消息、工单下发等
- 小程序管理:小程序列表管理
- ...
2.工作流协同:与飞书审批流、飞书助手、TS工单、离职系统等进行协同。
![工作流协同.jpeg]()
详细设计
一期在线化目标重点在【开发管理】和【消息推送】2个模块。
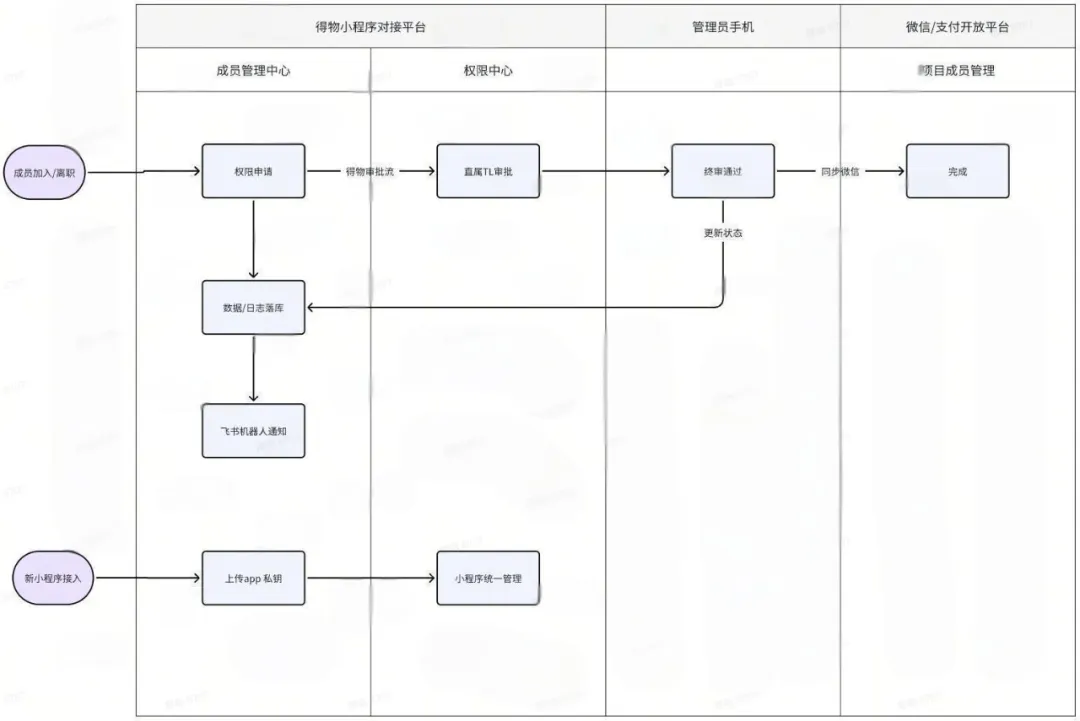
1.开发管理
- 实现小程序角色的在线新增和移除,确保每一次操作都有记录,同时对接公司的审批流程。
- 离职员工的信息可通过系统自动移除,避免了人为失误。
![开发管理1.jpeg]()
![开发管理.jpeg]()
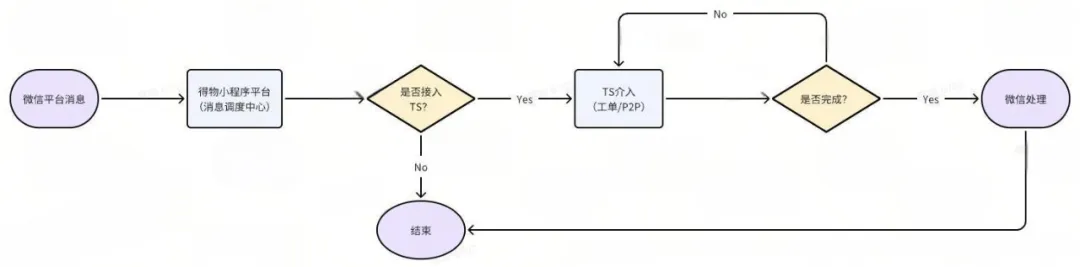
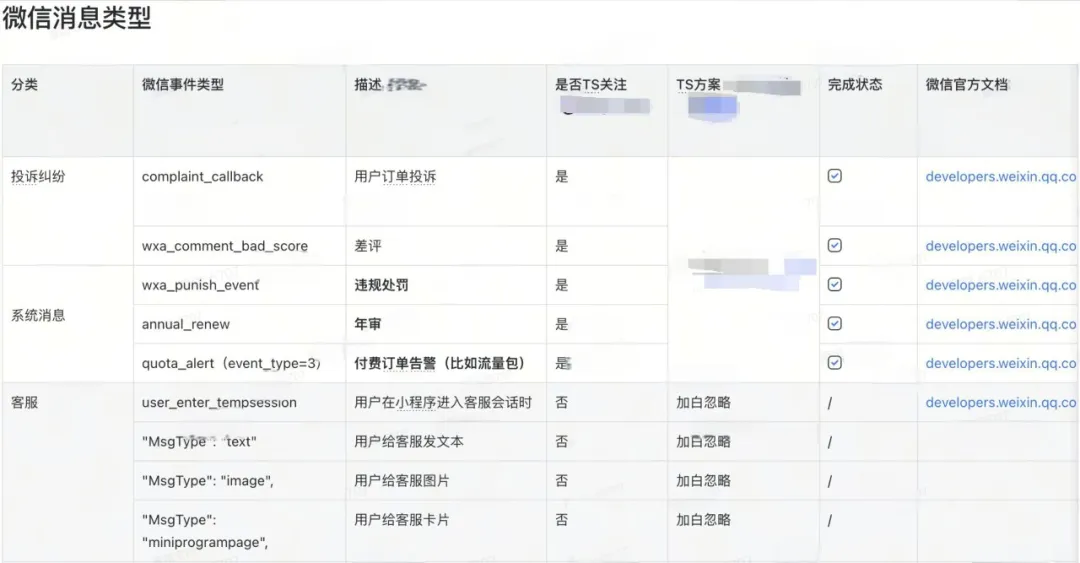
2.消息推送
- 对接TS工单,技术性问题通过TS平台处理,业务类问题则交由运营团队。
- 对接飞书机器人,完成了消息的实时推送。
![信息推送1.jpeg]()
![消息推送.jpeg]()
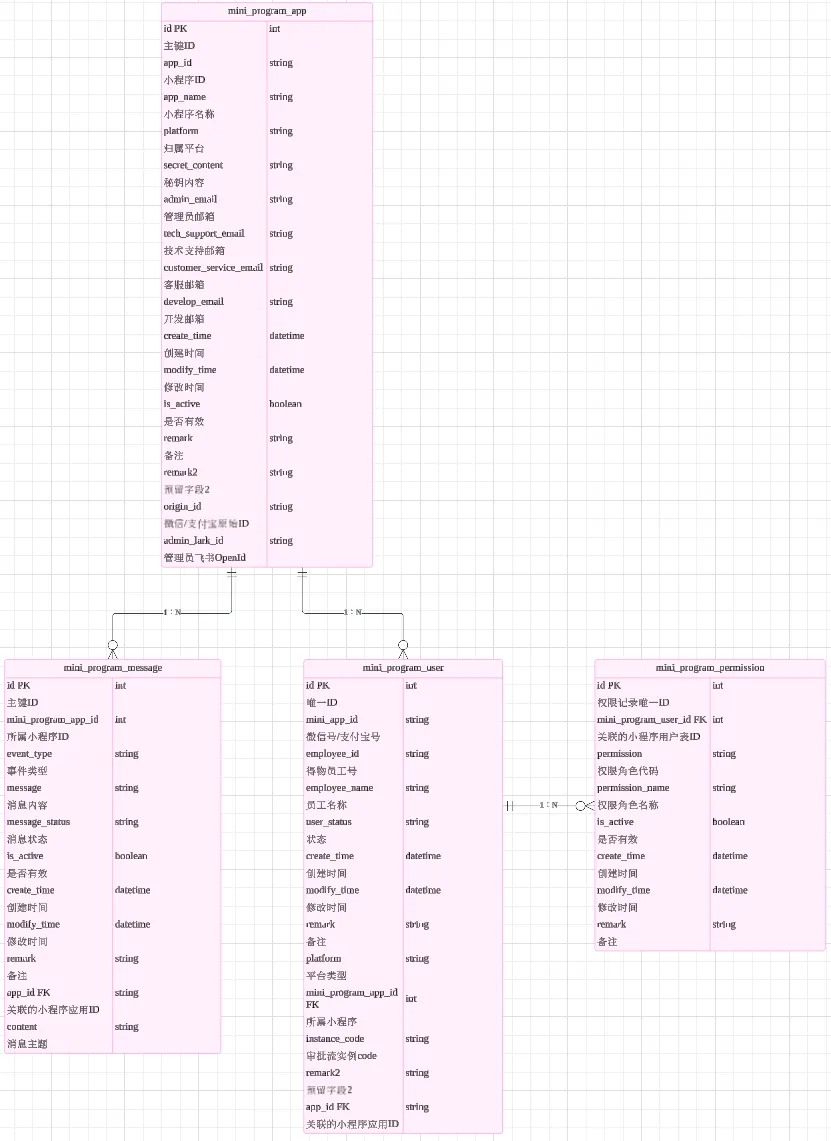
数据库设计
根据上方工作流设计,设计如下表数据结构,用来存储角色、权限、消息等数据。并结合Cursor AI工具,使代码逻辑的开发变得高效便捷。
