这篇文章会聊些什么
Apache SeaTunnel作为一款数据集成工具, 那么它最终的目的是来做数据同步, 将数据从某个存储同步到另外一个存储中。
但是这篇文章并不会聊它使用层面的事情, 而是去聊一下这个工具/框架的设计, 任务的执行等.对于某个连接器(数据库)的实现不会深入的了解,希望对你有帮助!
基于的源码版本: 2.3.6-release
这些类是如何被执行的
在我另外的文章中有一些关于Zeta引擎的分析, 聊了一下Zeta引擎的客户端, 服务端都会做一些什么事情, 也笼统的带了一点任务执行的内容, 想了解相关内容的朋友可以去看一下。
在下面的内容, 则主要是记录一下在SeaTunnel中, 一个任务是如何与上面的连接器中的各种类进行关联的。
要聊任务与连接器的关联, 就要回到物理计划生成的这一部分(PhysicalPlanGenerator#generate()).
Stream<SubPlan> subPlanStream =
pipelines.stream()
.map(
pipeline -> {
this.pipelineTasks.clear();
this.startingTasks.clear();
this.subtaskActions.clear();
final int pipelineId = pipeline.getId();
final List<ExecutionEdge> edges = pipeline.getEdges();
List<SourceAction<?, ?, ?>> sources = findSourceAction(edges);
List<PhysicalVertex> coordinatorVertexList =
getEnumeratorTask(
sources, pipelineId, totalPipelineNum);
coordinatorVertexList.addAll(
getCommitterTask(edges, pipelineId, totalPipelineNum));
List<PhysicalVertex> physicalVertexList =
getSourceTask(
edges, sources, pipelineId, totalPipelineNum);
physicalVertexList.addAll(
getShuffleTask(edges, pipelineId, totalPipelineNum));
CompletableFuture<PipelineStatus> pipelineFuture =
new CompletableFuture<>();
waitForCompleteBySubPlanList.add(
new PassiveCompletableFuture<>(pipelineFuture));
checkpointPlans.put(
pipelineId,
CheckpointPlan.builder()
.pipelineId(pipelineId)
.pipelineSubtasks(pipelineTasks)
.startingSubtasks(startingTasks)
.pipelineActions(pipeline.getActions())
.subtaskActions(subtaskActions)
.build());
return new SubPlan(
pipelineId,
totalPipelineNum,
initializationTimestamp,
physicalVertexList,
coordinatorVertexList,
jobImmutableInformation,
executorService,
runningJobStateIMap,
runningJobStateTimestampsIMap,
tagFilter);
});
这是将执行计划转换为物理计划时的相关代码,里面有这样4行代码。 生成EnumeratorTask, CommitterTask将其添加到协调器任务列表中 生成SourceTask,ShuffleTask将其添加到物理任务列表中。
List<PhysicalVertex> coordinatorVertexList =
getEnumeratorTask(
sources, pipelineId, totalPipelineNum);
coordinatorVertexList.addAll(
getCommitterTask(edges, pipelineId, totalPipelineNum));
List<PhysicalVertex> physicalVertexList =
getSourceTask(
edges, sources, pipelineId, totalPipelineNum);
physicalVertexList.addAll(
getShuffleTask(edges, pipelineId, totalPipelineNum));
我们这篇文章看下这四行代码以及他们与上面的Source,Transform,Sink有什么关系。接口中定义的reader,enumerator,writer是如何被执行的。
Task
在看这几个之前先看下他们实现的公共接口Task 从物理计划解析的代码可以知道,一个同步任务的执行过程都会被转换为Task。 Task是执行层面的最小单位,一个同步任务配置DAG,可以包括多个不相关,可以并行的Pipeline,一个Pipeline中可以包括多个类型的Task,Task之间存在依赖关系,可以认为是一个图中的一个顶点。 任务的容错也是基于最小粒度的Task来进行恢复的,而无需恢复整个DAG或Pipeline。可以实现最小粒度的容错。
一个Task在执行时会被worker上线程池里面的一个线程拿去执行,在SeaTunnel中对于数据同步的场景,某些Task可能暂时没有数据需要进行同步,如果一直占用某个线程资源,可能会造成浪费的情况,做了共享资源的优化。关于这部分的内容,可以参考这个Pull Request以及TaskExecutionService#BlockingWorker和TaskExecutionService#CooperativeTaskWorker相关代码(此功能也默认没有开启,不过这部分代码的设计确实值得了解学习一下。)
一个Task被分类为CoordinatorTask协调任务和SeaTunnelTask同步任务。 这篇内容里面不会对CoordinatorTask协调任务里面的checkpoint进行探讨, 只会关注SeaTunnelTask同步任务.
SourceSplitEnumeratorTask
在生成物理计划时,会对所有的source进行遍历,为每个source都创建一个 SourceSplitEnumeratorTask
private List<PhysicalVertex> getEnumeratorTask(
List<SourceAction<?, ?, ?>> sources, int pipelineIndex, int totalPipelineNum) {
AtomicInteger atomicInteger = new AtomicInteger(-1);
return sources.stream()
.map(
sourceAction -> {
long taskGroupID = idGenerator.getNextId();
long taskTypeId = idGenerator.getNextId();
TaskGroupLocation taskGroupLocation =
new TaskGroupLocation(
jobImmutableInformation.getJobId(),
pipelineIndex,
taskGroupID);
TaskLocation taskLocation =
new TaskLocation(taskGroupLocation, taskTypeId, 0);
SourceSplitEnumeratorTask<?> t =
new SourceSplitEnumeratorTask<>(
jobImmutableInformation.getJobId(),
taskLocation,
sourceAction);
...
...
})
.collect(Collectors.toList());
}
我们先看下这个数据源切入任务类的成员变量和构造方法:
public class SourceSplitEnumeratorTask<SplitT extends SourceSplit> extends CoordinatorTask {
private static final long serialVersionUID = -3713701594297977775L;
private final SourceAction<?, SplitT, Serializable> source;
private SourceSplitEnumerator<SplitT, Serializable> enumerator;
private SeaTunnelSplitEnumeratorContext<SplitT> enumeratorContext;
private Serializer<Serializable> enumeratorStateSerializer;
private Serializer<SplitT> splitSerializer;
private int maxReaderSize;
private Set<Long> unfinishedReaders;
private Map<TaskLocation, Address> taskMemberMapping;
private Map<Long, TaskLocation> taskIDToTaskLocationMapping;
private Map<Integer, TaskLocation> taskIndexToTaskLocationMapping;
private volatile SeaTunnelTaskState currState;
private volatile boolean readerRegisterComplete;
private volatile boolean prepareCloseTriggered;
@SuppressWarnings("unchecked")
public SourceSplitEnumeratorTask(
long jobID, TaskLocation taskID, SourceAction<?, SplitT, ?> source) {
super(jobID, taskID);
this.source = (SourceAction<?, SplitT, Serializable>) source;
this.currState = SeaTunnelTaskState.CREATED;
}
}
可以看到这个类中持有了几个关键的成员变量,SourceAction,SourceSplitEnumerator, SeaTunnelSplitEnumeratorContext 这些都是与enumerator相关的类。 还有几个map,set等容器存放了任务信息,任务执行地址等等的映射关系。
在构造方法的最后会将当前任务的状态初始化为CREATED
再来看下这个任务的其他方法:
@Override
public void init() throws Exception {
currState = SeaTunnelTaskState.INIT;
super.init();
readerRegisterComplete = false;
log.info(
"starting seatunnel source split enumerator task, source name: "
+ source.getName());
enumeratorContext =
new SeaTunnelSplitEnumeratorContext<>(
this.source.getParallelism(),
this,
getMetricsContext(),
new JobEventListener(taskLocation, getExecutionContext()));
enumeratorStateSerializer = this.source.getSource().getEnumeratorStateSerializer();
splitSerializer = this.source.getSource().getSplitSerializer();
taskMemberMapping = new ConcurrentHashMap<>();
taskIDToTaskLocationMapping = new ConcurrentHashMap<>();
taskIndexToTaskLocationMapping = new ConcurrentHashMap<>();
maxReaderSize = source.getParallelism();
unfinishedReaders = new CopyOnWriteArraySet<>();
}
在初始化时,会将状态修改为INIT,并且创建enumeratorContext,以及对其他几个变量进行初始化操作。 不知道大家有没有注意到,到执行完init方法,enumerator实例都没有被创建出来, 当搜索一下代码,会发现enumerator实例会在restoreState(List<ActionSubtaskState> actionStateList)这个方法中进行初始化。 当我们看完状态切换后就可以看到这个方法什么时候被调用了。
private void stateProcess() throws Exception {
switch (currState) {
case INIT:
currState = WAITING_RESTORE;
reportTaskStatus(WAITING_RESTORE);
break;
case WAITING_RESTORE:
if (restoreComplete.isDone()) {
currState = READY_START;
reportTaskStatus(READY_START);
} else {
Thread.sleep(100);
}
break;
case READY_START:
if (startCalled && readerRegisterComplete) {
currState = STARTING;
enumerator.open();
enumeratorContext.getEventListener().onEvent(new EnumeratorOpenEvent());
} else {
Thread.sleep(100);
}
break;
case STARTING:
currState = RUNNING;
log.info("received enough reader, starting enumerator...");
enumerator.run();
break;
case RUNNING:
// The reader closes automatically after reading
if (prepareCloseStatus) {
this.getExecutionContext()
.sendToMaster(new LastCheckpointNotifyOperation(jobID, taskLocation));
currState = PREPARE_CLOSE;
} else if (prepareCloseTriggered) {
currState = PREPARE_CLOSE;
} else {
Thread.sleep(100);
}
break;
case PREPARE_CLOSE:
if (closeCalled) {
currState = CLOSED;
} else {
Thread.sleep(100);
}
break;
case CLOSED:
this.close();
return;
// TODO support cancel by outside
case CANCELLING:
this.close();
currState = CANCELED;
return;
default:
throw new IllegalArgumentException("Unknown Enumerator State: " + currState);
}
}
- 当调用
init方法,会将状态设置为INIT,进入分支判断
- 当状态为
INIT时,将状态切换为WAITING_RESTORE
- 当状态为
WAITING_RESTORE时,进行restoreComplete.isDone()条件判断,当不满足时,睡眠100毫秒后重试。当满足时,会将状态设置为READY_START
restoreComplete在执行init方法时,会完成初始化操作,所以这里的睡眠等待就是等待init方法调用完成。
- 当状态为
READY_START时,会判断是否所有的reader都注册完成,如果都注册完成则将状态修改为STARTING,并且调用enumerator.open()方法。如果没有全部注册完成,则是继续休眠等待,一直到全部注册完成为止。
readerRegisterComplete变量在什么时候会变成true: 在初始化时,可以获取到source的并行度,也就是最终需要多少个reader,保存为maxReaderSize reader在启动时,会向enumerator注册自己的地址,在SourceSplitEnumeratorTask中内部维护了一个map结构,保存了reader的信息,每当有新reader注册时就会判断是否达到maxReaderSize,当达到数量后,会将readerRegisterComplete置为true
- 当状态为
STARTING时,将状态切换为RUNNING,同时调用enumerator.run()方法。 当调用run方法后,enumerator会真正去执行切分任务,根据配置,实际数据等等方式来将数据读取任务切分成多个小任务。然后将任务分发到不同的reader上。
- 当状态为
RUNNING时,会检查状态是否需要关闭,如果需要关闭则将状态修改为PREPARE_CLOSE, 否则休眠等待一直等到需要关闭。
prepareCloseStatus, prepareCloseTriggered变量什么时候会变为true: prepareCloseStatus变量会在所有的reader都完成读取任务时将状态置为true,也就是说enumerator任务是在所有reader任务结束之后才能结束的。 prepareCloseTriggered 变量则是当接收到系统任务完成或者是接收到需要做savepoint时才会将状态置为true 当两个变量被置为true时,表示当前任务已经结束或者需要手动结束了
- 当状态为
PREPARE_CLOSE时,会判断closeCalled变量是否为true,如果是则将状态修改为CLOSED,否则休眠等待
- CLOSED/CANCELLING状态时,则调用close方法对当前任务进行资源关闭清理工作。
刚刚在上面有写到enumerator实例没有被初始化,那么当调用enumerator相关方法时应该会得到空指针异常,所以初始化操作也就是restoreState的调用肯定是在READY_START状态前。 在最开始的两个状态INIT,WAITING_RESTORE中,有两个上报更新任务状态的方法调用.
