摘要:GaussDB (for MySQL) 冷热存储分离特性,支持用户直接针对 Innodb 的 page 进行归档和回迁操作,且无需调整上层业务即可访问冷数据。
本文分享自华为云社区《GaussDB (for MySQL) 新特性解读:冷热存储分离》,作者:GaussDB 数据库。
技术背景
业务长期运行,但随着时间推移,越来越多的数据被访问频率降低,从而变成为所谓的"冷数据"。若直接将这些冷数据删除,会面临数据丢失的风险以及高昂的恢复成本;若保持冷数据现有的存储方式不变,存储空间占用越来越多,存储成本将持续增加。
同时,在无法有效利用查询索引加速的情况下,数据表的记录膨胀会进一步降低查询效率。如若用户自己识别、分离并转存冷数据至低成本存储中,需要考虑诸多因素:
a. 如何构建脚本。从表中 dump 一行行冷数据到 OBS 等超低成本存储中,这需要借助其它计算资源完成;
b. 如何提升在线迁移效率,同时降低对现有业务性能的影响;
c. 如何保障数据一致性和可靠性,并在出现问题时快速处理;
d. 当导出的数据无法直接访问时,如何倒回到实例的表中;
…
这一系列问题,不仅涉及的改造工程量庞大,而且实施成本很高。
特性价值
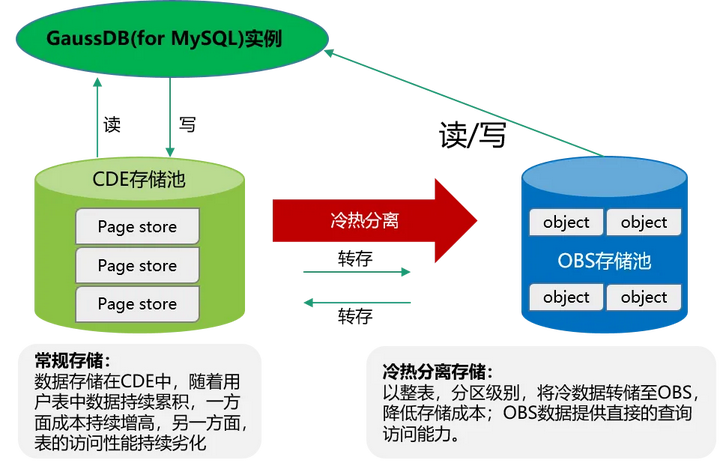
GaussDB (for MySQL) 冷热存储分离新特性,支持冷表/分区可读和混合分区管理。
![]()
冷热存储分离特性能够通过一条简单 SQL 语句实现表/分区的灵活转储,并快速将物理页并行地从 CDE 转储到 OBS 中,单位存储成本最高可降低 90%。同时,冷数据在线可读写,确保现有的基于 Innodb 的访问方式,支持事务,满足数据一致性,访问冷表无需对业务进行改造。