![数据库设计.jpeg]()
业务效果
1.在线管理成功落地:
小程序平台V1.0成功推出,接入多款小程序,多个用户已开通线上权限申请。集成管理平台大幅减少了人工操作时间。
2.运营效率显著提升:
通过优化流程,降低了对人工干预的依赖,确保所有投诉能够及时跟进并解决。
3.用户反馈积极改善:
收集的用户反馈显示,投诉响应时间由平均数小时缩短至几分钟,新的小程序平台提高了处理效率与透明度。
四、遇到的挑战
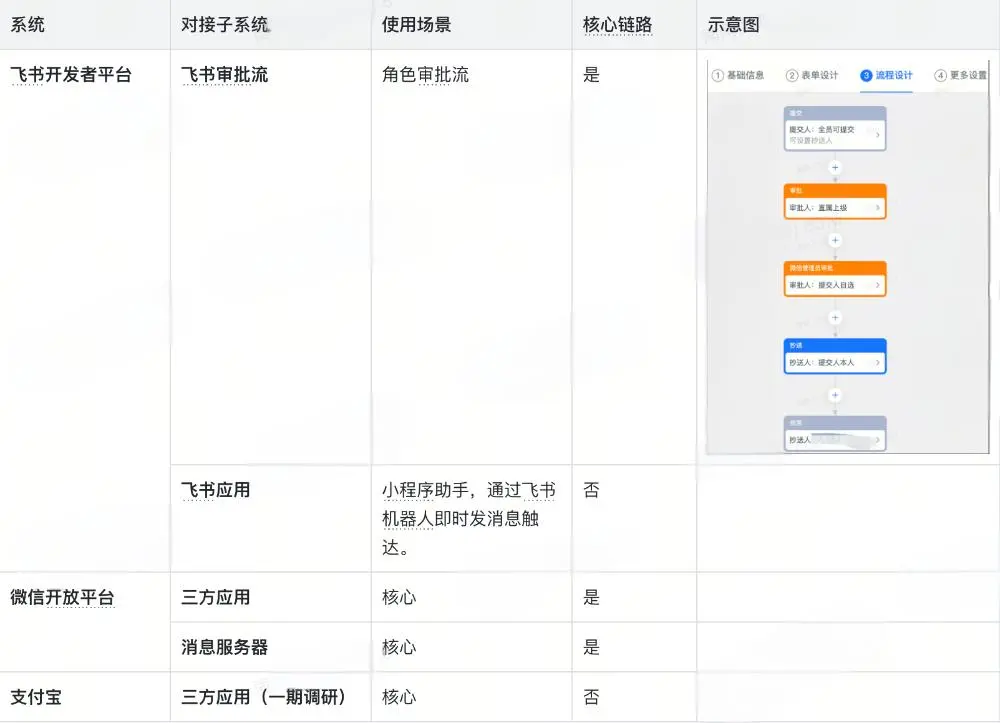
挑战1:跨平台接入的复杂性超出预期
在系统实现过程中,我们要深度接入4个平台(微信、支付宝、飞书、内部系统),涉及的上下游系统超过10个,导致工作流的复杂性远超预期。
- 缺乏前置经验参考:从0到1工作量巨大,且涉及内外多个系统和工作流;
- 接入流程门槛高:微信三方平台、飞书审批流、微信消息服务器,每个都是都独立且较高门槛的接入流程;
- 依赖大量文档调研:很多微信/飞书功能都需通过查阅官方文档进行探索,导致信息的不确定性;
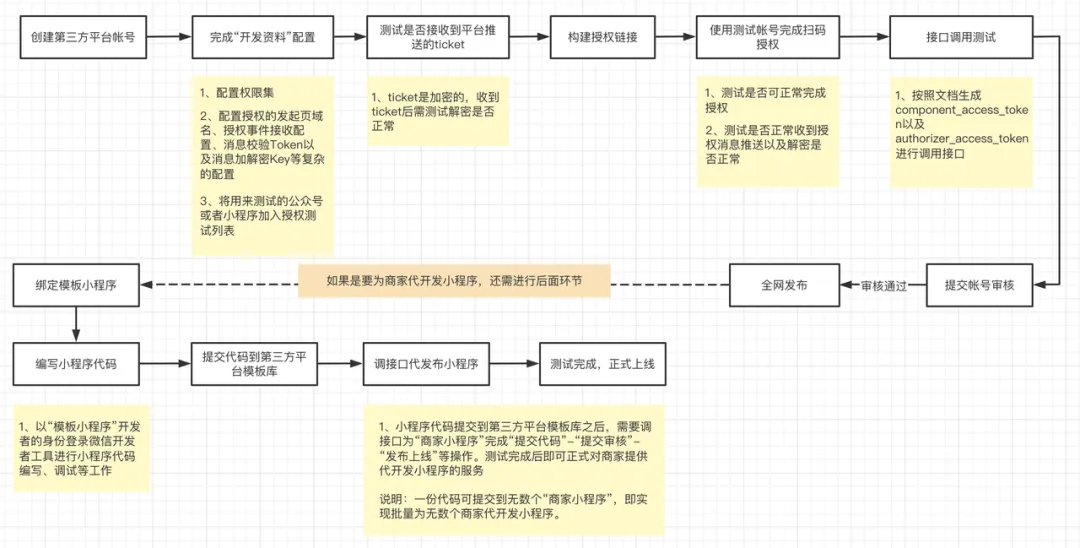
1.微信三方平台接入流程
![微信三方平台.jpeg]()
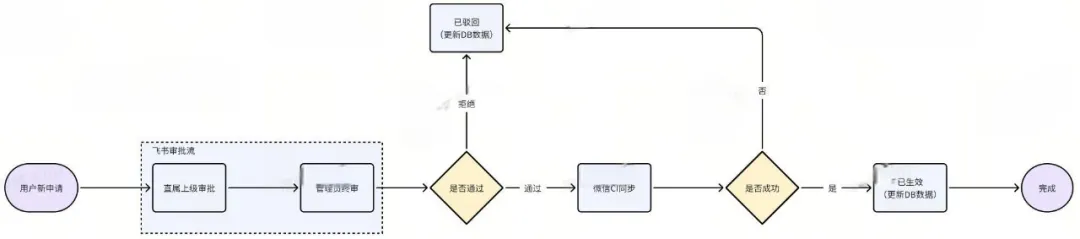