reportTaskStatus(WAITING_RESTORE);reportTaskStatus(READY_START); 这个方法里,会向集群的Master发送一条TaskReportStatusOperation消息,消息里包含当前任务的位置和状态信息
protected void reportTaskStatus(SeaTunnelTaskState status) {
getExecutionContext()
.sendToMaster(new TaskReportStatusOperation(taskLocation, status))
.join();
}
我们看下TaskReportStatusOperation这个类的代码
@Override
public void run() throws Exception {
CoordinatorService coordinatorService =
((SeaTunnelServer) getService()).getCoordinatorService();
RetryUtils.retryWithException(
() -> {
coordinatorService
.getJobMaster(location.getJobId())
.getCheckpointManager()
.reportedTask(this);
return null;
},
new RetryUtils.RetryMaterial(
Constant.OPERATION_RETRY_TIME,
true,
e -> true,
Constant.OPERATION_RETRY_SLEEP));
}
可以看到在这个类中,会根据当前任务的id获取到JobMaster,然后调用其checkpointManager.reportTask()方法 再来看下checkpointManager.reportTask()方法
public void reportedTask(TaskReportStatusOperation reportStatusOperation) {
// task address may change during restore.
log.debug(
"reported task({}) status {}",
reportStatusOperation.getLocation().getTaskID(),
reportStatusOperation.getStatus());
getCheckpointCoordinator(reportStatusOperation.getLocation())
.reportedTask(reportStatusOperation);
}
protected void reportedTask(TaskReportStatusOperation operation) {
pipelineTaskStatus.put(operation.getLocation().getTaskID(), operation.getStatus());
CompletableFuture.runAsync(
() -> {
switch (operation.getStatus()) {
case WAITING_RESTORE:
restoreTaskState(operation.getLocation());
break;
case READY_START:
allTaskReady();
break;
default:
break;
}
},
executorService)
.exceptionally(
error -> {
handleCoordinatorError(
"task running failed",
error,
CheckpointCloseReason.CHECKPOINT_INSIDE_ERROR);
return null;
});
}
在CheckpointCoordinator中,会根据状态分别调用restoreTaskState()和allTaskReady()两个方法。 先看下restoreTaskState()方法
private void restoreTaskState(TaskLocation taskLocation) {
List<ActionSubtaskState> states = new ArrayList<>();
if (latestCompletedCheckpoint != null) {
if (!latestCompletedCheckpoint.isRestored()) {
latestCompletedCheckpoint.setRestored(true);
}
final Integer currentParallelism = pipelineTasks.get(taskLocation.getTaskVertexId());
plan.getSubtaskActions()
.get(taskLocation)
.forEach(
tuple -> {
ActionState actionState =
latestCompletedCheckpoint.getTaskStates().get(tuple.f0());
if (actionState == null) {
LOG.info(
"Not found task({}) state for key({})",
taskLocation,
tuple.f0());
return;
}
if (COORDINATOR_INDEX.equals(tuple.f1())) {
states.add(actionState.getCoordinatorState());
return;
}
for (int i = tuple.f1();
i < actionState.getParallelism();
i += currentParallelism) {
ActionSubtaskState subtaskState =
actionState.getSubtaskStates().get(i);
if (subtaskState != null) {
states.add(subtaskState);
}
}
});
}
checkpointManager
.sendOperationToMemberNode(new NotifyTaskRestoreOperation(taskLocation, states))
.join();
}
在这个方法里,首先会判断latestCompletedCheckpoint是否为null,那么我们在任务最开始的时候,这个状态肯定是空的,那么就会直接调用最下面的一段代码,发送一个NotifyTaskRestoreOperation到具体的任务节点. 既然看到这段代码,那么就再多想一下,如果latestCompletedCheckpoint不为null,那么就表示之前有过checkpoint记录,那么就表示了该任务是由历史状态进行恢复的,需要查询出历史状态,从历史状态进行恢复,这里的List<ActionSubtaskState>就存储了这些状态信息。
继续看下NotifyTaskRestoreOperation的代码
public void run() throws Exception {
SeaTunnelServer server = getService();
RetryUtils.retryWithException(
() -> {
log.debug("NotifyTaskRestoreOperation " + taskLocation);
TaskGroupContext groupContext =
server.getTaskExecutionService()
.getExecutionContext(taskLocation.getTaskGroupLocation());
Task task = groupContext.getTaskGroup().getTask(taskLocation.getTaskID());
try {
ClassLoader classLoader = Thread.currentThread().getContextClassLoader();
task.getExecutionContext()
.getTaskExecutionService()
.asyncExecuteFunction(
taskLocation.getTaskGroupLocation(),
() -> {
Thread.currentThread()
.setContextClassLoader(
groupContext.getClassLoader());
try {
log.debug(
"NotifyTaskRestoreOperation.restoreState "
+ restoredState);
task.restoreState(restoredState);
log.debug(
"NotifyTaskRestoreOperation.finished "
+ restoredState);
} catch (Throwable e) {
task.getExecutionContext()
.sendToMaster(
new CheckpointErrorReportOperation(
taskLocation, e));
} finally {
Thread.currentThread()
.setContextClassLoader(classLoader);
}
});
} catch (Exception e) {
throw new SeaTunnelException(e);
}
return null;
},
new RetryUtils.RetryMaterial(
Constant.OPERATION_RETRY_TIME,
true,
exception ->
exception instanceof TaskGroupContextNotFoundException
&& !server.taskIsEnded(taskLocation.getTaskGroupLocation()),
Constant.OPERATION_RETRY_SLEEP));
}
从上面的代码中可以看出最终是调用了task.restoreState(restoredState)方法。在这个方法调用中,enumerator实例也就被初始化了。
在上面还有一个当状态为READY_START时,调用allTaskReady()的分支。 我们先回到分支切换时,看下当什么情况下会是READY_START的状态。
case WAITING_RESTORE:
if (restoreComplete.isDone()) {
currState = READY_START;
reportTaskStatus(READY_START);
} else {
Thread.sleep(100);
}
break;
这里会判断一个restoreComplete是否是完成状态,而这个变量会在restoreState方法内标记为完成
@Override
public void restoreState(List<ActionSubtaskState> actionStateList) throws Exception {
log.debug("restoreState for split enumerator [{}]", actionStateList);
Optional<Serializable> state = .....;
if (state.isPresent()) {
this.enumerator =
this.source.getSource().restoreEnumerator(enumeratorContext, state.get());
} else {
this.enumerator = this.source.getSource().createEnumerator(enumeratorContext);
}
restoreComplete.complete(null);
log.debug("restoreState split enumerator [{}] finished", actionStateList);
}
也就是当初始化真正完成时,会标记为READY_START的状态。 看下allTaskReady的方法
private void allTaskReady() {
if (pipelineTaskStatus.size() != plan.getPipelineSubtasks().size()) {
return;
}
for (SeaTunnelTaskState status : pipelineTaskStatus.values()) {
if (READY_START != status) {
return;
}
}
isAllTaskReady = true;
InvocationFuture<?>[] futures = notifyTaskStart();
CompletableFuture.allOf(futures).join();
notifyCompleted(latestCompletedCheckpoint);
if (coordinatorConfig.isCheckpointEnable()) {
LOG.info("checkpoint is enabled, start schedule trigger pending checkpoint.");
scheduleTriggerPendingCheckpoint(coordinatorConfig.getCheckpointInterval());
} else {
LOG.info(
"checkpoint is disabled, because in batch mode and 'checkpoint.interval' of env is missing.");
}
}
这个方法内调用notifyTaskStart()方法,在此方法内会发送一个NotifyTaskStartOperation消息,在NotifyTaskStartOperation中,会获取到Task,调用startCall方法,在startCall中,将startCalled变量置为true
只有这里被执行了,状态切换中的READY_START状态才会切换为STARTING
case READY_START:
// 当任务启动并且所有reader节点也都启动注册完成后
// 改为STARTING状态,并且调用enumerate的open方法
// 否则一直等待
// 直到自身启动完成,以及所有reader注册完成
if (startCalled && readerRegisterComplete) {
currState = STARTING;
enumerator.open();
} else {
Thread.sleep(100);
}
break;
其他的任务类型也都会有这样一段逻辑。
接着按照顺序先看下committer task,这是另外一个协调任务
SinkAggregatedCommitterTask
这个类的代码与enumerator的代码类似,
public class SinkAggregatedCommitterTask<CommandInfoT, AggregatedCommitInfoT>
extends CoordinatorTask {
private static final long serialVersionUID = 5906594537520393503L;
private volatile SeaTunnelTaskState currState;
private final SinkAction<?, ?, CommandInfoT, AggregatedCommitInfoT> sink;
private final int maxWriterSize;
private final SinkAggregatedCommitter<CommandInfoT, AggregatedCommitInfoT> aggregatedCommitter;
private transient Serializer<AggregatedCommitInfoT> aggregatedCommitInfoSerializer;
@Getter private transient Serializer<CommandInfoT> commitInfoSerializer;
private Map<Long, Address> writerAddressMap;
private ConcurrentMap<Long, List<CommandInfoT>> commitInfoCache;
private ConcurrentMap<Long, List<AggregatedCommitInfoT>> checkpointCommitInfoMap;
private Map<Long, Integer> checkpointBarrierCounter;
private CompletableFuture<Void> completableFuture;
private MultiTableResourceManager resourceManager;
private volatile boolean receivedSinkWriter;
public SinkAggregatedCommitterTask(
long jobID,
TaskLocation taskID,
SinkAction<?, ?, CommandInfoT, AggregatedCommitInfoT> sink,
SinkAggregatedCommitter<CommandInfoT, AggregatedCommitInfoT> aggregatedCommitter) {
super(jobID, taskID);
this.sink = sink;
this.aggregatedCommitter = aggregatedCommitter;
this.maxWriterSize = sink.getParallelism();
this.receivedSinkWriter = false;
}
...
