日前,Nature 杂志编辑 Elizabeth Gibney 刊文深入分析了大语言模型( LLM )的透明性和开放性,并揭露了所谓的“开源大模型”背后隐藏的一些问题。
Elizabeth 指出,许多声称“开源”的 AI 模型,其本质上并不开源,往往只公开了部分代码和权重模型,与之更为关键的训练数据、训练过程、核心算法均没有真正开放。
并提到,号称坚定开源的 Meta ,旗下产品 Llama 也只开放了权重( open weight ),源代码、训练数据、训练过程等参数均为闭源。
![]()
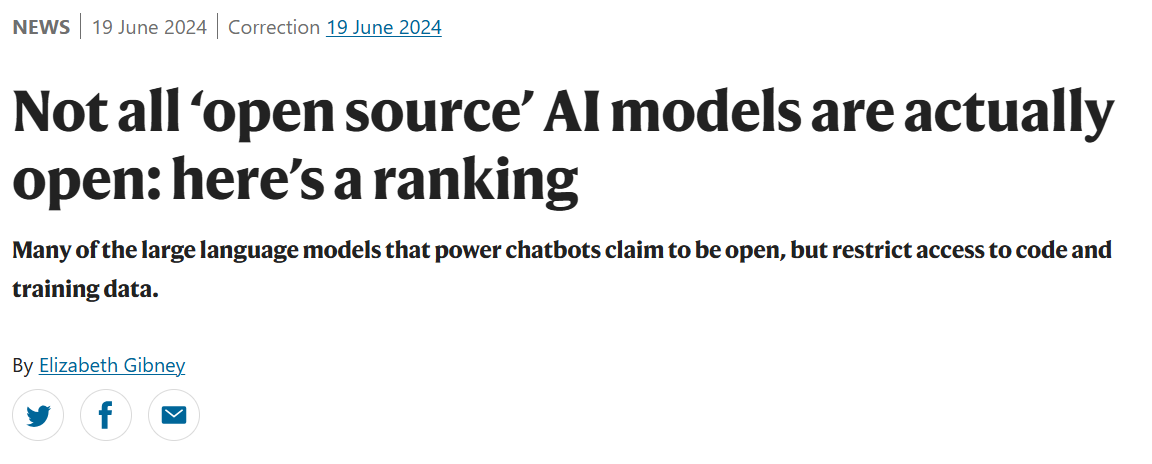
有关于这一点,荷兰奈梅亨拉德堡德大学的语言科学家 Mark Dingemanse 与他的同事 Andreas Liesenfeld 所整理的这个表单或许更为直观。(见下表)
![]()
开源(✔) 部分开源(~) 闭源(×)
我们不难发现:市面上绝大多数所谓的“开源大模型”,都只是“部分开源”,其核心代码、模型数据、预印本、应用接口均存在或多或少的闭源情况。
并且,资源相对较少的非营利性机构,例如 BigScience 、Allen Institute for AI ,较之 Meta 、Google 这样的巨头,其模型的开放程度反而越高。
开发者往往只能从这些“开源大模型”中得到一堆既定数据,后期还要做 SFT (监控微调)、安全对齐,就算是拿到了对应的源代码,开发者也不知道用什么比例的数据去训练这些参数,无法通过现有参数复现模型的训练过程,更无法根据需求进行模型的改进和优化。
况且,综合看来开源模型并不便宜,人力成本和 IT 设施的投入居高不下,不免被一些“闭源党”戏称:“免费”的才是最贵的。
正如百度的李彦宏指出,很多人混淆了模型开源和代码开源的概念,这使得如今的开源大模型,更像是在“授人以鱼”,开发者很难通过已有数据进行迭代。
Google 也针对旗下的开源大模型 Gemma 做出解释,为了在语言上更准确,Gemma 更应该被称为“开放”而非开源。
不同于开源软件,可以通过诸如 Apache 、MIT 、BSD 等开源协议明确其软件的使用、修改和分发权限,目前的一些开源大模型即便是采用了类似的许可证,往往也会附带额外的限制和条款。例如,一些大模型的许可证会严格限制使用场景、用户类型、商业用途等,远远超过了传统开源软件的规定。
甚至有些限制性条款可能还包括禁止某些商业用途、要求特定的使用声明、限制数据的再分发等。这种做法虽说在一定程度上保护了原始开发者的利益,但也大大降低了模型的开放性和使用自由,与“开源”的本质不符。
那么,如何去定义一个模型是否开源?需要开放哪些部分才是有效开源?成为开源大模型当下急需明确的问题。
26 年前定义开源的 OSI,现在要定义“开源大模型”
其实,早在“开源大模型”刚刚出现的时候,Open Source Initiative(开源促进会,简称:OSI)就曾提到:“随着开源 AI 的日趋复杂,传统意义上的开放源代码,以及过去我们所使用的开源协议,已经不足以保证开源大模型在其使用、修改、分发以及共享时的自由与透明。”
