作者 | 杨亦诚 英特尔 AI 软件工程师
卢建晖 微软高级云技术布道师
排版 | 吴紫琴
近期微软发布其最新的 Phi-3.5 系列 SLM 模型, Phi-3.5-mini, Phi-3.5-vision, 以及 Phi-3.5-MoE,其中 Phi-3.5-mini 增加了多语种以及128k上下文长度的支持,提升中文输入的使用体验;Phi-3.5-vision 全面支持多图片理解任务,拓宽了其在视频理解任务类中的应用场景。
英特尔 AI PC 可以帮助用户利用人工智能技术提高工作效率、创意、游戏、娱乐和安全等性能。它搭载 CPU、GPU 和 NPU,可在本地更高效地处理 AI 任务。其中我们可以依靠 CPU 来运行较小的工作负载并实现低延迟,而 GPU 则非常适合需要并行吞吐量的大型工作负载,例如大语言模型推理任务,NPU 能够以低功耗处理持续运行 AI 工作负载,提高效率。开发者可以利用英特尔 OpenVINO™ 工具套件充分激活这些AI处理单元,更高效地部署深度学习模型,其中 Phi-3. 5 就是一个非常适合运行在 AI PC 上的模型任务。本文将分享如何利用 OpenVINO™ 在你的 AI PC 上部署最新 Phi-3.5-mini 及 Phi-3.5-vision 模型。
项目示例地址:
https://github.com/openvino-dev-samples/Phi-3-workshop
phi-3cookbook :
https://aka.ms/phi-3cookbook
由于 Phi-3.5 的预训练模型是基于 PyTorch 框架的,因此我们可以利用 Optimum-intel 的命令型工具快速从 Hugging Face 上导出 Phi-3.5-mini 的预训练模型,并通过内置的 NNCF 工具对模型进行权重量化压缩,以此提升推理性能,降低资源占用。
optimum-cliexport openvino--model microsoft/Phi-3.5-mini-instruct --task text-generation-with-past--weight-format int4--group-size 128--ratio 0.6--sym--trust-remote-code phi-3.5-mini-instruct-ov
开发者可以根据模型的输出结果,调整其中的量化参数,包括:
-
weight-format:量化精度,可以选择 fp32,fp16,int8,int4,int4_sym_g128,int4_asym_g128,int4_sym_g64,int4_asym_g64。
-
group-size:权重里共享量化参数的通道数量。
-
ratio:int4/int8 权重比例,默认为1.0,0.6表示60%的权重以 int4 表,40%以 int8 表示。
-
sym:是否开启对称量化。
更多参数选项可以通过:optimum-cli export openvino -h 命令查询。
为了方便 Transformers 库用户体验 OpenVINO™,开发者可以利用 Optimum-intel 所提供的类 Transformers API 进行模型任务的部署。在不改变原本代码逻辑的前提下,只需要将 AutoModelForCausalLM 对象切换为 OVModelForCausalLM,便可以轻松实现对于推理后端的迁移,利用 OpenVINO™ 来加速 Phi-3.5-mini 原有的 Pipeline。
from optimum.intel.openvino import OVModelForCausalLMfrom transformers import AutoConfig, AutoTokenizer
ov_model = OVModelForCausalLM.from_pretrained( llm_model_path, device='GPU', config=AutoConfig.from_pretrained(llm_model_path, trust_remote_code=True), trust_remote_code=True,)tok = AutoTokenizer.from_pretrained(llm_model_path, trust_remote_code=True)prompt = "<|user|>\n你了解 .NET 吗?\n<|end|><|assistant|>\n"input_tokens = tok(prompt, return_tensors="pt", **tokenizer_kwargs)answer = ov_model.generate(**input_tokens, max_new_tokens=1024)tok.batch_decode(answer, skip_special_tokens=True)[0]
除此以外,你也可以通过 device 来指定模型部署的硬件平台为英特尔 CPU 或是 GPU。
当然考虑到 Transformers 中大量的第三方依赖,如果开发者想实现轻量化部署的目的,也可以利用 OpenVINO™ 原生的 GenAI API 来构建推理任务,由于 GenAI API 底层的 pipeline 是基于 C++ 构建,同时优化了 chat 模式下 kvcache 的缓存逻辑,因此相较 Optimum-intel,GenAI API 的资源占用和性能都是更优的。
import openvino_genai as ov_genai
pipe = ov_genai.LLMPipeline(llm_model_path, "GPU")
可以看到在使用 GenAI API 的情况下,我们仅用3行代码就构建起了一个完整的文本生成任务 Pipeline。
1. 模型转换与量化
目前 Phi-3.5-vision 的推理任务还没有被完全集成进 Optimum 工具中,因此我们需要手动完成模型的转换和量化,其中包含语言模型 lang_model,图像编码模型 image_embed,token 编码模型 embed_token 模型以及图像特征映射模型 img_projection。
为了简化转化步骤,我们提前对这些转化任务行进行了封装,开发者只需要调用示例中提供的函数便可完成这些模型的转换,并对其中负载最大的语言模型进行量化。