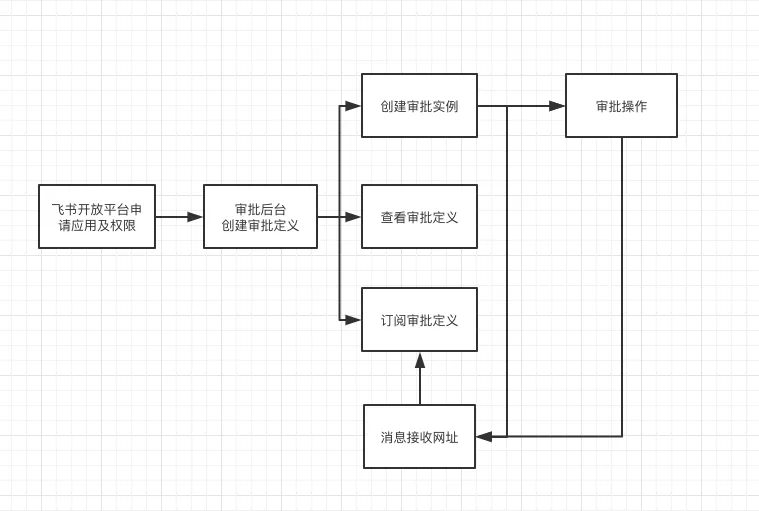
2.飞书审批流接入流程
![飞书审批流.jpeg]()
挑战2:缺乏开箱即用的基础设施
运维配置的复杂性增加了落地过程中的挑战,需反复与相关团队沟通,以解决网络问题和资源配置。
- 缺乏运维解决方案。示例,微信和飞书等外网服务器的接入需要处理的运维问题非常繁琐,而目前的运维工具无法提供一站式解决方案。
- 前端基建待完善。新建一个后台管理系统成本高,新域名、Nginx配置、B端脚手架都需要时间和耐心去管理。
- 文档不全。团队在技术支持和功能需求上常面临信息不足,尤其在对接微信公网时,缺乏系统化文档影响了问题解决的效率。
解决方案
策略:
模块化设计分解复杂性,先完成再完美。 AI工具提效,让多个AI人帮你打工。 文档留痕。
模块化设计分解复杂性
拆分清楚每个子系统在整体架构图里所处的位置,是否是关键核心链路还是用户体验优化,根据这判断工作优先级。
- 要事第一,尽快跑通最小可用性产品(MVP),
- 保持跟主管时刻对焦,确保目标产物跟预期一致,事事有反馈,件件有着落。
![模块化设计.jpeg]()
AI工具提效