}
成员变量存储了sink的action,committer的实例引用。 使用几个容器存储writer的地址,checkpoint id与commit信息的映射等。
接下来再看下初始化方法
@Override
public void init() throws Exception {
super.init();
currState = INIT;
this.checkpointBarrierCounter = new ConcurrentHashMap<>();
this.commitInfoCache = new ConcurrentHashMap<>();
this.writerAddressMap = new ConcurrentHashMap<>();
this.checkpointCommitInfoMap = new ConcurrentHashMap<>();
this.completableFuture = new CompletableFuture<>();
this.commitInfoSerializer = sink.getSink().getCommitInfoSerializer().get();
this.aggregatedCommitInfoSerializer =
sink.getSink().getAggregatedCommitInfoSerializer().get();
if (this.aggregatedCommitter instanceof SupportResourceShare) {
resourceManager =
((SupportResourceShare) this.aggregatedCommitter)
.initMultiTableResourceManager(1, 1);
}
aggregatedCommitter.init();
if (resourceManager != null) {
((SupportResourceShare) this.aggregatedCommitter)
.setMultiTableResourceManager(resourceManager, 0);
}
log.debug(
"starting seatunnel sink aggregated committer task, sink name[{}] ",
sink.getName());
}
在初始化时,会对几个容器进行初始化,将状态置为INIT状态,对aggregatedCommitter进行初始化。这里会source split enumerator不同,sink committer是通过构造方法在外部初始化完成后传递进来的。
protected void stateProcess() throws Exception {
switch (currState) {
case INIT:
currState = WAITING_RESTORE;
reportTaskStatus(WAITING_RESTORE);
break;
case WAITING_RESTORE:
if (restoreComplete.isDone()) {
currState = READY_START;
reportTaskStatus(READY_START);
} else {
Thread.sleep(100);
}
break;
case READY_START:
if (startCalled) {
currState = STARTING;
} else {
Thread.sleep(100);
}
break;
case STARTING:
if (receivedSinkWriter) {
currState = RUNNING;
} else {
Thread.sleep(100);
}
break;
case RUNNING:
if (prepareCloseStatus) {
currState = PREPARE_CLOSE;
} else {
Thread.sleep(100);
}
break;
case PREPARE_CLOSE:
if (closeCalled) {
currState = CLOSED;
} else {
Thread.sleep(100);
}
break;
case CLOSED:
this.close();
return;
// TODO support cancel by outside
case CANCELLING:
this.close();
currState = CANCELED;
return;
default:
throw new IllegalArgumentException("Unknown Enumerator State: " + currState);
}
}
这里的状态转换比较简单,基本上都是直接进入下一个状态,但是这里有一点与eunmerator不太一样,在source enumerator中,需要等待全部的reader都启动完成,才会切换到running状态,这里稍有不同,这里只要有一个writer注册就会将receivedSinkWriter置为true,从而可以切换到running状态。
source eunmerator需要等待全部的reader节点才能启动是需要避免分配时,任务分配不均匀,早启动的任务分配了全部或者较多的任务。 而sink committer的任务则不一样,它是二次提交时使用,所以只要有一个writer启动,就有可能会有二次提交的任务产生,所以不需要等待全部writer启动。
这里的RUNNING状态到PREPARE_CLOSE状态的切换,会判断prepareCloseStatus是否为true,而这个变量只有在接收到任务结束的信号时才会被置为true,所以这个任务会在任务全部完成时才会被关闭。
现在就看完了数据拆分任务SourceSplitEnumerator以及数据提交任务SinkAggregatedCommitter的相关内容 接下来我们看下几个数据读取,写入。即reader,writer的相关任务执行过程。
SourceSeaTunnelTask
public class SourceSeaTunnelTask<T, SplitT extends SourceSplit> extends SeaTunnelTask {
private static final ILogger LOGGER = Logger.getLogger(SourceSeaTunnelTask.class);
private transient SeaTunnelSourceCollector<T> collector;
private transient Object checkpointLock;
@Getter private transient Serializer<SplitT> splitSerializer;
private final Map<String, Object> envOption;
private final PhysicalExecutionFlow<SourceAction, SourceConfig> sourceFlow;
public SourceSeaTunnelTask(
long jobID,
TaskLocation taskID,
int indexID,
PhysicalExecutionFlow<SourceAction, SourceConfig> executionFlow,
Map<String, Object> envOption) {
super(jobID, taskID, indexID, executionFlow);
this.sourceFlow = executionFlow;
this.envOption = envOption;
}
...
}
SourceSeaTunnelTask与TransformSeaTunnelTask都继承了SeaTunnelTask,这里的构造方法调用了父类的构造方法,这一部分我们统一在后面在看,先看下这个类中的其他方法。
@Override
protected void collect() throws Exception {
((SourceFlowLifeCycle<T, SplitT>) startFlowLifeCycle).collect();
}
@NonNull @Override
public ProgressState call() throws Exception {
stateProcess();
return progress.toState();
}
public void receivedSourceSplit(List<SplitT> splits) {
((SourceFlowLifeCycle<T, SplitT>) startFlowLifeCycle).receivedSplits(splits);
}
@Override
public void triggerBarrier(Barrier barrier) throws Exception {
SourceFlowLifeCycle<T, SplitT> sourceFlow =
(SourceFlowLifeCycle<T, SplitT>) startFlowLifeCycle;
sourceFlow.triggerBarrier(barrier);
}
这几个方法中,都是将调用转给了startFlowLifeCycle去进行调用。
在这个类中,还重新了父类的createSourceFlowLifeCycle方法,会去创建一个SourceFlowLifeCycle
@Override
protected SourceFlowLifeCycle<?, ?> createSourceFlowLifeCycle(
SourceAction<?, ?, ?> sourceAction,
SourceConfig config,
CompletableFuture<Void> completableFuture,
MetricsContext metricsContext) {
return new SourceFlowLifeCycle<>(
sourceAction,
indexID,
config.getEnumeratorTask(),
this,
taskLocation,
completableFuture,
metricsContext);
}
@Override
public void init() throws Exception {
super.init();
this.checkpointLock = new Object();
this.splitSerializer = sourceFlow.getAction().getSource().getSplitSerializer();
LOGGER.info("starting seatunnel source task, index " + indexID);
if (!(startFlowLifeCycle instanceof SourceFlowLifeCycle)) {
throw new TaskRuntimeException(
"SourceSeaTunnelTask only support SourceFlowLifeCycle, but get "
+ startFlowLifeCycle.getClass().getName());
} else {
SeaTunnelDataType sourceProducedType;
List<TablePath> tablePaths = new ArrayList<>();
try {
List<CatalogTable> producedCatalogTables =
sourceFlow.getAction().getSource().getProducedCatalogTables();
sourceProducedType = CatalogTableUtil.convertToDataType(producedCatalogTables);
tablePaths =
producedCatalogTables.stream()
.map(CatalogTable::getTableId)
.map(TableIdentifier::toTablePath)
.collect(Collectors.toList());
} catch (UnsupportedOperationException e) {
// TODO remove it when all connector use `getProducedCatalogTables`
sourceProducedType = sourceFlow.getAction().getSource().getProducedType();
}
this.collector =
new SeaTunnelSourceCollector<>(
checkpointLock,
outputs,
this.getMetricsContext(),
FlowControlStrategy.fromMap(envOption),
sourceProducedType,
tablePaths);
((SourceFlowLifeCycle<T, SplitT>) startFlowLifeCycle).setCollector(collector);
}
}
初始化方法也是先调用父类的初始化方法,一并放到后面再看。 其他的内容则是通过调用Source的API获取到所产生数据的表结构,数据类型,表路径信息等。 在这里还会初始化一个SeaTunnelSourceCollector,并赋值给startFlowLifeCycle. 我们看下这个类的相关代码
SeaTunnelSourceCollector
public class SeaTunnelSourceCollector<T> implements Collector<T> {
private final Object checkpointLock;
private final List<OneInputFlowLifeCycle<Record<?>>> outputs;
private final MetricsContext metricsContext;
private final AtomicBoolean schemaChangeBeforeCheckpointSignal = new AtomicBoolean(false);
private final AtomicBoolean schemaChangeAfterCheckpointSignal = new AtomicBoolean(false);
private final Counter sourceReceivedCount;
private final Map<String, Counter> sourceReceivedCountPerTable = new ConcurrentHashMap<>();
private final Meter sourceReceivedQPS;
private final Counter sourceReceivedBytes;
private final Meter sourceReceivedBytesPerSeconds;
private volatile boolean emptyThisPollNext;
private final DataTypeChangeEventHandler dataTypeChangeEventHandler =
new DataTypeChangeEventDispatcher();
private Map<String, SeaTunnelRowType> rowTypeMap = new HashMap<>();
private SeaTunnelDataType rowType;
private FlowControlGate flowControlGate;
public SeaTunnelSourceCollector(
Object checkpointLock,
List<OneInputFlowLifeCycle<Record<?>>> outputs,
MetricsContext metricsContext,
FlowControlStrategy flowControlStrategy,
SeaTunnelDataType rowType,
List<TablePath> tablePaths) {
this.checkpointLock = checkpointLock;
this.outputs = outputs;
this.rowType = rowType;
this.metricsContext = metricsContext;
if (rowType instanceof MultipleRowType) {
((MultipleRowType) rowType)
.iterator()
.forEachRemaining(type -> this.rowTypeMap.put(type.getKey(), type.getValue()));
}
if (CollectionUtils.isNotEmpty(tablePaths)) {
tablePaths.forEach(
tablePath ->
sourceReceivedCountPerTable.put(
getFullName(tablePath),
metricsContext.counter(
SOURCE_RECEIVED_COUNT + "#" + getFullName(tablePath))));
}
sourceReceivedCount = metricsContext.counter(SOURCE_RECEIVED_COUNT);
sourceReceivedQPS = metricsContext.meter(SOURCE_RECEIVED_QPS);
sourceReceivedBytes = metricsContext.counter(SOURCE_RECEIVED_BYTES);
sourceReceivedBytesPerSeconds = metricsContext.meter(SOURCE_RECEIVED_BYTES_PER_SECONDS);
flowControlGate = FlowControlGate.create(flowControlStrategy);
}
从变量可以看到这个类里面是实现了指标的统计,从source读到了多少数据,平均每秒读取的速度等都是在这个类中维护计算的。 还有记录了该任务下游的任务列表List<OneInputFlowLifeCycle<Record<?>>> outputs
在构造方法中,则是一些指标的初始化。
再看下这个类中的关键方法: collect
@Override
public void collect(T row) {
try {
if (row instanceof SeaTunnelRow) {
String tableId = ((SeaTunnelRow) row).getTableId();
int size;
if (rowType instanceof SeaTunnelRowType) {
size = ((SeaTunnelRow) row).getBytesSize((SeaTunnelRowType) rowType);
} else if (rowType instanceof MultipleRowType) {
size = ((SeaTunnelRow) row).getBytesSize(rowTypeMap.get(tableId));
} else {
throw new SeaTunnelEngineException(
"Unsupported row type: " + rowType.getClass().getName());
}
sourceReceivedBytes.inc(size);
sourceReceivedBytesPerSeconds.markEvent(size);
flowControlGate.audit((SeaTunnelRow) row);
if (StringUtils.isNotEmpty(tableId)) {
String tableName = getFullName(TablePath.of(tableId));
Counter sourceTableCounter = sourceReceivedCountPerTable.get(tableName);
if (Objects.nonNull(sourceTableCounter)) {
sourceTableCounter.inc();
} else {
Counter counter =
metricsContext.counter(SOURCE_RECEIVED_COUNT + "#" + tableName);
counter.inc();
sourceReceivedCountPerTable.put(tableName, counter);
}
}
}
sendRecordToNext(new Record<>(row));
emptyThisPollNext = false;
sourceReceivedCount.inc();
sourceReceivedQPS.markEvent();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Override
public void collect(SchemaChangeEvent event) {
try {
if (rowType instanceof SeaTunnelRowType) {
rowType = dataTypeChangeEventHandler.reset((SeaTunnelRowType) rowType).apply(event);
} else if (rowType instanceof MultipleRowType) {
String tableId = event.tablePath().toString();
rowTypeMap.put(
tableId,
dataTypeChangeEventHandler.reset(rowTypeMap.get(tableId)).apply(event));
} else {
throw new SeaTunnelEngineException(
"Unsupported row type: " + rowType.getClass().getName());
}
sendRecordToNext(new Record<>(event));
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
在这个类中有两个collect方法,一个是接收数据,一个是接收表结构变更事件。 对于接收数据方法,当数据是读取到的数据SeaTunnelRow时,则会进行一些指标计算,更新。然后调用sendRecordToNext方法,将数据封装为Record发送给下游。
对于表结构变更方法,则是先将内部存储的表结构信息进行更新,然后再同样是调用sendRecordToNext方法发送给下游.