可见,推进“开源 AI ”相关定义的完善,是保证开源 AI 健康发展的先导条件。
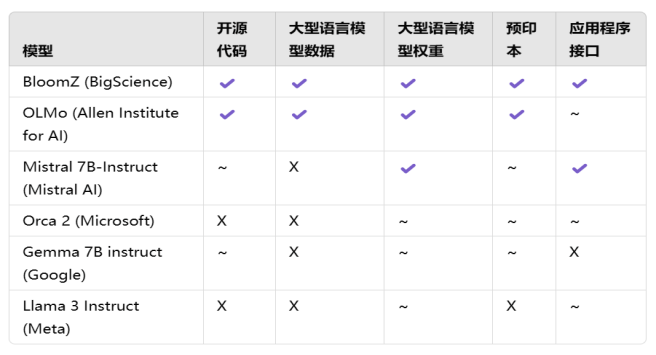
而就在最近,守护了开源定义 26 年,并推动开源软件( OSS )走向成功的 OSI 宣布推出最新的 “开源 AI 定义-草案 v.0.0.9 ” ,进一步明确什么是开源 AI ,以及大模型开源的必要组成部分,并指出系统的所有组件都需要满足开源标准,该系统才被视为开源。
![]()
在最新的草案中,OSI 详细阐述了一个大模型如果要被视为“开源模型”的三个必要条件:
-
数据部分:关于用于模型训练的数据,应该详细到足以让一个专业人员能够通过相同或类似的数据重新建立起一个基本等效的模型,需要开放的数据包括:训练方法和技术、使用的训练数据集、数据集的来源、数据的获取方式,以及数据清理方式等。
-
源代码部分:在 OSI 批准的许可证下提供用于训练和运行该模型的源代码,包括用于预处理数据的代码,用于训练、验证、测试的代码,推理代码和模型框架。
-
权重部分:在 OSI 批准的条款下提供模型权重和参数,包括关键训练节点的检查及优化。
针对“机器学习系统”,草案着重提到:AI 模型是由模型架构、模型参数(包括权重)和用于运行模型的推理代码组成;而 AI 权重是一组学习的参数,这些参数需要覆盖模型架构的输入和输出。“开源模型”和“开源权重”必须包含用于派生这些参数的数据信息和代码。
这意味着,如今市面上的绝大多数开源大模型不得不进一步增进模型的开放程度,对现有的数据和成果进行校准,以符合草案的要求,并投入一定的时间和资源进行对相关许可证的适配,真正做到“授之以渔”。
而重点提到的“训练过程”和“训练方法”的开放,无异于利好广大开发者和研究人员,他们可以通过完整的训练路径,建立起与自身环境更为匹配的新模型,从而推动开源大模型的进一步发展。
当然,这版草案的发布也对闭源模型厂商带来了一定的压力,毕竟越开放,就意味着会有越来越多的人加入开源大军,原本的商业格局也可能发生变化。但总归而言,竞争孕育着发展,如果“开源”能驱动“闭源”发展,这也不失为大模型领域的一段佳话。
这份草案的稳定版预计于 10 月正式发布,我们一起期待。
16个维度看一个大模型的开放与透明程度
之所以“开源大模型”如此难以界定,不外乎它本身的复杂性。
随着深度学习算法的不断演进与创新,开源大模型从传统的神经网络架构发展到如今的 Transformer 架构、MoE 架构等,每一种架构都有其独特的设计理念和实现方式。其次,数据的收集、筛选、比对和标注大规模的高质量数据也是一项艰巨的任务,以 Llama 3 为例,它使用了超过 15 万亿( 15T )个 token 的公开数据进行预训练,其训练量早已超过前代 Llama 2 六倍不止。
说到底,开源大模型就像一个黑盒,其内部除了代码部分,还有许多其他内容,这种情况下,我们会发现,以往 OSI 定义的开源(OSD),他们审核通过的开源协议,其实就没办法直接套用到一个所谓的大模型“项目”里了。怎么办呢?
