导读
本文介绍了优化大数据计算中多维度用户数统计的方法,通过数据打标的方式避免数据膨胀,提高性能并减少计算成本。首先分析了大数据计算中遇到的多维度数据统计问题,然后提出了利用数据打标进行处理的解决方案,详细阐述了优化方案的实施步骤和效果。通过对比实验结果,验证了优化方案在提升性能和降低成本方面的显著效果。最后,总结了优化方案的优势和适用场景。
01 背景
Feed是百度App的一个重要业务组成部分,日均DAU(活跃用户数)规模在亿级别。在做数据分析和统计的时候,常常需要从不同日志维度去看对应的用户数。由于用户数不同维度不可累加的特性,基本上所有维度的用户数都需要单独计算,维度少的时候可以直接 count(distinct xx) 计算,维度多的话这种计算就相当痛苦了。
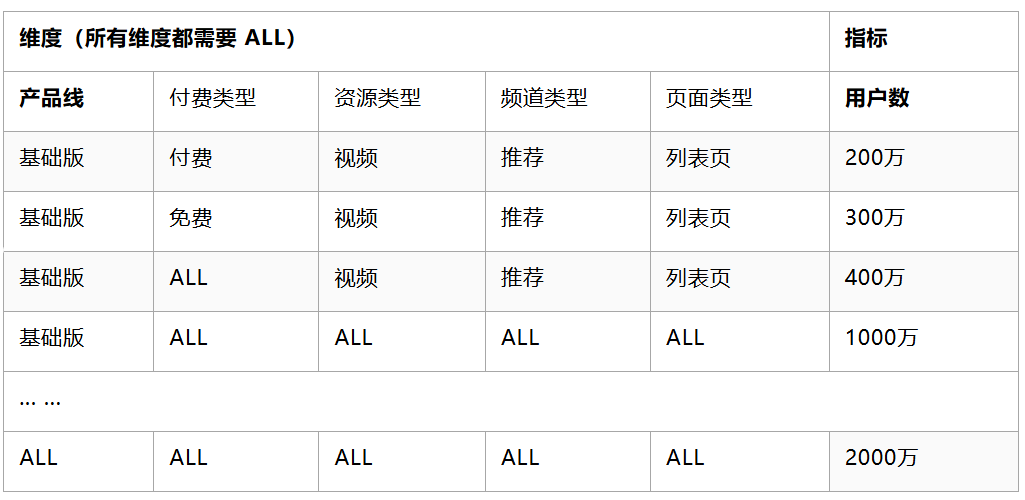
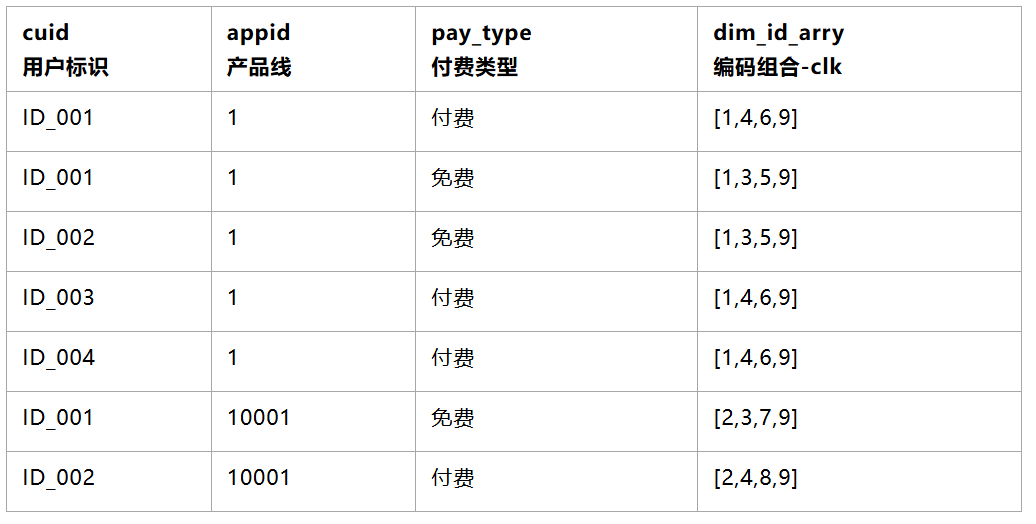
一个典型的场景如下:业务方需要从产品线、付费类型、资源类型、频道类型、页面类型等维度来看Feed的消费用户数。除了计算各个维度组合的用户数外,每个维度还需要看到整体的用户数。所需的结果数据表格如下(其中维度与指标均为虚构): ![]()
02 通用实现方式
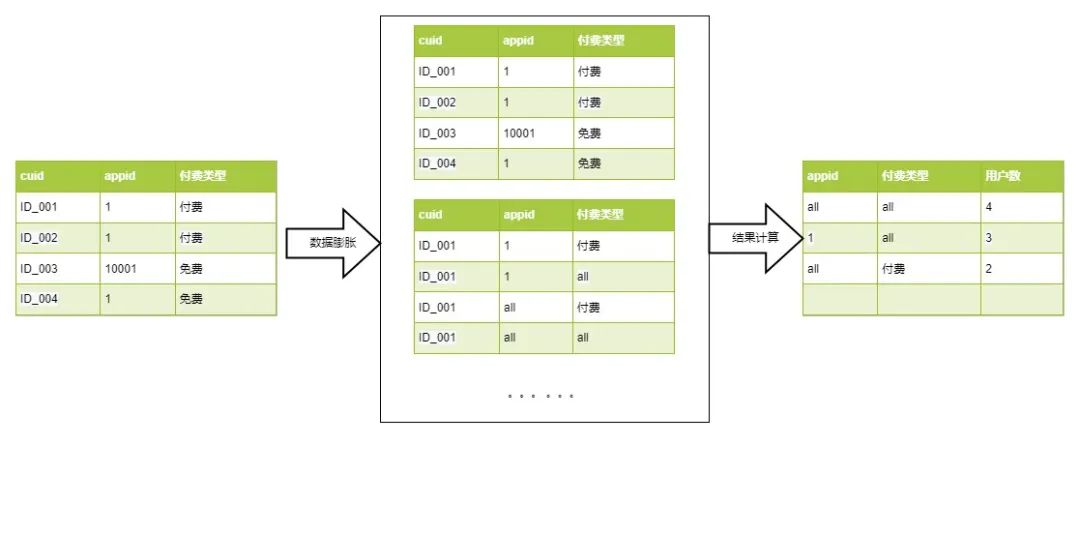
常见的实现方式是直接计算,单独计算每个维度的用户数指标。
将原始数据按 cuid+初始维度 去重后,使用 lateral view explode 将数据从一行膨胀成多行,然后直接 distinct 的数据计算方式。
2.1 核心思路
![图片]()
2.2 代码实现
-- 表名:feed_dws_kpi_dau_1d
-- 字段名及注释:appid##产品线,pay_type##付费类型,r_type##资源类型,tab_type##频道类型,page_type##页面类型,cuid##用户标识
select