from ov_phi3_vision import convert_phi3_modelmodel_id = "microsoft/Phi-3.5-vision-instruct"out_dir = Path("../model/phi-3.5-vision-instruct-ov")compression_configuration = { "mode": nncf.CompressWeightsMode.INT4_SYM, "group_size": 64, "ratio": 0.6,}if not out_dir.exists(): convert_phi3_model(model_id, out_dir, compression_configuration)
2. 图片内容理解
此外在该示例中,我们也对模型的推理任务进行封装,通过以下代码便可快速部署图像理解任务。
from transformers import AutoProcessor, TextStreamer
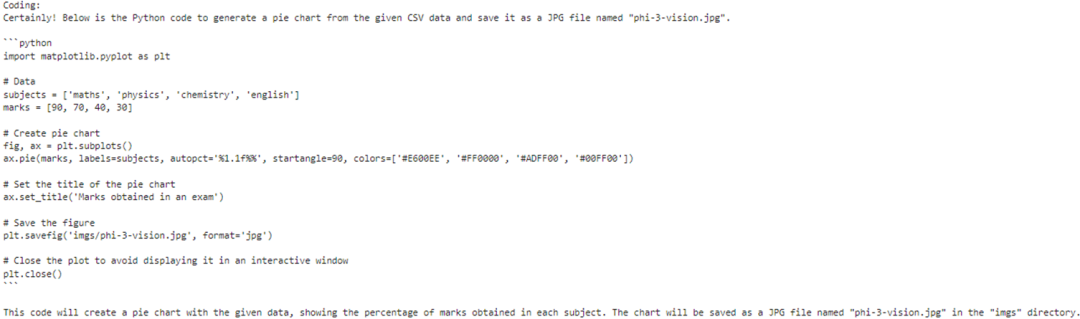
messages = [ {"role": "user", "content": "<|image_1|>\nPlease create Python code for image, and use plt to save the new picture under imgs/ and name it phi-3-vision.jpg."},]
processor = AutoProcessor.from_pretrained(out_dir, trust_remote_code=True)
prompt = processor.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = processor(prompt, [image], return_tensors="pt")
generation_args = {"max_new_tokens": 3072, "do_sample": False, "streamer": TextStreamer(processor.tokenizer, skip_prompt=True, skip_special_tokens=True)}
print("Coding:")generate_ids = model.generate(**inputs, eos_token_id=processor.tokenizer.eos_token_id, **generation_args)
可以看到在理解拼图内容后,Phi-3-vision 为我们生成了一段 Python 脚本来复现拼图数据。
3. 视频内容理解
由于 Phi-3.5-vision 可以同时支持对多个图像输入,因此可以基于这一特性实现视频内容理解,实现方法也特别简单,仅需对视频文件抽帧后保存为图片,并将这些图片基于 Phi-3.5-vision 提供的预处理脚本合并后,转化为 Prompt 模板,送入模型流水线进行推理。
images = [] placeholder = "" for i in range(1,4): with open("../examples/output/keyframe_"+str(i)+".jpg", "rb") as f: images.append(Image.open("../examples/output/keyframe_"+str(i)+".jpg")) placeholder += f"<|image_{i}|>\n"
from transformers import AutoProcessor, TextStreamer
messages = [ {"role": "user", "content": placeholder+"Summarize the video."},]
processor = AutoProcessor.from_pretrained(out_dir, trust_remote_code=True)
prompt = processor.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = processor(prompt, images, return_tensors="pt")
generation_args = {"max_new_tokens": 500, "do_sample": False, "streamer": TextStreamer(processor.tokenizer, skip_prompt=True, skip_special_tokens=True)}
print("Summary:")generate_ids = model.generate(**inputs, eos_token_id=processor.tokenizer.eos_token_id, **generation_args)
通过 OpenVINO™ 封装后的 API 函数,开发者可以非常便捷地对预训练模型进行转化压缩,并实现本地化的推理任务部署。同时基于 Phi-3.5 在小语言模型场景下强大的文本与图像理解能力,我们仅在轻薄本上便可以构建起一个完整的语言模型应用,在保护用户数据隐私的同时,降低硬件门槛。
参考资料
Optimum-intel:
https://docs.openvino.ai/2024/learn-openvino/llm_inference_guide/llm-inference-hf.html
OpenVINO Gen API:
https://docs.openvino.ai/2024/learn-openvino/llm_inference_guide/genai-guide.html
---------------------------------------
*OpenVINO and the OpenVINO logo are trademarks of Intel Corporation or its subsidiaries.
-----------------------------
![]()
OpenVINO 中文社区
微信号 : openvinodev
B站:OpenVINO中文社区
“开放、开源、共创”
致力于通过定期举办线上与线下的沙龙、动手实践及开发者交流大会等活动,促进人工智能开发者之间的交流学习。
本文分享自微信公众号 - OpenVINO 中文社区(openvinodev)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。