导读
本文从网页理解业务出发,从多模态信息融合,预训练任务构建角度,探讨通用网页建模方案。首先,指出网页的特殊性,即从不同观察视角下,网页存在富文本、树形结构,和图层堆叠三种形态。在此基础上,对比了多种多模态融合思路的优缺点,给出一种较好的方案。进一步,提出多粒度、多维度的网页预训练方案;最后,探索了大模型时代,利用现有多模态模型,低成本的适配到网页的一种可行思路。
01 综述
网页本质上是一种超文本,一般由超文本标记语言来定义(例如HTML)。HTML是一种基础技术,常与CSS、JavaScript一起被众多网站用于设计网页、网页应用程序以及移动应用程序的用户界面 。网页浏览器内核通过解释HTML文件,通过视觉引擎将其渲染成可视化网页。
由于HTML的复杂性特点,使得网页体现出多模态性,多粒度性,并且这些模态内部存在复杂的对应关系。
所谓多模态性,即从不同视角下,网页体现出不同的形态。从信息载体角度看,它是文本、图像、视频等多媒体元素集合。从视觉层面看,它拥有图层的概念,是各层图像堆叠起来形成了一张完整的“图片”。从底层代码逻辑看,它是一种特殊的类XML语言,定义了一棵具有层次关系的树(dom-tree)。
所谓多粒度性,即网页无论从哪种模态看,都是由粒度不等的元素组成的。
以资讯类网页举例,从信息载体模态看,网页由段落组成,段落又由句子组成,句子由tokens组成;
从视觉层面,网页由不同尺寸的图层,依次堆叠而成;
从底层代码逻辑看,html由不同高度以及大小的子树构成。
多种模态的基本元素之间,存在多对多的对齐关系。
对于dom-tree的结点,对应视觉层面的一个图层,亦可对应着一个或者多个句子
一个句子,可能对应着一个结点,也可能对应着多个结点
一个例子:多模态的网页表示
![图片]()
△语义:句子{图像、视频等可文本化)的集合
![图片]()
△结构:dom结点构成的树
![图片]()
△视觉:图层的叠加(轮廓图)
由于网页的多模态性,多粒度性,以及潜在对齐关系的特点,使得对网页的建模,与对富文本的建模思路有着显著的不同。如果将网页作为富文本处理,会丢失大量的信息
举一个简单的例子,一个文本位于网页的不同位置(譬如正文区域,推荐区域),它的重要性是完全不一样的。
而复杂的业务下游应用,例如网页质量甄别,网页结构化分块等,仅依赖文本的语义信息是远远不够的,需要综合考虑多模态的信息,以及多模态间的对齐信息。
下面,结合业界研究和我们的探索,从多模态信息融合、预训练方案方面展开。最后,探讨LLM时代,网页多模态模型的可能的探索方向。
02 多模态多粒度特征融合
如何将多粒度,多模态的特征融合,是一个复杂的问题。
1. 多粒度信息的表示
这个部分,业内解决方案较多。
对语义信息建模,基于hierarchical attention的有较多方案。一种方式,是通过bert等编码器,输入tokens,取CLS单元输出作为句子的向量表示;再通过transformer结构,输入句子向量,计算句子间attention,得到句子以及篇章的稠密向量表示,用于下游任务。
对于结构建模,以html-dom为基本单元。通过全连接层,融合bounding box坐标、webkit提取的css style信息等。
对于视觉建模,可以基于vit,以patch为基本单元。
2. 多对多对应关系下,多模态信息融合
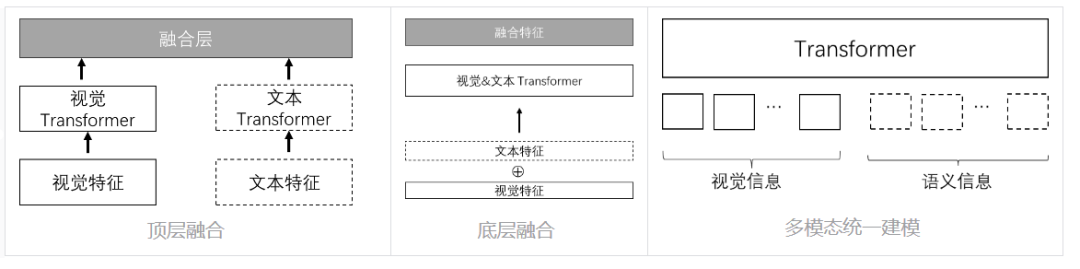
这部分,相关研究主要有四种方案:顶层融合,底层融合、多模态统一建模以及多模态交叉attention的方案。
![图片]()
底层融合即在输入层将多模态信息对齐后拼接作为transformer层的输入。这种方案对多任务预训练方案设计(包括任务类型,多任务loss权重设计)要求较高,不利于多种模态的信息的平衡。