appid_all, -- 产品线
pay_type_all, -- 付费类型
r_type_all, -- 资源类型
tab_type_all, -- 频道类型
page_type_all, -- 页面类型
count(distinct cuid) as feed_dau
from(
select
cuid,
appid,
pay_type,
r_type,
tab_type,
page_type
from feed_dws_kpi_dau_1d
group by 1,2,3,4,5,6
) tab
lateral view explode(array(appid, 'all')) B as appid_all
lateral view explode(array(pay_type, 'all')) B as pay_type_all
lateral view explode(array(r_type, 'all')) B as r_type_all
lateral view explode(array(tab_type, 'all')) B as tab_type_all
lateral view explode(array(page_type, 'all')) B as page_type_all
group by 1,2,3,4,5
03 优化方式
新的优化思路可以理解为在数据处理过程中采用一种“数据打标”策略,通过在数据去重的基础上生成用户粒度的中间数据,并在此基础上动态附加所需的结果维度信息。这样做的好处是可以将数据处理的重点集中在用户粒度的中间数据上,避免数据膨胀和冗余传输,同时通过编号化结果维度信息,采用更小的数据结构进行存储,从而降低数据处理的计算成本。
这种优化方法实际上是在数据处理过程中引入了一种“增量式”计算思想,即随着计算的进行,数据量逐渐收敛而不会无限增加。通过在中间数据上动态附加结果维度信息,可以避免在计算过程中重复传输和处理大量冗余数据,提高数据处理的效率和性能。
