摘要:GaussDB (for MySQL) 采用“日志即数据”的设计,相较于传统 MySQL,不再需要刷 page,所有的更新操作仅记录日志,不再需要 double write,从而实现毫秒级的主从延迟。
本文分享自华为云社区《【选择GaussDB (for MySQL) 的十大理由】之一:主备 0 延迟》,作者: GaussDB 数据库。
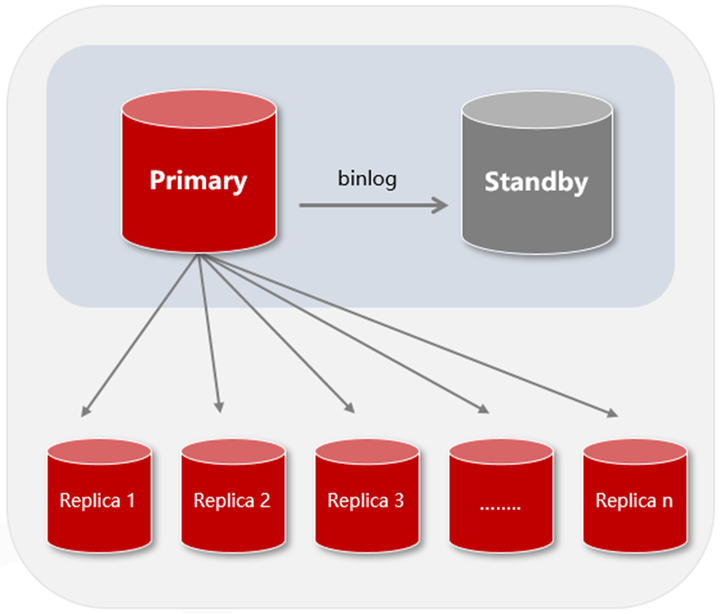
复制延迟是传统 MySQL 架构难以消除的缺陷
在企业级的生产环境中,MySQL 通常使用集群架构,常见的有一主一从和一主多从,且在很多情况下都会面临主从复制延迟的问题。MySQL 的复制延迟是指主从服务器之间的数据同步有时间差,导致主从数据不一致,甚至在故障倒换时发生丢失数据等重大故障。
![]()
在日常使用 MySQL 过程中就可能存在一定的复制延迟。这是因为在传统主备架构中,主库在变更自身数据文件的同时将变更操作记录到 binlog 文件中,备库复制 binlog 文件并回放其中记录的写操作,从而使得自身的数据文件与主库做同样的变更。这个过程是异步的或者半同步的。其中一些场景会加剧复制延迟,如网络卡顿、备库 IO 性能瓶颈、处理大事务、服务器负载高、锁竞争等。
GaussDB (for MySQL) 如何避免复制延迟
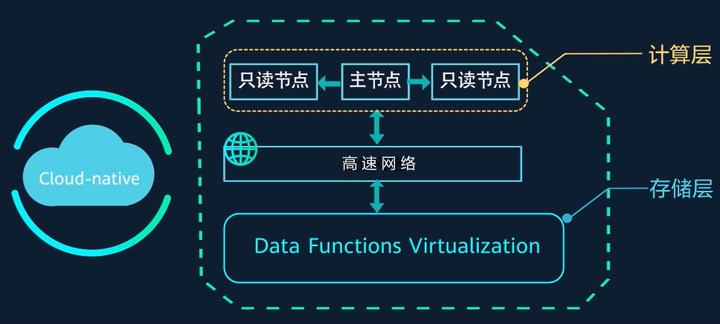
GaussDB (for MySQL) 是华为自研的新一代企业级高扩展海量存储云原生数据库,完全兼容 MySQL。同时,基于华为新一代 DFV 存储,采用计算存储分离架构。
![]()
从架构上看,GaussDB (for MySQL) 不仅计算和存储实现了解耦,主库和从库同样也实现了解耦。这是因为其主从节点共享了一份数据,所以抛弃传统的主备复制流程,主从之间不再依赖 binlog 的复制和回放来做数据同步。
另外,GaussDB (for MySQL) 采用“日志即数据”的设计,相较于传统 MySQL,不再需要刷 page,所有的更新操作仅记录日志,不再需要 double write,从而实现毫秒级的主从延迟。
用户在使用 MySQL 时,从库上常常承担部分读流量,GaussDB (for MySQL) 可以保证主和只读之间无延时,保证数据的强一致性,在时延敏感类业务中发挥巨大作用。
除此之外,在遇到进程 hang 死或服务器宕机等故障场景时,MySQL 的高可用机制会触发主备倒换。如果此时复制时延较大,故障恢复的 RTO 就会较大,若强行进行主备倒换可能导致数据丢失。GaussDB (for MySQL) 能够从容面对无法预料的故障场景,故障发生第一时间进行主备倒换,保证数据 0 丢失。
GaussDB (for MySQL) 轻松化解业务难题
金智教育是国内领先的高校信息化服务运营商,旗下推出的辅导猫致力于学生日常管理的协同办公,与全国 200+ 高校的学工处、辅导员、班主任一起创造属于自己的信息化应用。
辅导猫业务覆盖全国 1000+ 高校,日活达到百万人次,数据表多达 5 万张,业务涉及多表的同时更新和查询。其中业务的核心痛点就是主从复制时延问题:部分业务写在主库,读在只读库,因主从时延较大,导致学生反复提交信息,统计看板展示的信息也无法及时更新。
![]()
针对该业务痛点,客户采用华为云提供的“GaussDB (for MySQL) + Proxy”解决方案。GaussDB (for MySQL) 的存算分离架构实现存储共享,主节点和只读节点间无时延,上层业务全栈无感。
GaussDB (for MySQL) 主备 0 延迟的特点在金融业务、电商大促、游戏周年庆等多种业务场景中同样发挥奇效。例如,用户在只读库上查询一单已支付的订单状态,如果此时只读库还没有及时同步主库的数据,那么用户可能会看到订单状态是未支付,给用户带来困扰体验的同时降低了产品信誉度。
总结
GaussDB (for MySQL) 存算分离架构,天然地解决了传统 MySQL 主备架构的复制延迟困境,从根上避免了主从数据不一致带来的一系列问题。如业务有需要,可购买 “包年/包月” 或 “按需” 实例,自动创建无需部署,快来试用吧!链接
点击关注,第一时间了解华为云新鲜技术~