现在的AI足够强大,很适合做流程性、确定性的工作。充分利用好Cursor、ChatGPT、Kimi等工具,让个人效率和产出最大化。强烈推荐Cursor Compose模式,Cursor底层用的claude.ai,它最大的能力是基于当前codebase索引库,所以它生成的代码可以读懂上下文,也能模仿项目里其他的代码写法,更智能。心得总结:
- 表结构要设计好,完整、准确、非歧义。
- 询问的范围Scope,尽量缩小。不然AI给你的答案可能越来越偏,也能理解,范围越大意图理解就偏差了。
- 准确的意图。可以让AI出解决方案,但一定是基于你现有的上下文足够多,且有正反馈。再强调下,准确的意图
- 沟通的方案,让AI记录在README.md中。这个方式很有效,随着系统越来越复杂,把中间跟AI达成的一致内容,包括背景、设计目标、技术方案等让AI写在Markdown文档中。
![沟通的方案.jpeg]()
文档留痕
1.基本每个步骤都能有对应的文档。
2.顺道完善了公司2个配套基建问题。
五、总结心得
1.加强技术基础建设
- 技术基础设施及文档管理的重要性不可忽视,改善沟通成本和提高工作效率至关重要。
- 运维侧工具足够多,但缺少一站式解决方案。本质上大家所处视角不同,业务背景也不同,需要从全局视角看运维要做什么,业务方又需要配合哪些场景。
2.合理利用AI提升效率