总的来说,这种优化思路旨在通过精细化数据处理流程,减少不必要的数据传输和计算成本,从而提升整体数据处理的效率和性能。
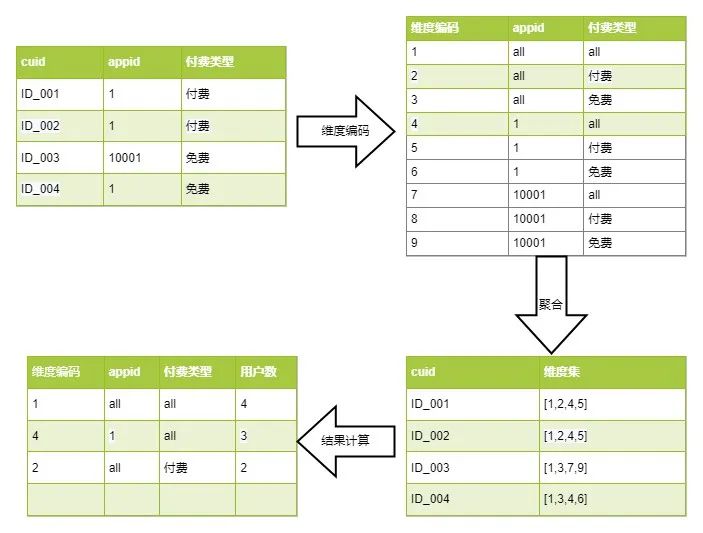
3.1 核心思路
![图片]()
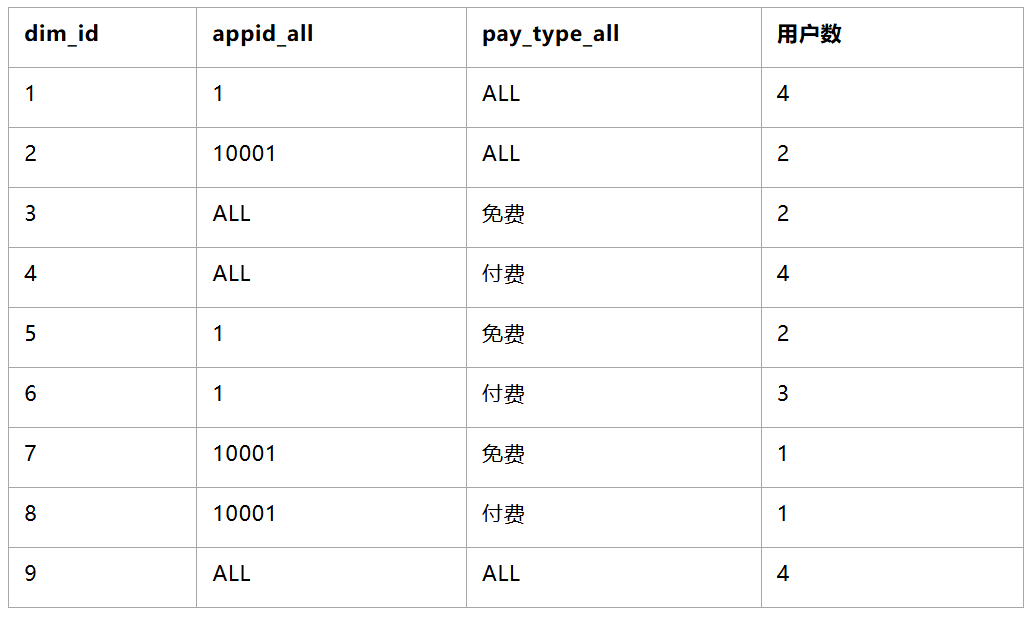
核心计算思路如上图,普通的数据膨胀计算用户数的方法,中间需要对数据进行膨胀,再聚合,其中数据膨胀的倍数是维度数的平方(只扩展“整体”的情况),如上两个维度预计数据膨胀 2^2=4 倍,三个维度的话就是膨胀 8倍。
而新的数据聚合方法,通过一定的策略方法将维度组合拆解为维度小表并进行编号,然后将原始数据聚合至用户粒度的中间过程数据,其中各类组合维度转换为数字标记录至用户维度的数据记录上,理论上整个计算过程数据量是呈收敛聚合的,不会膨胀。
3.2 逻辑分析
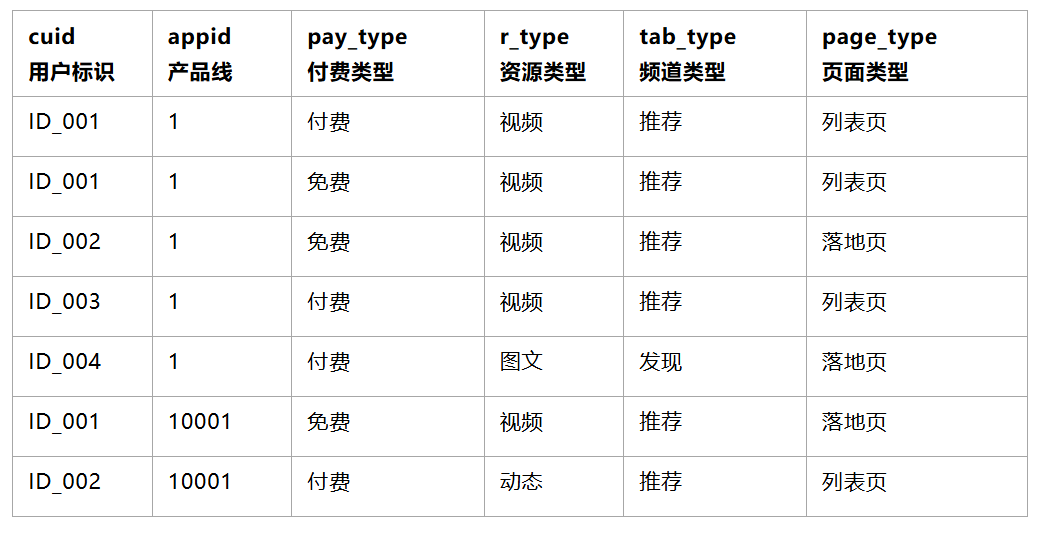
3.2.1 原创数据样例
![]()
3.2.2 基于明细数据产出维度结果数据,并进行编码(可使用窗口函数 DENSE_RANK() )
PS:基于可读性,只列举两个字段(appid,pay_type) ![]()
3.2.3 将1产出的编码表,通过原始数据维度关联,写回到用户明细上(可使用 MAPJOIN) ![]()
3.2.4 编码汇总到用户粒度上(可使用array_distinct) ![]()
3.2.5 统计每个编码id出现的次数,并关联产出编码原始维度 ![]()
3.3 代码实现
-- 基于明细数据产出维度结果数据,并进行编码
with dim_res as (
select
distinct
appid_all, -- 产品线
pay_type_all, -- 付费类型
r_type_all, -- 资源类型
tab_type_all, -- 频道类型
page_type_all, -- 页面类型