public void sendRecordToNext(Record<?> record) throws IOException {
synchronized (checkpointLock) {
for (OneInputFlowLifeCycle<Record<?>> output : outputs) {
output.received(record);
}
}
}
在这个方法中,则是将数据发送给全部的下游任务。这里如何获取的下游任务是在父类中获取的,这一部分后面在SeaTunnelTask中再继续介绍。
可以看出这个SeaTunnelSourceCollector会被传递给reader实例,reader读取到数据转换完成之后,再由这个类进行指标统计后发送给所有的下游任务。
TransformSeaTunnelTask
public class TransformSeaTunnelTask extends SeaTunnelTask {
private static final ILogger LOGGER = Logger.getLogger(TransformSeaTunnelTask.class);
public TransformSeaTunnelTask(
long jobID, TaskLocation taskID, int indexID, Flow executionFlow) {
super(jobID, taskID, indexID, executionFlow);
}
private Collector<Record<?>> collector;
@Override
public void init() throws Exception {
super.init();
LOGGER.info("starting seatunnel transform task, index " + indexID);
collector = new SeaTunnelTransformCollector(outputs);
if (!(startFlowLifeCycle instanceof OneOutputFlowLifeCycle)) {
throw new TaskRuntimeException(
"TransformSeaTunnelTask only support OneOutputFlowLifeCycle, but get "
+ startFlowLifeCycle.getClass().getName());
}
}
@Override
protected SourceFlowLifeCycle<?, ?> createSourceFlowLifeCycle(
SourceAction<?, ?, ?> sourceAction,
SourceConfig config,
CompletableFuture<Void> completableFuture,
MetricsContext metricsContext) {
throw new UnsupportedOperationException(
"TransformSeaTunnelTask can't create SourceFlowLifeCycle");
}
@Override
protected void collect() throws Exception {
((OneOutputFlowLifeCycle<Record<?>>) startFlowLifeCycle).collect(collector);
}
@NonNull @Override
public ProgressState call() throws Exception {
stateProcess();
return progress.toState();
}
}
这个类相比较于SourceSeaTunnelTask则比较简单,在初始化时会创建一个SeaTunnelTransformCollector,当调用collect方法时也是转交给startFlowLifeCycle执行
SeaTunnelTransformCollector
public class SeaTunnelTransformCollector implements Collector<Record<?>> {
private final List<OneInputFlowLifeCycle<Record<?>>> outputs;
public SeaTunnelTransformCollector(List<OneInputFlowLifeCycle<Record<?>>> outputs) {
this.outputs = outputs;
}
@Override
public void collect(Record<?> record) {
for (OneInputFlowLifeCycle<Record<?>> output : outputs) {
try {
output.received(record);
} catch (IOException e) {
throw new TaskRuntimeException(e);
}
}
}
@Override
public void close() {}
}
SeaTunnelTransformCollector的内容也很简单,收到数据后将数据转发给所有的下游任务。
好了,接下来我们看下SeaTunnelTask的相关内容
SeaTunnelTask
public abstract class SeaTunnelTask extends AbstractTask {
private static final long serialVersionUID = 2604309561613784425L;
protected volatile SeaTunnelTaskState currState;
private final Flow executionFlow;
protected FlowLifeCycle startFlowLifeCycle;
protected List<FlowLifeCycle> allCycles;
protected List<OneInputFlowLifeCycle<Record<?>>> outputs;
protected List<CompletableFuture<Void>> flowFutures;
protected final Map<Long, List<ActionSubtaskState>> checkpointStates =
new ConcurrentHashMap<>();
private final Map<Long, Integer> cycleAcks = new ConcurrentHashMap<>();
protected int indexID;
private TaskGroup taskBelongGroup;
private SeaTunnelMetricsContext metricsContext;
public SeaTunnelTask(long jobID, TaskLocation taskID, int indexID, Flow executionFlow) {
super(jobID, taskID);
this.indexID = indexID;
this.executionFlow = executionFlow;
this.currState = SeaTunnelTaskState.CREATED;
}
...
}
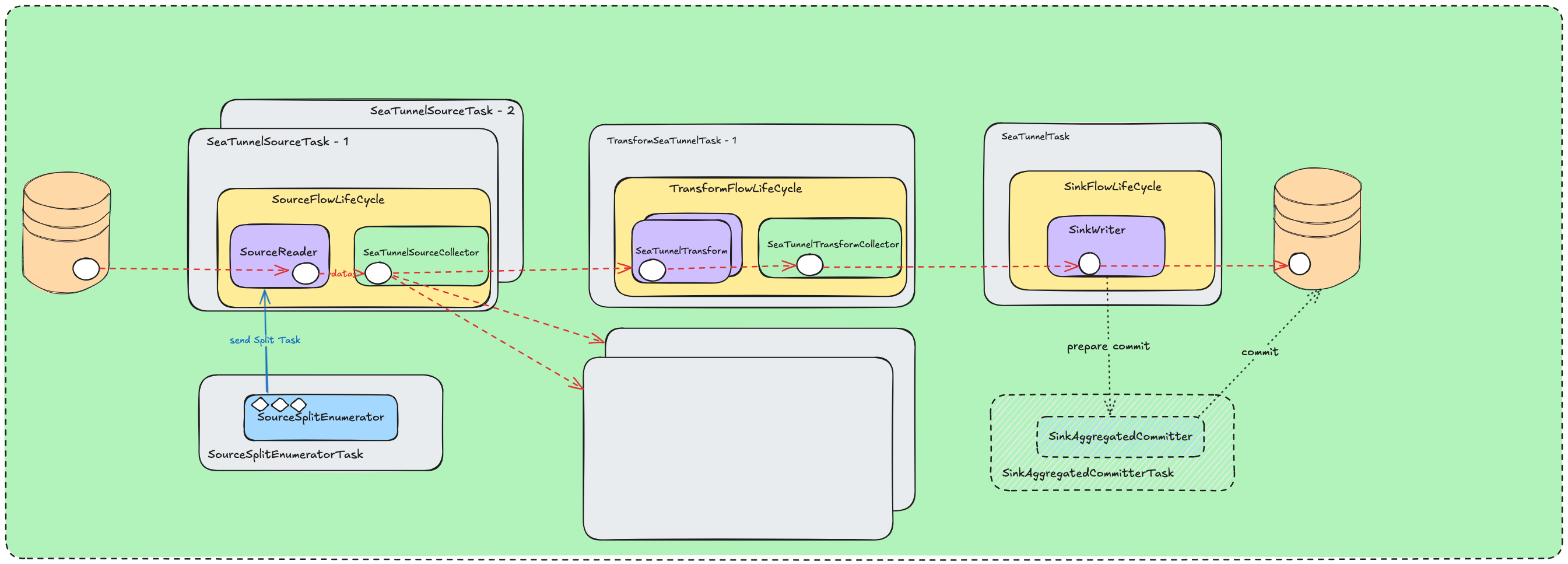
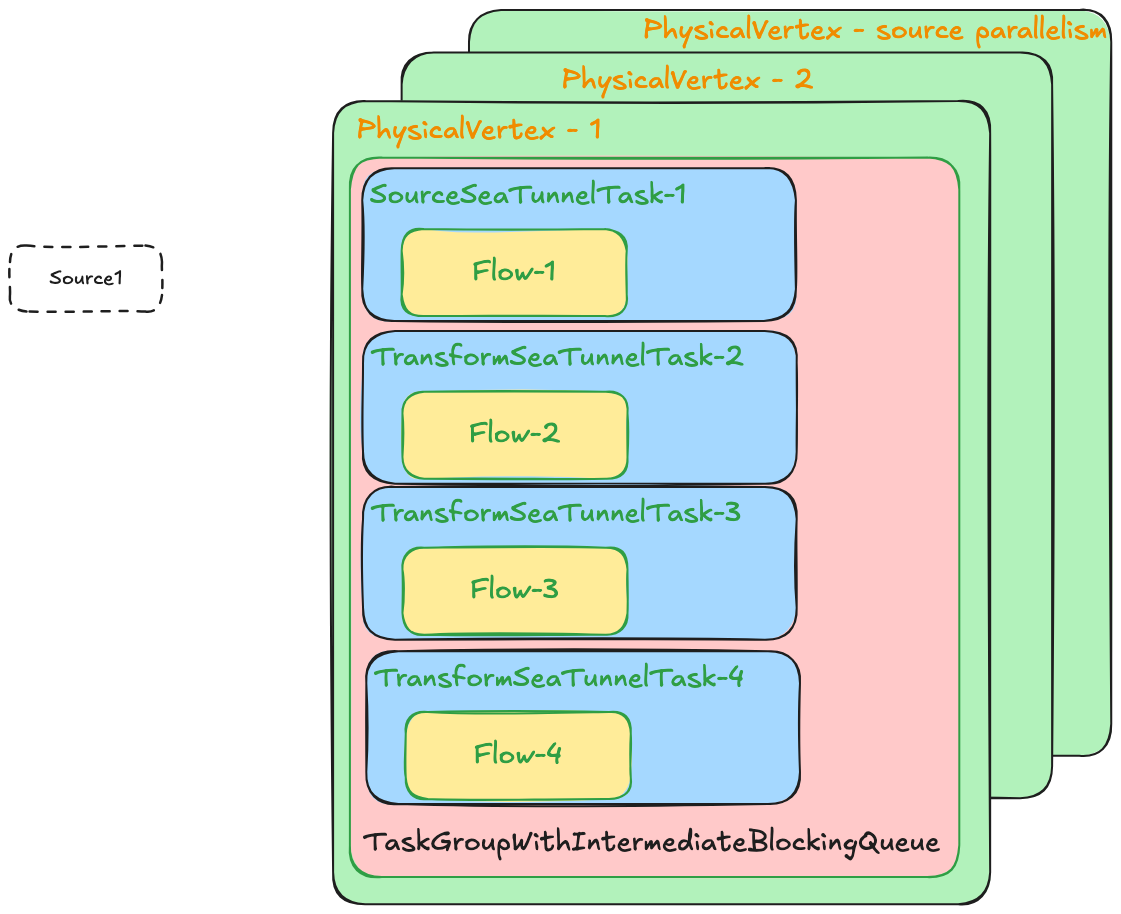
在SeaTunnelTask中,executionFlow就表示一个物理执行节点,是在PhysicalPlanGenerator中产生传递过来的。这里需要与执行计划图一起对比看下。 ![image.png]()
在构造方法中没有做太多的事情,仅仅是将变量赋值,将状态初始化为CREATED状态。 看下其他的方法
@Override
public void init() throws Exception {
super.init();
metricsContext = getExecutionContext().getOrCreateMetricsContext(taskLocation);
this.currState = SeaTunnelTaskState.INIT;
flowFutures = new ArrayList<>();
allCycles = new ArrayList<>();
startFlowLifeCycle = convertFlowToActionLifeCycle(executionFlow);
for (FlowLifeCycle cycle : allCycles) {
cycle.init();
}
CompletableFuture.allOf(flowFutures.toArray(new CompletableFuture[0]))
.whenComplete((s, e) -> closeCalled = true);
}
初始化方法内,调用了convertFlowToActionLifeCycle方法来获取当前任务的开始任务的lifecycle对象。
private FlowLifeCycle convertFlowToActionLifeCycle(@NonNull Flow flow) throws Exception {
FlowLifeCycle lifeCycle;
// 局部变量存储当前节点的所有下游节点的lifecycle对象
List<OneInputFlowLifeCycle<Record<?>>> flowLifeCycles = new ArrayList<>();
if (!flow.getNext().isEmpty()) {
for (Flow f : flow.getNext()) {
flowLifeCycles.add(
// 递归调用 将所有节点都进行转换
(OneInputFlowLifeCycle<Record<?>>) convertFlowToActionLifeCycle(f));
}
}
CompletableFuture<Void> completableFuture = new CompletableFuture<>();
// 加到全部变量中
flowFutures.add(completableFuture);
if (flow instanceof PhysicalExecutionFlow) {
PhysicalExecutionFlow f = (PhysicalExecutionFlow) flow;
// 根据不同的action类型创建不同的 FlowLifecycle
if (f.getAction() instanceof SourceAction) {
lifeCycle =
createSourceFlowLifeCycle(
(SourceAction<?, ?, ?>) f.getAction(),
(SourceConfig) f.getConfig(),
completableFuture,
this.getMetricsContext());
// 当前节点的下游输出已经存储在 flowLifeCycles中了,赋值
outputs = flowLifeCycles;
} else if (f.getAction() instanceof SinkAction) {
lifeCycle =
new SinkFlowLifeCycle<>(
(SinkAction) f.getAction(),
taskLocation,
indexID,
this,
((SinkConfig) f.getConfig()).getCommitterTask(),
((SinkConfig) f.getConfig()).isContainCommitter(),
completableFuture,
this.getMetricsContext());
// sink已经是最后的节点,所以不需要设置outputs
} else if (f.getAction() instanceof TransformChainAction) {
// 对于transform,outputs通过在构造`SeaTunnelTransformCollector`时通过参数传递进入
lifeCycle =
new TransformFlowLifeCycle<SeaTunnelRow>(
(TransformChainAction) f.getAction(),
this,
new SeaTunnelTransformCollector(flowLifeCycles),
completableFuture);
} else if (f.getAction() instanceof ShuffleAction) {
ShuffleAction shuffleAction = (ShuffleAction) f.getAction();
HazelcastInstance hazelcastInstance = getExecutionContext().getInstance();
if (flow.getNext().isEmpty()) {
lifeCycle =
new ShuffleSinkFlowLifeCycle(
this,
indexID,
shuffleAction,
hazelcastInstance,
completableFuture);
} else {
lifeCycle =
new ShuffleSourceFlowLifeCycle(
this,
indexID,
shuffleAction,
hazelcastInstance,
completableFuture);
}
outputs = flowLifeCycles;
} else {
throw new UnknownActionException(f.getAction());
}
} else if (flow instanceof IntermediateExecutionFlow) {
IntermediateQueueConfig config =
((IntermediateExecutionFlow<IntermediateQueueConfig>) flow).getConfig();
lifeCycle =
new IntermediateQueueFlowLifeCycle(
this,
completableFuture,
((AbstractTaskGroupWithIntermediateQueue) taskBelongGroup)
.getQueueCache(config.getQueueID()));
outputs = flowLifeCycles;
} else {
throw new UnknownFlowException(flow);
}
allCycles.add(lifeCycle);
return lifeCycle;
}
在这个方法中,对一个物理执行节点进行遍历,对每一个下游任务都进行转换,转换为对于的FlowLifecycle,然后将其添加到全部变量allCycles中。 在转换FlowLifecycle 时,会根据不同的类型进行相应的转换。并且在每次转换时,都可以获取到当前节点的下游所有节点的LifeCycle,可以将其设置到output中,从而在Collector中发送的时候可以知道下游的信息。 这里的PhysicalExecutionFlow与IntermediateExecutionFlow区别我们先不关心,我们先认为都只有PhysicalExecutionFlow。
回到init方法,当全部转换完成后,会对所有的FlowLifecycle调用初始化方法进行初始化
@Override
public void init() throws Exception {
super.init();
metricsContext = getExecutionContext().getOrCreateMetricsContext(taskLocation);
this.currState = SeaTunnelTaskState.INIT;
flowFutures = new ArrayList<>();
allCycles = new ArrayList<>();
startFlowLifeCycle = convertFlowToActionLifeCycle(executionFlow);
for (FlowLifeCycle cycle : allCycles) {
cycle.init();
}
CompletableFuture.allOf(flowFutures.toArray(new CompletableFuture[0]))
.whenComplete((s, e) -> closeCalled = true);
}
我们对其中提到的几个FlowLifyCycle看下源码
SourceFlowLifeCycle
public class SourceFlowLifeCycle<T, SplitT extends SourceSplit> extends ActionFlowLifeCycle
implements InternalCheckpointListener {
private final SourceAction<T, SplitT, ?> sourceAction;
private final TaskLocation enumeratorTaskLocation;
private Address enumeratorTaskAddress;
private SourceReader<T, SplitT> reader;
private transient Serializer<SplitT> splitSerializer;
private final int indexID;
private final TaskLocation currentTaskLocation;
private SeaTunnelSourceCollector<T> collector;
private final MetricsContext metricsContext;
private final EventListener eventListener;
private final AtomicReference<SchemaChangePhase> schemaChangePhase = new AtomicReference<>();
public SourceFlowLifeCycle(
SourceAction<T, SplitT, ?> sourceAction,
int indexID,
TaskLocation enumeratorTaskLocation,
SeaTunnelTask runningTask,
TaskLocation currentTaskLocation,
CompletableFuture<Void> completableFuture,