此外,冷热存储分离特性还支持定义规则。通过自动创建分区和指定何时为冷分区并将其自动归档到OBS中,同时可指定“冷分区对查询计划不可见”(rds_schs_enable_partition_visible) 的模式,来提升对表中热数据的访问性能,实现冷热混合分区的统一高效管理。
实现原理
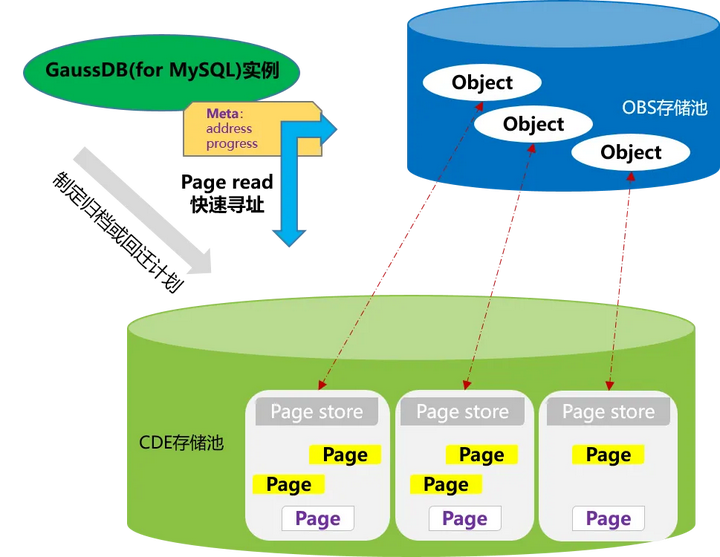
GaussDB (for MySQL) 冷热存储分离特性实现原理如下:
![]()
-
并行地从分布式存储中抽取冷数据对应的页面组装成 Object,并快速地将冷数据归档到 OBS 中,实现数据 0 丢失。
-
通过 meta 管理,使得数据操作涉及的 Page 可以快速实现定位和寻址。
-
通过 meta 管理,转储过程支持断点续传,即用户可以重试数据转储操作,确保已转储的数据无需重复转储,从而在 HA(高可用性)故障恢复中显著提高重做效率。
-
归档的数据支持备份恢复的能力,支持按指定时间点进行恢复,且恢复后这些被归档的数据能够快速投入使用。
-
通过“多版本快照的 Lock free”这一转储方式,在任何时刻,被归档的表都能够无阻塞地进行数据操作。
-
无需使用 Innodb Buffer Pool 等性能关键的资源,不仅对主机资源占用小,CPU 和内存占用始终在 10% 以下,还能提供转储过程中的流控能力,从而最大程度地避免因争抢公共 IO 资源而影响业务。
业务场景/流程
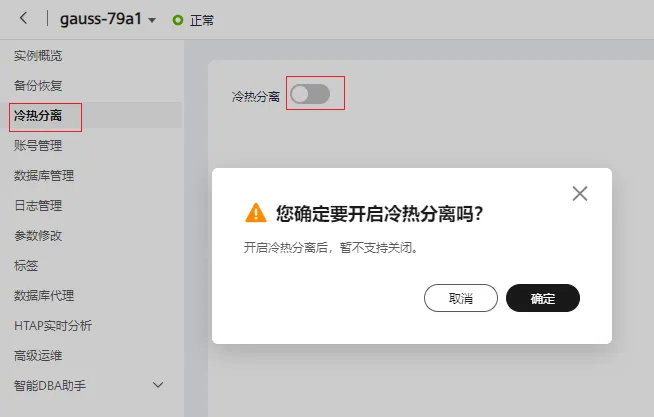
1. 新实例开启冷热存储分离
登录管理控制台,在云数据库 GaussDB (for MySQL) 的“实例管理”页面,单击目标实例名称,进入基本信息页面。在左侧导航栏,点击“冷热分离”,在“冷热分离”右侧点击图片,在弹框中点击“确定”,打开冷热分离开关。
![]()
2. 使用冷热存储分离
下面采用 DAS 数据管理服务,通过 SQL 命令来介绍冷热存储分离特性的使用。