dim_key,
DENSE_RANK() OVER(ORDER BY appid_all,pay_type_all,r_type_all,tab_type_all,page_type_all) AS dim_id
from(
select
appid,
pay_type,
r_type,
tab_type,
page_type,
concat_ws(
'#',
coalesce(appid,'unknow'),
coalesce(pay_type,'unknow'),
coalesce(r_type,'unknow'),
coalesce(tab_type,'unknow'),
coalesce(page_type,'unknow')
) as dim_key
from feed_dws_kpi_dau_1d
group by 1,2,3,4,5,6
) t0
lateral view explode(array(appid, 'all')) B as appid_all
lateral view explode(array(pay_type, 'all')) B as pay_type_all
lateral view explode(array(r_type, 'all')) B as r_type_all
lateral view explode(array(tab_type, 'all')) B as tab_type_all
lateral view explode(array(page_type, 'all')) B as page_type_all
),
-- 生成cuid聚合数据+对应的维度编码组合
cuid_dim as(
select /*+ MAPJOIN(t1) */
cuid,
array_distinct(split(concat_ws(',',collect_set(concat_ws(',',dim_id_arry))),',')) as click_dim_id_arry
from(
select
cuid,
concat_ws(
'#',
coalesce(appid,'unknow'),
coalesce(pay_type,'unknow'),
coalesce(r_type,'unknow'),
coalesce(tab_type,'unknow'),
coalesce(page_type,'unknow')
) as dim_key
from feed_dws_kpi_dau_1d
group by 1,2
) t0
join (
-- 生成每个维度原始值对应的编码数组,减少shuffle过程的数据量
select
dim_key,
collect_set(dim_id) as dim_id_arry
from dim_res
group by dim_key
) t1 on t0.dim_key = t1.dim_key
group by cuid
)
-- 将维度编码回写为原始日志
select /*+ MAPJOIN(t1) */
appid_all, -- 产品线
pay_type_all, -- 付费类型
r_type_all, -- 资源类型
tab_type_all, -- 频道类型
page_type_all, -- 页面类型
feed_dau
from(
select
-- 基于维度编码进行计数
dim_id,
sum(feed_dau) as feed_dau
from(
-- 将维度数组转为字符串直接求和
select
concat_ws(',',click_dim_id_arry) as dim_id_str,
count(1) as feed_dau
from cuid_dim
group by 1
) tab
lateral view explode(split(dim_id_str,',')) B as dim_id
group by dim_id
) t0
join (