MetricsContext metricsContext) {
super(sourceAction, runningTask, completableFuture);
this.sourceAction = sourceAction;
this.indexID = indexID;
this.enumeratorTaskLocation = enumeratorTaskLocation;
this.currentTaskLocation = currentTaskLocation;
this.metricsContext = metricsContext;
this.eventListener =
new JobEventListener(currentTaskLocation, runningTask.getExecutionContext());
}
}
在这个类的几个成员变量有source enumerator的地址,用来reader与enumerator进行通信交互,还有SourceReader的实例,在这个类里去创建reader并进行实际的读取。
再来看下其他的方法:
@Override
public void init() throws Exception {
this.splitSerializer = sourceAction.getSource().getSplitSerializer();
this.reader =
sourceAction
.getSource()
.createReader(
new SourceReaderContext(
indexID,
sourceAction.getSource().getBoundedness(),
this,
metricsContext,
eventListener));
this.enumeratorTaskAddress = getEnumeratorTaskAddress();
}
初始化时会去创建reader实例,创建时会将自身作为参数设置到context中。还要去获取切分任务的地址,后续的通信需要这个地址。
public void collect() throws Exception {
if (!prepareClose) {
if (schemaChanging()) {
log.debug("schema is changing, stop reader collect records");
Thread.sleep(200);
return;
}
reader.pollNext(collector);
if (collector.isEmptyThisPollNext()) {
Thread.sleep(100);
} else {
collector.resetEmptyThisPollNext();
Thread.sleep(0L);
}
if (collector.captureSchemaChangeBeforeCheckpointSignal()) {
if (schemaChangePhase.get() != null) {
throw new IllegalStateException(
"previous schema changes in progress, schemaChangePhase: "
+ schemaChangePhase.get());
}
schemaChangePhase.set(SchemaChangePhase.createBeforePhase());
runningTask.triggerSchemaChangeBeforeCheckpoint().get();
log.info("triggered schema-change-before checkpoint, stopping collect data");
} else if (collector.captureSchemaChangeAfterCheckpointSignal()) {
if (schemaChangePhase.get() != null) {
throw new IllegalStateException(
"previous schema changes in progress, schemaChangePhase: "
+ schemaChangePhase.get());
}
schemaChangePhase.set(SchemaChangePhase.createAfterPhase());
runningTask.triggerSchemaChangeAfterCheckpoint().get();
log.info("triggered schema-change-after checkpoint, stopping collect data");
}
} else {
Thread.sleep(100);
}
}
当调用collect方法时,会调用reader的pollNext方法来进行真正的数据读取。 当reader的pollNext方法被调用时,reader会真正的从数据源进行读取数据,转换成内部的SeaTunnelRow数据类型,放到collector中。 而这个collector就是我们上面刚刚看的SeaTunnelSourceCollector, 当它接收到一条数据后,又会将数据发送给所有的下游任务。
@Override
public void open() throws Exception {
reader.open();
// 在open方法里,会将自己向enumerator进行注册
register();
}
private void register() {
try {
runningTask
.getExecutionContext()
.sendToMember(
new SourceRegisterOperation(
currentTaskLocation, enumeratorTaskLocation),
enumeratorTaskAddress)
.get();
} catch (InterruptedException | ExecutionException e) {
log.warn("source register failed.", e);
throw new RuntimeException(e);
}
}
@Override
public void close() throws IOException {
reader.close();
super.close();
}
// 当reader读取完全部数据后,会调用此方法
// 此方法会向enumerator发送消息
public void signalNoMoreElement() {
// ready close this reader
try {
this.prepareClose = true;
runningTask
.getExecutionContext()
.sendToMember(
new SourceNoMoreElementOperation(
currentTaskLocation, enumeratorTaskLocation),
enumeratorTaskAddress)
.get();
} catch (Exception e) {
log.warn("source close failed {}", e);
throw new RuntimeException(e);
}
}
public void requestSplit() {
try {
runningTask
.getExecutionContext()
.sendToMember(
new RequestSplitOperation(currentTaskLocation, enumeratorTaskLocation),
enumeratorTaskAddress)
.get();
} catch (InterruptedException | ExecutionException e) {
log.warn("source request split failed.", e);
throw new RuntimeException(e);
}
}
public void sendSourceEventToEnumerator(SourceEvent sourceEvent) {
try {
runningTask
.getExecutionContext()
.sendToMember(
new SourceReaderEventOperation(
enumeratorTaskLocation, currentTaskLocation, sourceEvent),
enumeratorTaskAddress)
.get();
} catch (InterruptedException | ExecutionException e) {
log.warn("source request split failed.", e);
throw new RuntimeException(e);
}
}
public void receivedSplits(List<SplitT> splits) {
if (splits.isEmpty()) {
reader.handleNoMoreSplits();
} else {
reader.addSplits(splits);
}
}
TransformFlowLifeCycle
public class TransformFlowLifeCycle<T> extends ActionFlowLifeCycle
implements OneInputFlowLifeCycle<Record<?>> {
private final TransformChainAction<T> action;
private final List<SeaTunnelTransform<T>> transform;
private final Collector<Record<?>> collector;
public TransformFlowLifeCycle(
TransformChainAction<T> action,
SeaTunnelTask runningTask,
Collector<Record<?>> collector,
CompletableFuture<Void> completableFuture) {
super(action, runningTask, completableFuture);
this.action = action;
this.transform = action.getTransforms();
this.collector = collector;
}
@Override
public void open() throws Exception {
super.open();
for (SeaTunnelTransform<T> t : transform) {
try {
t.open();
} catch (Exception e) {
log.error(
"Open transform: {} failed, cause: {}",
t.getPluginName(),
e.getMessage(),
e);
}
}
}
@Override
public void received(Record<?> record) {
if (record.getData() instanceof Barrier) {
CheckpointBarrier barrier = (CheckpointBarrier) record.getData();
if (barrier.prepareClose(this.runningTask.getTaskLocation())) {
prepareClose = true;
}
if (barrier.snapshot()) {
runningTask.addState(barrier, ActionStateKey.of(action), Collections.emptyList());
}
// ack after #addState
runningTask.ack(barrier);
collector.collect(record);
} else {
if (prepareClose) {
return;
}
T inputData = (T) record.getData();
T outputData = inputData;
for (SeaTunnelTransform<T> t : transform) {
outputData = t.map(inputData);
log.debug("Transform[{}] input row {} and output row {}", t, inputData, outputData);
if (outputData == null) {
log.trace("Transform[{}] filtered data row {}", t, inputData);
break;
}
inputData = outputData;
}
if (outputData != null) {
// todo log metrics
collector.collect(new Record<>(outputData));
}
}
}
...
}
在TransformFlowLifeCycle中,存储了所需要用到的SeaTunnelTransform,当被调用open方法时,会调用具体使用到的transform实现的open方法,由该实现进行相关的一些初始化操作。 当接收到数据后,会调用Transform接口的map方法,对数据进行处理,处理完成后,会判断是否会被过滤掉,如果没有被过滤(数据不为null)则会发送给下游。
SinkFlowLifeCycle
public class SinkFlowLifeCycle<T, CommitInfoT extends Serializable, AggregatedCommitInfoT, StateT>
extends ActionFlowLifeCycle
implements OneInputFlowLifeCycle<Record<?>>, InternalCheckpointListener {
private final SinkAction<T, StateT, CommitInfoT, AggregatedCommitInfoT> sinkAction;
private SinkWriter<T, CommitInfoT, StateT> writer;
private transient Optional<Serializer<CommitInfoT>> commitInfoSerializer;
private transient Optional<Serializer<StateT>> writerStateSerializer;
private final int indexID;
private final TaskLocation taskLocation;
private Address committerTaskAddress;
private final TaskLocation committerTaskLocation;
private Optional<SinkCommitter<CommitInfoT>> committer;
private Optional<CommitInfoT> lastCommitInfo;
private MetricsContext metricsContext;
private Counter sinkWriteCount;
private Map<String, Counter> sinkWriteCountPerTable = new ConcurrentHashMap<>();
private Meter sinkWriteQPS;
private Counter sinkWriteBytes;
private Meter sinkWriteBytesPerSeconds;
private final boolean containAggCommitter;
private MultiTableResourceManager resourceManager;
private EventListener eventListener;
public SinkFlowLifeCycle(
SinkAction<T, StateT, CommitInfoT, AggregatedCommitInfoT> sinkAction,
TaskLocation taskLocation,
int indexID,
SeaTunnelTask runningTask,
TaskLocation committerTaskLocation,
boolean containAggCommitter,
CompletableFuture<Void> completableFuture,
MetricsContext metricsContext) {
super(sinkAction, runningTask, completableFuture);
this.sinkAction = sinkAction;
this.indexID = indexID;
this.taskLocation = taskLocation;
this.committerTaskLocation = committerTaskLocation;
this.containAggCommitter = containAggCommitter;
this.metricsContext = metricsContext;
this.eventListener = new JobEventListener(taskLocation, runningTask.getExecutionContext());
sinkWriteCount = metricsContext.counter(SINK_WRITE_COUNT);
sinkWriteQPS = metricsContext.meter(SINK_WRITE_QPS);
sinkWriteBytes = metricsContext.counter(SINK_WRITE_BYTES);
sinkWriteBytesPerSeconds = metricsContext.meter(SINK_WRITE_BYTES_PER_SECONDS);
if (sinkAction.getSink() instanceof MultiTableSink) {
List<TablePath> sinkTables = ((MultiTableSink) sinkAction.getSink()).getSinkTables();
sinkTables.forEach(
tablePath ->
sinkWriteCountPerTable.put(
getFullName(tablePath),
metricsContext.counter(
SINK_WRITE_COUNT + "#" + getFullName(tablePath))));
}
}
...