顶层融合即在顶层获取一个结点或者语句对应的多模态向量,拼接后用于下游分类或回归任务。缺点在于,各模态独立建模的时候,缺少了相关信息交互,不能充分利用多模态之间的对齐信息。
多模态统一建模,以LayoutV2为例,将文本、图片信息通过不同的编码器定长编码后,输入统一的transformer中。对于多模态综合理解任务来说,很难在输入层显示的注入多模态的对齐信息;网页结构的单元向量与语义、视觉(网页轮廓图)的单元向量亦很难通过浅层的编码器投影到相同的语义空间内。
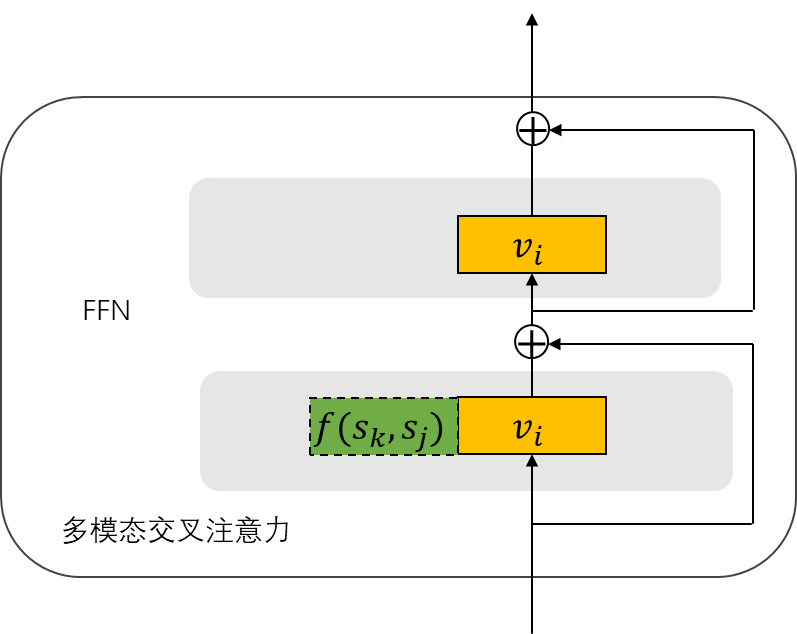
通过对比,认为在网页建模场景下,多模态交叉attention是一个较好的方案。具体来说,各模态分域表示,域之间相互独立;通过多模态交叉attention层完成多模态间信息交互。DocFormer提出的multi-modal attention,Beit3提出的MultiWay Transformer等本质上均为这种思路。
在多对多对齐关系下(即一个模态的基本单元,可能对应另外一个模态多个基本单元)。可使用聚合函数(例如average-pooling,lstm等),将对应模态上一层transformer-encode输出的对应单元序列,通过聚合操作后变换为定长向量,输入到多模态attention层计算。
![图片]()
![图片]()
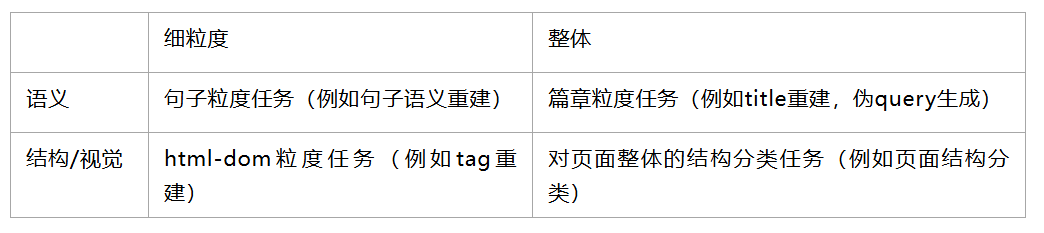
03 预训练任务设计
如何设计针对多个模态,不同粒度的任务,以及如何低成本的构建伪标签,是训练网页基座模型的关键。
分析业务中下游任务的特点,在预训练阶段设计了如下4个类别的的预训练任务。 ![]()
对于细粒度的语义预训练场景,借鉴token粒度MLM的思路,mask完整的句子,并且通过decoder重建句子。
对于粗粒度的篇章预训练场景,结合搜索点击日志,mask掉title后,通过decoder去噪重建title以及生成用户点击的query。
对于细粒度的html-dom粒度预训练场景,通过html_tag mask/重建,结点乱序重排进行训练。
对于篇章粒度的结构任务,通过GPT等生成页面类型的伪标签,作为监督信号训练。
04 展望:LLM时代的网页基座模型探索方向
现阶段,多模态大模型发展到新的阶段,已经可以将图片(视频)、文本通过统一的decoder模型处理 。如何有效利用已有大模型的能力,低成本适配到网页,是当前研究的热点和难点。
一个朴素的思想,是将整个html源码输入给大模型,做进一步postpretrain使得模型适配网页。但是,由于网页源码的平均长度非常大(根据我们对百度网页库的统计,平均源码长度在160k),如果再将节点的样式以style标签形式注入,源码长度预计会翻数十倍。面向海量网页计算极难落地。再者,针对网页场景下做若干轮post-pretrain成本亦很高。
一个可行思路是,通过adaptor网络,将网页html-dom的结构、位置以及视觉信息变换到已有多模态大模型的空间中,压缩成若干定长向量表示。
通过adaptor网络与LLM联合训练,调低LLM的学习率(尽量不扰动已有LLM的参数,保留LLM的泛化性);通过特殊标签,注入adaptor产出的tokens向量,让LLM解释隐式向量代表的含义,训练adaptor网络。
例如,构建prompt:
以下是一个网页的dom结点表示<STRUCT>adaptor_tokens</STRUCT>,输出css描述文本:style="xxxxx"
训练adator网络,使得产出的tokens向量能够与LLM的语义空间打平
———— END————
推荐阅读
百度垂搜一站式研发平台演进实践
初探图谱Embedding用于异常检测(一)
AIAPI - 转向AI原生检索
学校新来了一位AI作文老师:能看、会评、还教改写
搞定十万卡集群!贫穷限制了我的想象力…