select
distinct
appid_all, -- 产品线
pay_type_all, -- 付费类型
r_type_all, -- 资源类型
tab_type_all, -- 频道类型
page_type_all, -- 页面类型
dim_id
from dim_res
) t1 on t0.dim_id = t1.dim_id
order by 1,2,3,4,5,6
3.4 实现案例分析
本部分展示的是我们业务过程中的实际案例,原始日志 4.5 亿条,业务多维分析所需维度 9 个,每个维度都需要保留“整体”项。以下列出了不同方式的实际执行情况,任务运行基于相同的运行队列与资源配置,经验证数据产出的结果一致。
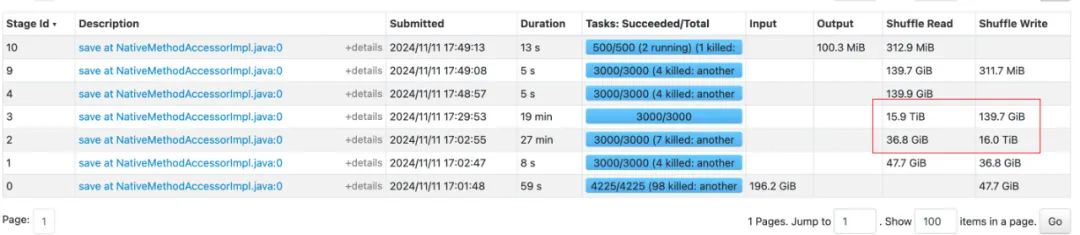
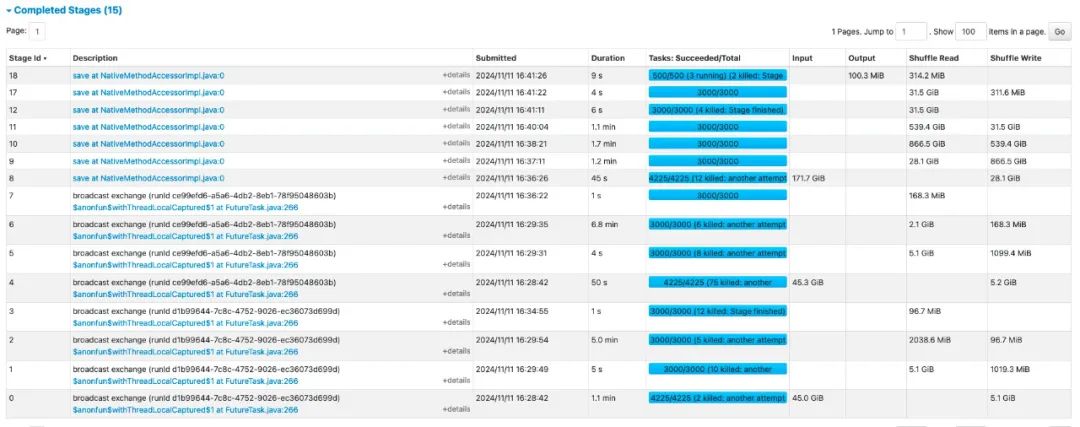
3.4.1 lateral view + distinct 方式
结论:整体运行时间 49分钟,最耗时的stage为数据扩展阶段,stage shuffle量达16TB,不具备优化空间。
![图片]()
△Stage执行情况
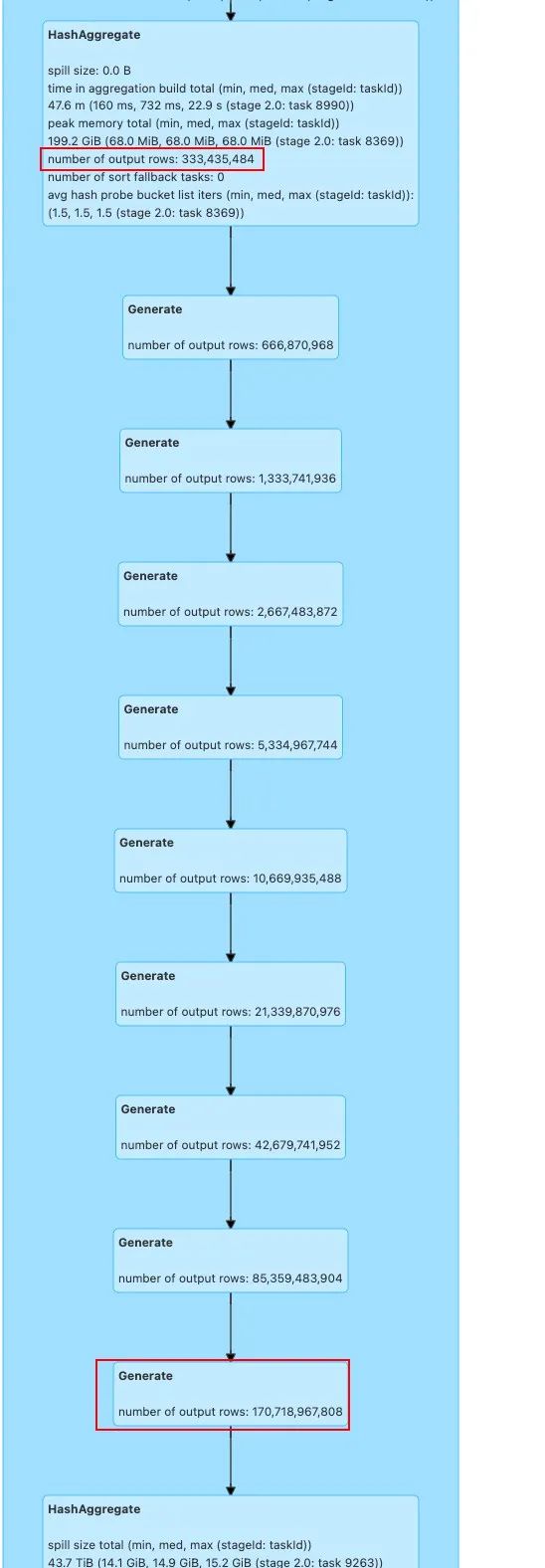
![图片]()
△lateral view将数据从 3.3亿条扩展到 1707亿条
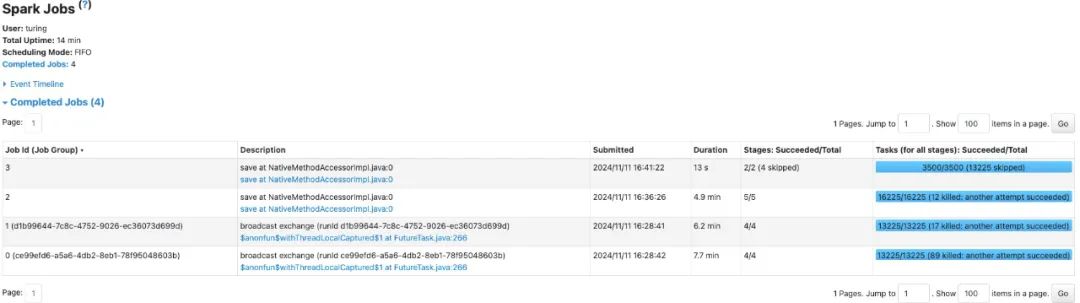
3.4.2 维度编码方式
结论:整体运行时间 14 分钟,耗时主要集中在对所需维度进行编码排序的过程(Job 1/2),这部分如果例行的话,可以提前进行缓存,可优化。最大shuffle量 800GB,是针对cuid对应的维度编码进行聚合,去重的过程。
![图片]()
△Job执行情况,Job 1/2为维度编码排序阶段
![图片]()
△Stage执行情况
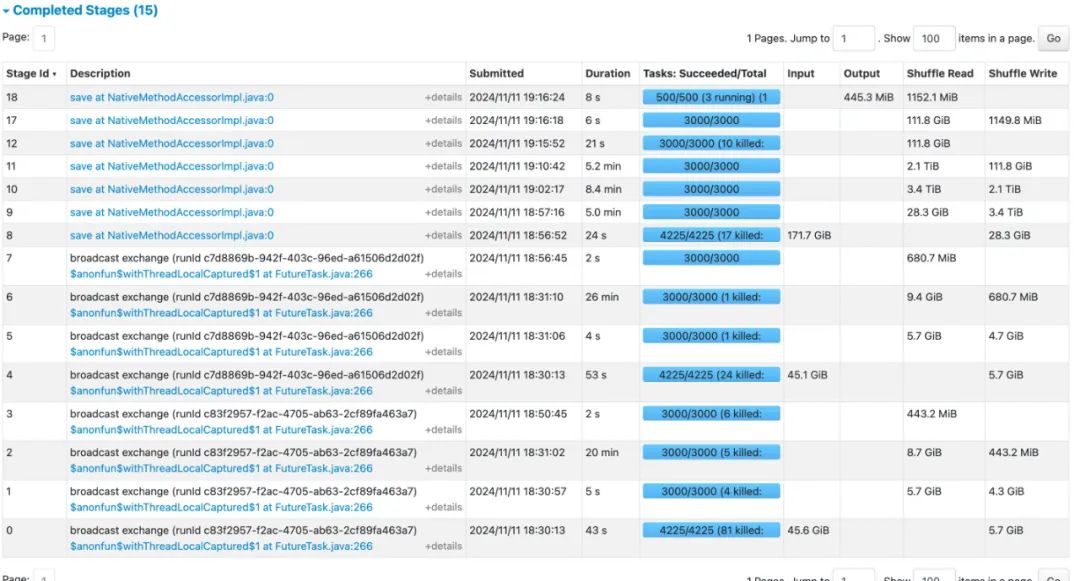