}
与SourceFlowLifeCycle类似,这个SinkFlowLifeCycle中维护了SinkWriter的实例,当接收到一条数据后,会交给writer的具体实现来进行真正的数据写入。 同时在这个类中维护了一些指标数据,会进行写入数据,每个表写入数据等指标的统计。
接下来看下其他的一些方法
@Override
public void init() throws Exception {
this.commitInfoSerializer = sinkAction.getSink().getCommitInfoSerializer();
this.writerStateSerializer = sinkAction.getSink().getWriterStateSerializer();
this.committer = sinkAction.getSink().createCommitter();
this.lastCommitInfo = Optional.empty();
}
@Override
public void open() throws Exception {
super.open();
if (containAggCommitter) {
committerTaskAddress = getCommitterTaskAddress();
}
registerCommitter();
}
private void registerCommitter() {
if (containAggCommitter) {
runningTask
.getExecutionContext()
.sendToMember(
new SinkRegisterOperation(taskLocation, committerTaskLocation),
committerTaskAddress)
.join();
}
}
在初始化方法中,会创建committer,通过API可以知道,committer并不是一定需要的,所以这里的值也有可能为空,在open方法中当存在committer时,会获取地址然后进行注册。
这里有一点与SourceFlowLifeCycle不同的点是, SourceReader的创建是在init方法中去创建的
@Override
public void init() throws Exception {
this.splitSerializer = sourceAction.getSource().getSplitSerializer();
this.reader =
sourceAction
.getSource()
.createReader(
new SourceReaderContext(
indexID,
sourceAction.getSource().getBoundedness(),
this,
metricsContext,
eventListener));
this.enumeratorTaskAddress = getEnumeratorTaskAddress();
}
但是在这里SinkWriter的创建并没有在这里去创建。查看代码之后发现是在restoreState这个方法中进行创建的
public void restoreState(List<ActionSubtaskState> actionStateList) throws Exception {
List<StateT> states = new ArrayList<>();
if (writerStateSerializer.isPresent()) {
states =
actionStateList.stream()
.map(ActionSubtaskState::getState)
.flatMap(Collection::stream)
.filter(Objects::nonNull)
.map(
bytes ->
sneaky(
() ->
writerStateSerializer
.get()
.deserialize(bytes)))
.collect(Collectors.toList());
}
if (states.isEmpty()) {
this.writer =
sinkAction
.getSink()
.createWriter(
new SinkWriterContext(indexID, metricsContext, eventListener));
} else {
this.writer =
sinkAction
.getSink()
.restoreWriter(
new SinkWriterContext(indexID, metricsContext, eventListener),
states);
}
if (this.writer instanceof SupportResourceShare) {
resourceManager =
((SupportResourceShare) this.writer).initMultiTableResourceManager(1, 1);
((SupportResourceShare) this.writer).setMultiTableResourceManager(resourceManager, 0);
}
}
至于这个方法什么时候会被调用,会在下面任务状态转换的时候在介绍。
public void received(Record<?> record) {
try {
if (record.getData() instanceof Barrier) {
long startTime = System.currentTimeMillis();
Barrier barrier = (Barrier) record.getData();
if (barrier.prepareClose(this.taskLocation)) {
prepareClose = true;
}
if (barrier.snapshot()) {
try {
lastCommitInfo = writer.prepareCommit();
} catch (Exception e) {
writer.abortPrepare();
throw e;
}
List<StateT> states = writer.snapshotState(barrier.getId());
if (!writerStateSerializer.isPresent()) {
runningTask.addState(
barrier, ActionStateKey.of(sinkAction), Collections.emptyList());
} else {
runningTask.addState(
barrier,
ActionStateKey.of(sinkAction),
serializeStates(writerStateSerializer.get(), states));
}
if (containAggCommitter) {
CommitInfoT commitInfoT = null;
if (lastCommitInfo.isPresent()) {
commitInfoT = lastCommitInfo.get();
}
runningTask
.getExecutionContext()
.sendToMember(
new SinkPrepareCommitOperation<CommitInfoT>(
barrier,
committerTaskLocation,
commitInfoSerializer.isPresent()
? commitInfoSerializer
.get()
.serialize(commitInfoT)
: null),
committerTaskAddress)
.join();
}
} else {
if (containAggCommitter) {
runningTask
.getExecutionContext()
.sendToMember(
new BarrierFlowOperation(barrier, committerTaskLocation),
committerTaskAddress)
.join();
}
}
runningTask.ack(barrier);
log.debug(
"trigger barrier [{}] finished, cost {}ms. taskLocation [{}]",
barrier.getId(),
System.currentTimeMillis() - startTime,
taskLocation);
} else if (record.getData() instanceof SchemaChangeEvent) {
if (prepareClose) {
return;
}
SchemaChangeEvent event = (SchemaChangeEvent) record.getData();
writer.applySchemaChange(event);
} else {
if (prepareClose) {
return;
}
writer.write((T) record.getData());
sinkWriteCount.inc();
sinkWriteQPS.markEvent();
if (record.getData() instanceof SeaTunnelRow) {
long size = ((SeaTunnelRow) record.getData()).getBytesSize();
sinkWriteBytes.inc(size);
sinkWriteBytesPerSeconds.markEvent(size);
String tableId = ((SeaTunnelRow) record.getData()).getTableId();
if (StringUtils.isNotBlank(tableId)) {
String tableName = getFullName(TablePath.of(tableId));
Counter sinkTableCounter = sinkWriteCountPerTable.get(tableName);
if (Objects.nonNull(sinkTableCounter)) {
sinkTableCounter.inc();
} else {
Counter counter =
metricsContext.counter(SINK_WRITE_COUNT + "#" + tableName);
counter.inc();
sinkWriteCountPerTable.put(tableName, counter);
}
}
}
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
在接收数据的方法中,会对数据进行一些判断,会进行这几种类型的判断
- 是否是snapshot 当触发snapshot时,会产生预提交信息,这个信息后面会在提交时使用 以及调用writer的snapshot方法,将现在的状态进行存储,从而在后面恢复时可以根据当前状态进行恢复。 然后再判断是否有committer的存在,如果有,则向其发送消息,让其根据刚刚产生的commit信息进行预提交。
- 是否是表结构变更的事件 当接收到表结构变更事件,也直接调用writer的相关方法,交由writer去实现
- 其他情况下 调用
writer.writer()方法,进行真正的数据写入。并进行一些数据统计。
这个地方只是将数据交给了具体的writer实现,至于writer有没有实时的将数据写入到具体的存储里面,也是根据连接器的实现来决定,有些连接器可能为了性能考虑会将数据进行攒批或者其他策略来进行发送写入,那么这里的调用与真正的数据写入还是会有一定的延迟的。
@Override
public void notifyCheckpointComplete(long checkpointId) throws Exception {
if (committer.isPresent() && lastCommitInfo.isPresent()) {
committer.get().commit(Collections.singletonList(lastCommitInfo.get()));
}
}
@Override
public void notifyCheckpointAborted(long checkpointId) throws Exception {
if (committer.isPresent() && lastCommitInfo.isPresent()) {
committer.get().abort(Collections.singletonList(lastCommitInfo.get()));
}
}
这两个方法是checkpoint的成功与失败的方法,当成功时,如果committer存在,则进行真正的提交操作。否则则回滚这次提交。
IntermediateQueueFlowLifeCycle
![image.png]() 在生成任务时, 会在任务之间添加
在生成任务时, 会在任务之间添加IntermediateExecutionFlow来进行切分. 一个IntermediateExecutionFlow的Flow, 在生成lifeCycle阶段, 会生成一个IntermediateQueueFlowLifeCycle
else if (flow instanceof IntermediateExecutionFlow) {
IntermediateQueueConfig config =
((IntermediateExecutionFlow<IntermediateQueueConfig>) flow).getConfig();
lifeCycle =
new IntermediateQueueFlowLifeCycle(
this,
completableFuture,
((AbstractTaskGroupWithIntermediateQueue) taskBelongGroup)
.getQueueCache(config.getQueueID()));
outputs = flowLifeCycles;
}
来看一下IntermediateQueueFlowLifeCycle的代码
public class IntermediateQueueFlowLifeCycle<T extends AbstractIntermediateQueue<?>>
extends AbstractFlowLifeCycle
implements OneInputFlowLifeCycle<Record<?>>, OneOutputFlowLifeCycle<Record<?>> {
private final AbstractIntermediateQueue<?> queue;
public IntermediateQueueFlowLifeCycle(
SeaTunnelTask runningTask,
CompletableFuture<Void> completableFuture,
AbstractIntermediateQueue<?> queue) {
super(runningTask, completableFuture);
this.queue = queue;
queue.setIntermediateQueueFlowLifeCycle(this);
queue.setRunningTask(runningTask);
}
@Override
public void received(Record<?> record) {
queue.received(record);
}
@Override
public void collect(Collector<Record<?>> collector) throws Exception {
queue.collect(collector);
}
@Override
public void close() throws IOException {
queue.close();
super.close();
}
}
在这个里面有一个成员变量AbstractIntermediateQueue, 在初始化时会传递过来, 当被调用received或collect时, 都会调用AbstractIntermediateQueue的相应方法.
状态切换
protected void stateProcess() throws Exception {
switch (currState) {
// 当调用init方法时,都会将任务的状态置为INIT
case INIT:
// 切换为WAITING_RESTORE
currState = WAITING_RESTORE;
// 报告任务的状态为WAITING_RESTORE
reportTaskStatus(WAITING_RESTORE);
break;
case WAITING_RESTORE:
// 当init方法执行结束后,会对所有的下游任务调用open方法
if (restoreComplete.isDone()) {
for (FlowLifeCycle cycle : allCycles) {
cycle.open();
}
// 切换为READY_START,并且上报更新状态
currState = READY_START;
reportTaskStatus(READY_START);
} else {
Thread.sleep(100);
}
break;
case READY_START:
if (startCalled) {
currState = STARTING;
} else {
Thread.sleep(100);
}
break;
case STARTING:
currState = RUNNING;
break;
case RUNNING:
// 在RUNNING状态会调用collect方法
// 这个方法在SourceTask中会调用reader.pollNext方法,从而开始真正的数据读取,读取完成后会发送到SeaTunnelSourceCollector中,在SeaTunnelSourceCollector中接收到一条数据后,又会将数据发送给所有的下游任务
// 在TransformTask中,会调用transform的map方法,进行数据转换,转换完成后,将数据发送给SeaTunnelTransformCollector,同样在SeaTunnelTransformCollector中也会将数据发送给所有的下游
collect();
if (prepareCloseStatus) {
currState = PREPARE_CLOSE;
}
break;
case PREPARE_CLOSE:
if (closeCalled) {
currState = CLOSED;
} else {
Thread.sleep(100);
}
break;
case CLOSED:
this.close();
progress.done();
return;
// TODO support cancel by outside
case CANCELLING:
this.close();
currState = CANCELED;
progress.done();
return;
default:
throw new IllegalArgumentException("Unknown Enumerator State: " + currState);
}
}
Collector
在API的章节, 有描述Collector的功能, 是在单进程内多个线程间的数据管道. ![image.png]()
在任务拆分阶段, 会将sink单独拆离出来, 通过IntermediateExecutionFlow进行关联. 而source和transform则是放到了一起. 也就是说这里涉及到的数据传递涉及到的节点是sink和它的上游任务. 在IntermediateQueueFlowLifeCycle中, 有一个AbstractIntermediateQueue队列变量, 多个线程之间通过这个队列来实现生产者/消费者的消费模型来进行数据传递. AbstractIntermediateQueue有两个实现类:
IntermediateBlockingQueueIntermediateDisruptor 它们两个的区别是消息队列的实现有所不同, IntermediateBlockingQueue是默认的实现, 是通过ArrayBlockingQueue来实现的. 而IntermediateDisruptor则是通过Disruptor来实现的, 如果需要开启此功能, 需要在seatunnel.yaml中修改配置项engine.queue-type=DISRUPTOR来开启.