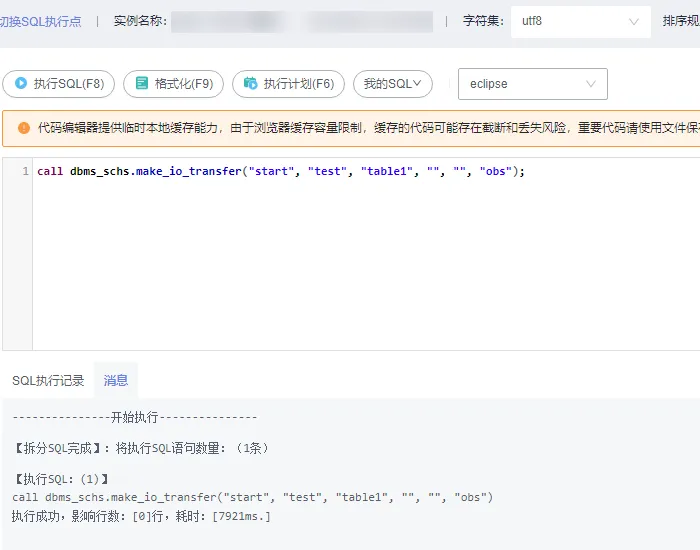
1)创建冷表
CALL dbms_schs.make_io_transfer("start", "库名", "表名", "分区名", "", "obs");
例如:
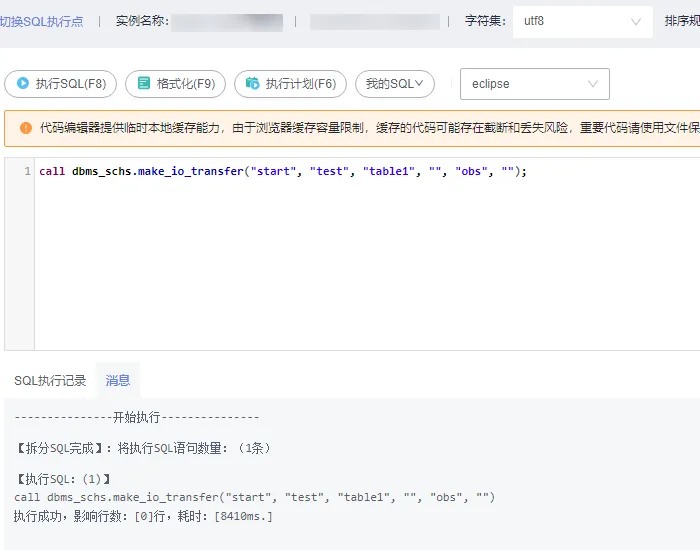
CALL dbms\_schs.make\_io_transfer("start", "test", "table1", "", "", "obs");
![]()
2)回迁冷表
CALL dbms_schs.make_io_transfer("start", "库名", "表名", "分区名", "obs", "");
例如:
CALL dbms\_schs.make\_io_transfer("start", "test", "table1", "", "obs", "");
![]()
3)查询归档或回迁状态
CALL dbms_schs.show_io_transfer("库名", "表名", "分区名");
例如:
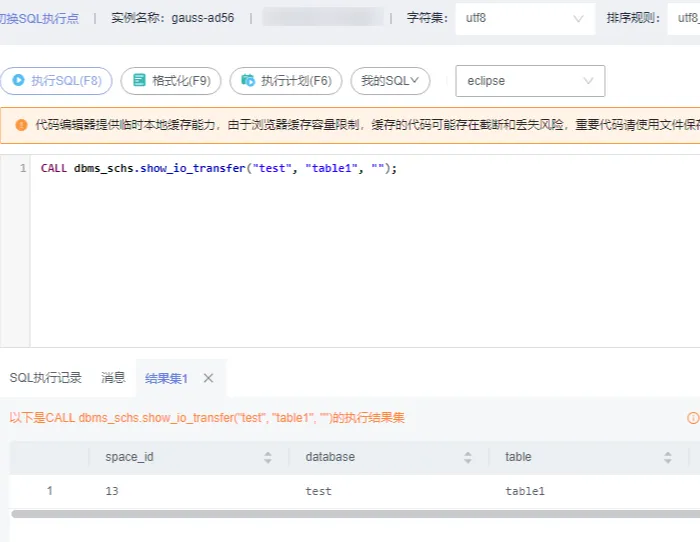
CALL dbms\_schs.show\_io_transfer("test", "table1", "");
![]()
总结
GaussDB (for MySQL) 冷热存储分离特性,支持用户直接针对 Innodb 的 page 进行归档和回迁操作,且无需调整上层业务即可访问冷数据。另一方面,在支持分区进行冷热存储分离的基础上,还支持混合分区管理,使得用户在不变更业务的情况下,可以灵活选择在查询时是否快速过滤冷分区。
附录
本文作者:华为云 GaussDB (for MySQL) 团队
点击查看:华为云 GaussDB (for MySQL) 官方产品文档
点击关注,第一时间了解华为云新鲜技术~