3.4.3 当所需维度增加
后续,业务所需维度增加至12个,lateral view + distinct 预计shuffle量会达到 120TB 左右,执行失败不出来。
采用维度编码的方案可以顺利执行,耗时主要集中在对所需维度进行编码排序的过程(Job 1/2)。
![图片]()
△Stage执行情况
04 方案总结&后续跟进
常见的基于数据膨胀的用户数计算方法,数据计算大小和过程数据传输量将随着维度的数量呈指数爆炸增长,维度数越多,花费在数据膨胀与Shuffle传输的资源和耗时占比越高。
为了解决数据膨胀过程中产生的大量过程数据,基于数据标签的思路反向操作,先对数据聚合为cuid+日志维度粒度,过程中将需要的维度组合转化编码数字并赋予cuid数据上,整个计算过程数据呈收敛聚合状,数据计算过程较为稳定,数据条数、shuffle量不会随着维度组合的进一步增加而大幅增加。
综上,当前的方案整体性能相较于以往有大幅度的提升,运行成本不会随着维度组合的增加而指数增加。但当前的方案也有不足之处,即代码的可理解性和可维护性。另外,当维度较少的时候,两者的性能差异不大;但当维度增加时,可以改用这种数据打标的思路进行压缩,此时的性能优势开始凸显,并且维度数越多,此方案的性能优势越大。
目前,这种计算方案已经落地应用到Feed核心场景以及短剧业务多维用户数计算。支持Feed业务 10+维度、亿级用户数的计算。
后续,我们计划针对维度编码的方案进一步优化。将代码里一些复杂的功能逻辑封装成udf,包括数组字段聚合、数据字段聚合去重等功能函数;同时针对例行任务,提前将维度组合进行排序编码。进一步加强代码的可读性与运行成本。
———— END ————
推荐阅读
数据湖系列之四 | 数据湖存储加速方案的发展和对比分析
大模型时代,云原生数据底座的创新和实践
百度沧海·存储统一技术底座架构演进
计算不停歇,百度沧海数据湖存储加速方案 2.0 设计和实践
AI 原生时代,更要上云:百度智能云云原生创新实践