其实在代码中也有一些关于Shuffle的实现, 它实现的数据传递是基于hazelcast的IQueue队列来实现的, 可以实现跨进程的数据传递, 但是这一部分请教了社区的大佬之后, 说这一部分后续也废弃了.
TaskExecution
在上面分析了一个任务的执行过程,这个章节会记录一下,一个具体的任务/Task/Class,是如何被运行起来的。
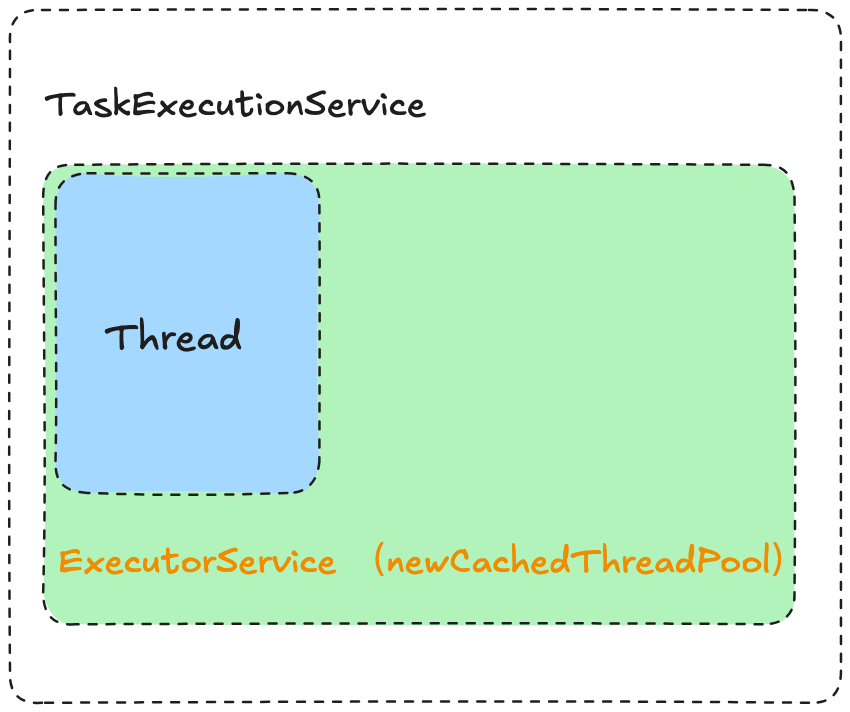
TaskExecutionService
在Zeta引擎启动后,在服务端会启动一个TaskExecutionService服务,这个服务内会有一个缓存线程池来执行任务。 ![]()
在PhysicalVertex的状态切换中,当状态为DEPLOYING时,
case DEPLOYING:
TaskDeployState deployState =
deploy(jobMaster.getOwnedSlotProfiles(taskGroupLocation));
if (!deployState.isSuccess()) {
makeTaskGroupFailing(
new TaskGroupDeployException(deployState.getThrowableMsg()));
} else {
updateTaskState(ExecutionState.RUNNING);
}
break;
会将作业进行部署,部署到之前所申请到的worker节点上。 这个类里有这样一个方法来生成TaskGroupImmutableInformation
public TaskGroupImmutableInformation getTaskGroupImmutableInformation() {
List<Data> tasksData =
this.taskGroup.getTasks().stream()
.map(task -> (Data) nodeEngine.getSerializationService().toData(task))
.collect(Collectors.toList());
return new TaskGroupImmutableInformation(
this.taskGroup.getTaskGroupLocation().getJobId(),
flakeIdGenerator.newId(),
this.taskGroup.getTaskGroupType(),
this.taskGroup.getTaskGroupLocation(),
this.taskGroup.getTaskGroupName(),
tasksData,
this.pluginJarsUrls,
this.connectorJarIdentifiers);
}
这里可以看出,会将当前节点上的所有任务进行序列化,然后设置相应的字段值。 生成这个信息后,会进行网络调用,将这个信息发送给具体的Worker上。 从这个地方也可以得知,一个TaskGroup内的所有任务都会被分发到同一个节点上运行.
而Worker接收到这个信息后,会调用TaskExecutionService的deployTask(@NonNull Data taskImmutableInformation)方法。这个方法内会进行网络传输数据的反序列化,之后再调用TaskDeployState deployTask(@NonNull TaskGroupImmutableInformation taskImmutableInfo)
我们来具体看下这个方法
public TaskDeployState deployTask(@NonNull TaskGroupImmutableInformation taskImmutableInfo) {
logger.info(
String.format(
"received deploying task executionId [%s]",
taskImmutableInfo.getExecutionId()));
TaskGroup taskGroup = null;
try {
List<Set<ConnectorJarIdentifier>> connectorJarIdentifiersList =
taskImmutableInfo.getConnectorJarIdentifiers();
List<Data> taskData = taskImmutableInfo.getTasksData();
ConcurrentHashMap<Long, ClassLoader> classLoaders = new ConcurrentHashMap<>();
List<Task> tasks = new ArrayList<>();
ConcurrentHashMap<Long, Collection<URL>> taskJars = new ConcurrentHashMap<>();
for (int i = 0; i < taskData.size(); i++) {
Set<URL> jars = new HashSet<>();
Set<ConnectorJarIdentifier> connectorJarIdentifiers =
connectorJarIdentifiersList.get(i);
if (!CollectionUtils.isEmpty(connectorJarIdentifiers)) {
jars = serverConnectorPackageClient.getConnectorJarFromLocal(
connectorJarIdentifiers);
} else if (!CollectionUtils.isEmpty(taskImmutableInfo.getJars().get(i))) {
jars = taskImmutableInfo.getJars().get(i);
}
ClassLoader classLoader =
classLoaderService.getClassLoader(
taskImmutableInfo.getJobId(), Lists.newArrayList(jars));
Task task;
if (jars.isEmpty()) {
task = nodeEngine.getSerializationService().toObject(taskData.get(i));
} else {
task =
CustomClassLoadedObject.deserializeWithCustomClassLoader(
nodeEngine.getSerializationService(),
classLoader,
taskData.get(i));
}
tasks.add(task);
classLoaders.put(task.getTaskID(), classLoader);
taskJars.put(task.getTaskID(), jars);
}
taskGroup =
TaskGroupUtils.createTaskGroup(
taskImmutableInfo.getTaskGroupType(),
taskImmutableInfo.getTaskGroupLocation(),
taskImmutableInfo.getTaskGroupName(),
tasks);
logger.info(
String.format(
"deploying task %s, executionId [%s]",
taskGroup.getTaskGroupLocation(), taskImmutableInfo.getExecutionId()));
// 上面获取一些信息后重新构建taskGroup
synchronized (this) {
// 首先会判断当前是否已经运行了该任务,如果已经运行过则不再提交任务
// 同时这里也对当前实例添加了全局锁,避免同时调用的问题
if (executionContexts.containsKey(taskGroup.getTaskGroupLocation())) {
throw new RuntimeException(
String.format(
"TaskGroupLocation: %s already exists",
taskGroup.getTaskGroupLocation()));
}
// 没有运行过当前任务则进行提交
deployLocalTask(taskGroup, classLoaders, taskJars);
return TaskDeployState.success();
}
} catch (Throwable t) {
...
return TaskDeployState.failed(t);
}
}
这个方法内会根据TaskGroupImmutableInformation信息来重新构建TaskGroup,然后调用deployLocalTask()进行部署任务。
public PassiveCompletableFuture<TaskExecutionState> deployLocalTask(
@NonNull TaskGroup taskGroup,
@NonNull ConcurrentHashMap<Long, ClassLoader> classLoaders,
ConcurrentHashMap<Long, Collection<URL>> jars) {
CompletableFuture<TaskExecutionState> resultFuture = new CompletableFuture<>();
try {
// 初始化操作
taskGroup.init();
logger.info(
String.format(
"deploying TaskGroup %s init success",
taskGroup.getTaskGroupLocation()));
// 获取到当前任务组中的所有任务
Collection<Task> tasks = taskGroup.getTasks();
CompletableFuture<Void> cancellationFuture = new CompletableFuture<>();
TaskGroupExecutionTracker executionTracker =
new TaskGroupExecutionTracker(cancellationFuture, taskGroup, resultFuture);
ConcurrentMap<Long, TaskExecutionContext> taskExecutionContextMap =
new ConcurrentHashMap<>();
final Map<Boolean, List<Task>> byCooperation =
tasks.stream()