- AI工具在本次项目中的应用显著提高了效率。无论是文档阅读、功能调研还是代码生成,AI工具都能快速提供有效的建议和总结,帮助节省了大量的时间。
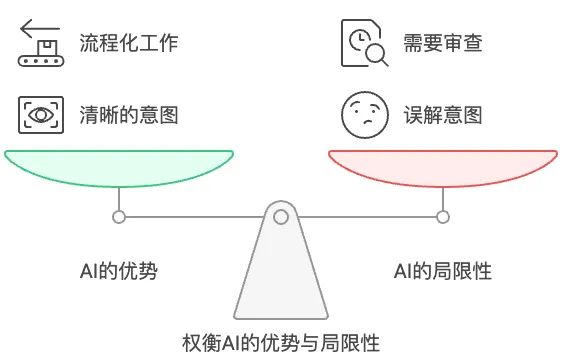
- 然而,也意识到AI并非万能。它能够处理大量信息和基础逻辑,但在复杂的人际互动、视觉设计或独特创新性任务上仍然存在局限。因此,在未来的工作中,将继续探索AI的应用边界,以更好地发挥其优势。
3.持续优化的心态
- 尽管小程序平台的V1.0版取得了阶段性成功,但深知这只是一个起点。在后续开发中,将着重于持续迭代与优化,确保平台能够不断满足用户的需求与公司发展的目标。
- 跟业务制定反馈收集机制,以便及时调整策略,提升产品的用户体验和整体效率。
六、未来计划
1.小程序平台二期开发:
- 启动小程序平台的二期开发,专注于整合管理微信、支付宝等外部渠道的得物数字资产。
- 实现与得物工作流的无缝对接,目标使不同角色人员在项目处理中无需进行下沟通或人肉搜索,提升工作效率。
2.AI工具分享:
在团队内部进行AI工具的使用技巧分享,尤其针对Cursor和各种AI类工具应用。
文 / springleo
关注得物技术,每周更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。