.peek(
// 设置context信息
task -> {
TaskExecutionContext taskExecutionContext =
new TaskExecutionContext(task, nodeEngine, this);
task.setTaskExecutionContext(taskExecutionContext);
taskExecutionContextMap.put(
task.getTaskID(), taskExecutionContext);
})
.collect(
// 会根据是否需要线程共享来进行分组
// 目前默认是不共享的,也就是全部都会是false
partitioningBy(
t -> {
ThreadShareMode mode =
seaTunnelConfig
.getEngineConfig()
.getTaskExecutionThreadShareMode();
if (mode.equals(ThreadShareMode.ALL)) {
return true;
}
if (mode.equals(ThreadShareMode.OFF)) {
return false;
}
if (mode.equals(ThreadShareMode.PART)) {
return t.isThreadsShare();
}
return true;
}));
executionContexts.put(
taskGroup.getTaskGroupLocation(),
new TaskGroupContext(taskGroup, classLoaders, jars));
cancellationFutures.put(taskGroup.getTaskGroupLocation(), cancellationFuture);
// 这里全部是空,如果用户修改了,这里会找出来需要线程共享的任务
submitThreadShareTask(executionTracker, byCooperation.get(true));
// 提交任务
submitBlockingTask(executionTracker, byCooperation.get(false));
taskGroup.setTasksContext(taskExecutionContextMap);
// 打印成功的日志
logger.info(
String.format(
"deploying TaskGroup %s success", taskGroup.getTaskGroupLocation()));
} catch (Throwable t) {
logger.severe(ExceptionUtils.getMessage(t));
resultFuture.completeExceptionally(t);
}
resultFuture.whenCompleteAsync(
withTryCatch(
logger,
(r, s) -> {
if (s != null) {
logger.severe(
String.format(
"Task %s complete with error %s",
taskGroup.getTaskGroupLocation(),
ExceptionUtils.getMessage(s)));
}
if (r == null) {
r =
new TaskExecutionState(
taskGroup.getTaskGroupLocation(),
ExecutionState.FAILED,
s);
}
logger.info(
String.format(
"Task %s complete with state %s",
r.getTaskGroupLocation(), r.getExecutionState()));
// 报告部署的状态给master notifyTaskStatusToMaster(taskGroup.getTaskGroupLocation(), r);
}),
MDCTracer.tracing(executorService));
return new PassiveCompletableFuture<>(resultFuture);
}
private void submitBlockingTask(
TaskGroupExecutionTracker taskGroupExecutionTracker, List<Task> tasks) {
MDCExecutorService mdcExecutorService = MDCTracer.tracing(executorService);
CountDownLatch startedLatch = new CountDownLatch(tasks.size());
taskGroupExecutionTracker.blockingFutures =
tasks.stream()
.map(
t ->
new BlockingWorker(
new TaskTracker(t, taskGroupExecutionTracker),
startedLatch))
.map(
r ->
new NamedTaskWrapper(
r,
"BlockingWorker-"
+ taskGroupExecutionTracker.taskGroup
.getTaskGroupLocation()))
.map(mdcExecutorService::submit)
.collect(toList());
// Do not return from this method until all workers have started. Otherwise,
// on cancellation there is a race where the executor might not have started // the worker yet. This would result in taskletDone() never being called for // a worker. uncheckRun(startedLatch::await);
}
这里的MDCExecutorService是ExecutorService实现,BlockWorking是Runnable的实现。
private final class BlockingWorker implements Runnable {
private final TaskTracker tracker;
private final CountDownLatch startedLatch;
private BlockingWorker(TaskTracker tracker, CountDownLatch startedLatch) {
this.tracker = tracker;
this.startedLatch = startedLatch;
}
@Override
public void run() {
TaskExecutionService.TaskGroupExecutionTracker taskGroupExecutionTracker =
tracker.taskGroupExecutionTracker;
ClassLoader classLoader =
executionContexts
.get(taskGroupExecutionTracker.taskGroup.getTaskGroupLocation())
.getClassLoaders()
.get(tracker.task.getTaskID());
ClassLoader oldClassLoader = Thread.currentThread().getContextClassLoader();
Thread.currentThread().setContextClassLoader(classLoader);
// 获取到SeaTunnel的Task
final Task t = tracker.task;
ProgressState result = null;
try {
startedLatch.countDown();
// 调用Task的init方法
t.init();
do {
// 循环调用 call()方法
result = t.call();
} while (!result.isDone()
&& isRunning
&& !taskGroupExecutionTracker.executionCompletedExceptionally());
} catch (InterruptedException e) {
logger.warning(String.format("Interrupted task %d - %s", t.getTaskID(), t));
if (taskGroupExecutionTracker.executionException.get() == null
&& !taskGroupExecutionTracker.isCancel.get()) {
taskGroupExecutionTracker.exception(e);
}
} catch (Throwable e) {
logger.warning("Exception in " + t, e);
taskGroupExecutionTracker.exception(e);
} finally {
taskGroupExecutionTracker.taskDone(t);
if (result == null || !result.isDone()) {
try {
tracker.task.close();
} catch (IOException e) {
logger.severe("Close task error", e);
}
}
}
Thread.currentThread().setContextClassLoader(oldClassLoader);
}
}
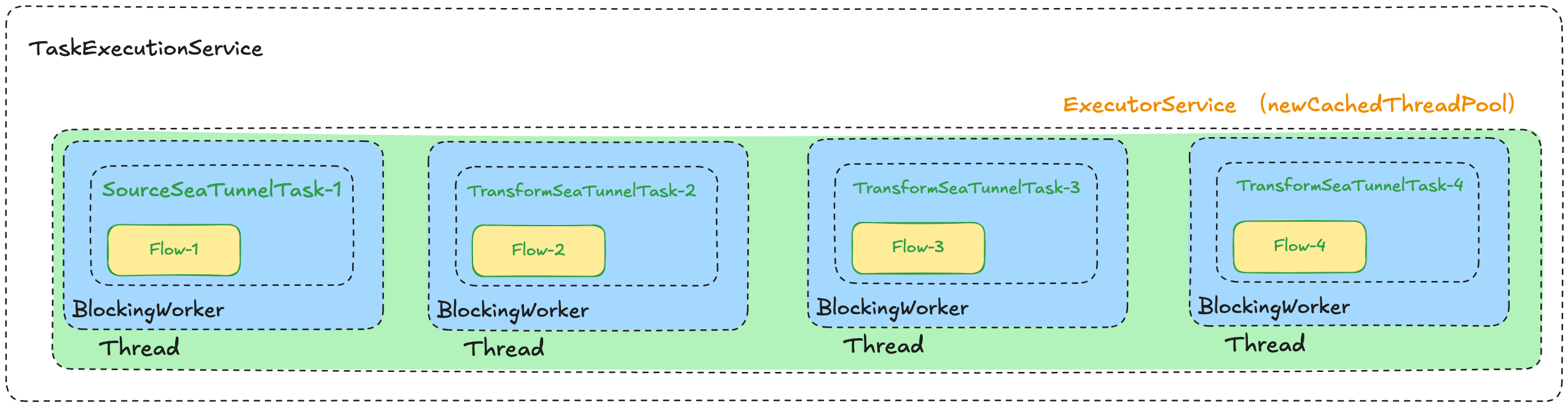
从这几部分代码可以看出,每一个Task都会作为一个单独的线程任务,被放到Worker的newCachedThreadPool线程池中来进行运行。
![image.png]()
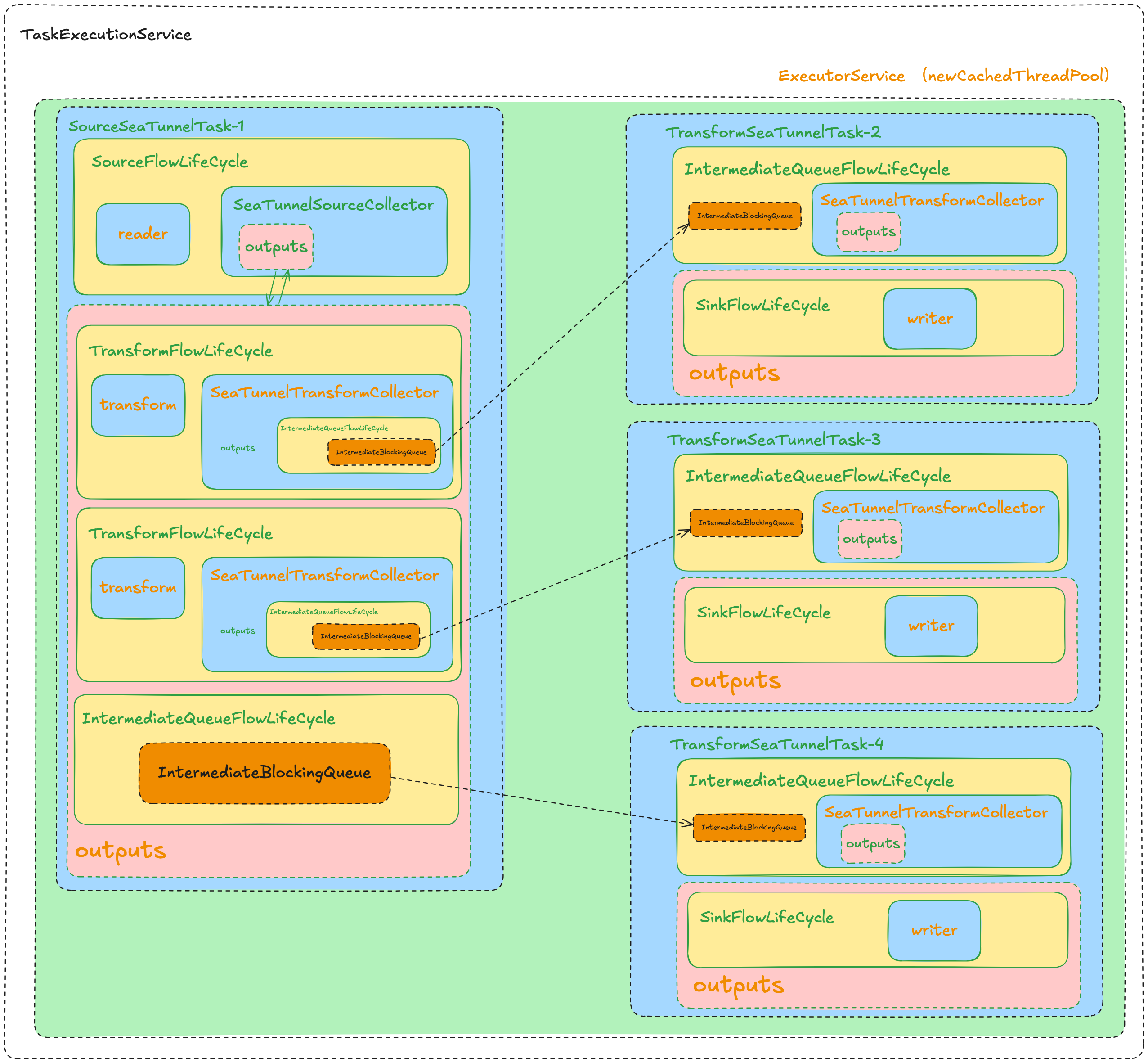
我们如果将上面的任务放大来看,将每个线程所做的任务以及任务之间的通信也画出来,大致是这样 ![image.png]()
如果将上面的图缩小看一下,仅关注数据的传输过程,大致是这样
![image.png]()
参考
本文由 白鲸开源科技 提供发布支持!
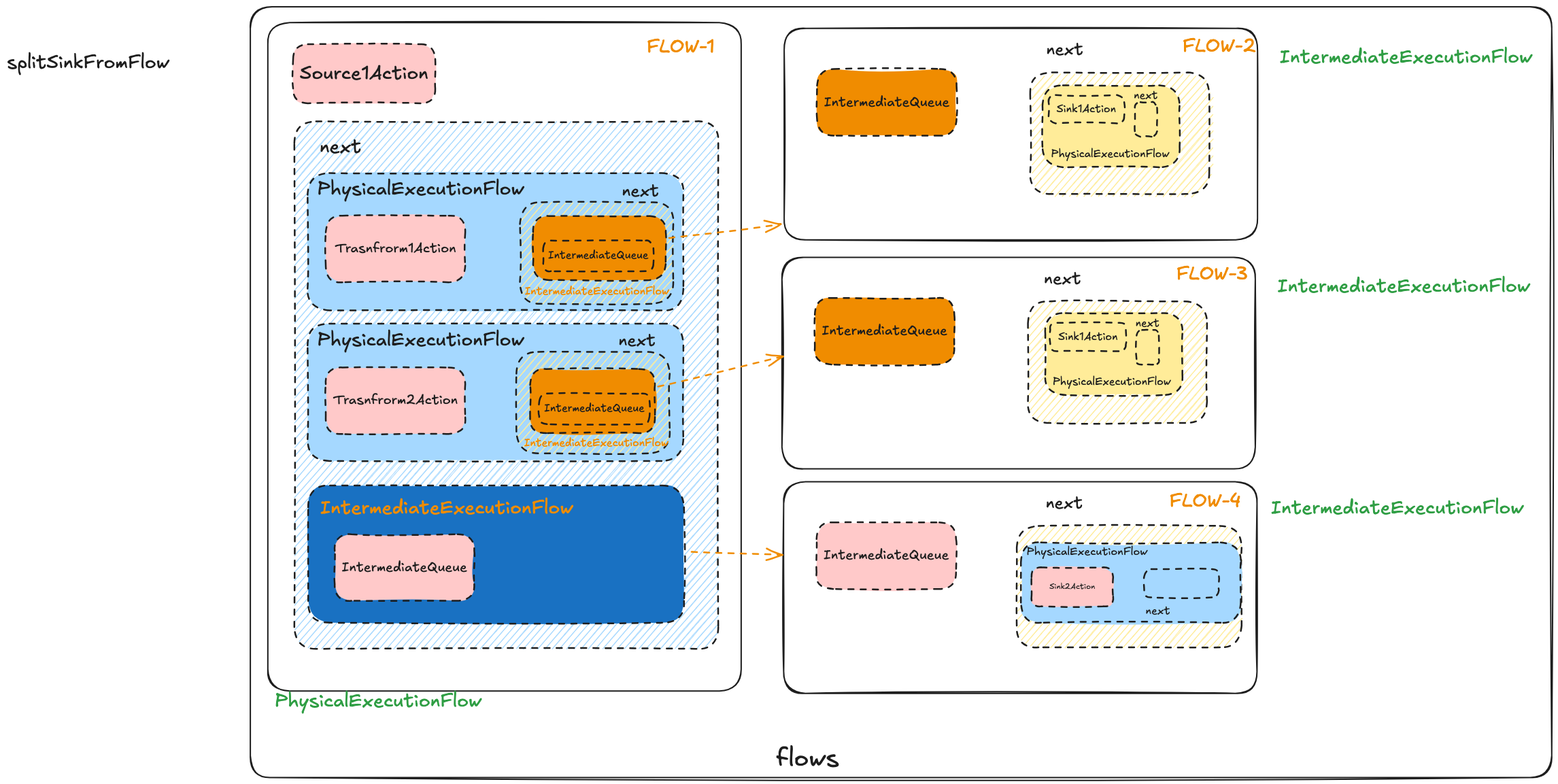 在生成任务时, 会在任务之间添加
在生成任务时, 会在任务之间添加