针对这种情况,除了上文 OSI 提出的“顶层设计”,LF AI & Data 基金会也发布了“模型开放性框架- MOF ”,通过 16 个关键组件去客观评估和分类机器学习模型的完整性与开放程度,以帮助开发者更好地挑选满足自身需求的开源大模型。
![]()
该框架确定了构成完整模型开源的 16 个关键组件,涵盖:数据集、预处理代码、模型架构、模型权重&参数、训练代码、推理代码、评估代码、评估数据、评估结果、模型元数据、模型卡等。
对于每个组件,MOF 还根据工件类型规定了其开源协议的使用标准,帮助原始开发者在开源过程中挑选所需要的相关协议,例如:
-
代码的开源许可( Apache 2.0 、 MIT )
-
数据集和模型参数的开放数据许可( CDLA-Permissive、CC-BY )
-
文档和内容/非结构化数据的开放内容许可( CC-BY )
当这 16 个组件所采用的协议类型划分完,那么大模型的组成部分的“合规性”也就基本没问题了,对照使用即可。下一个问题:怎么整体来界定大模型的开放程度呢?
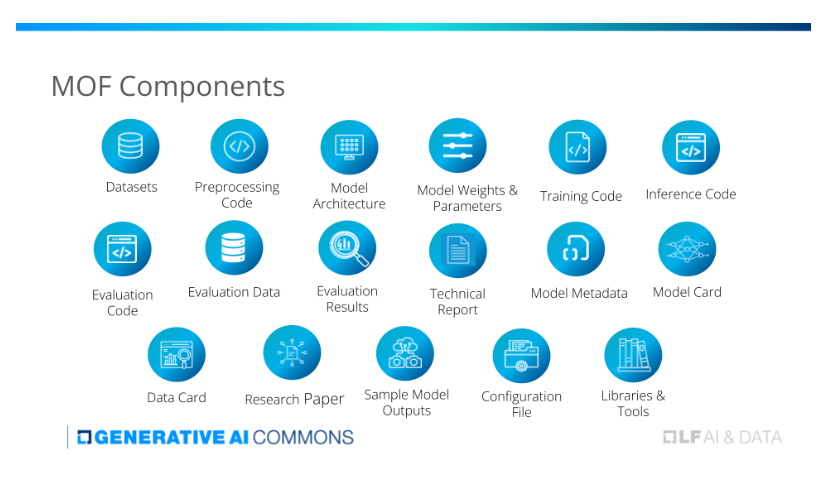
对此,MOF 设计了一个三层模型开放模式,分别是 Class Ⅲ - Open Model 、Class Ⅱ - Open Tooling 、Class Ⅰ - Open Science 。
通过对前面提到的 16 个组件的不同“组合”,将大模型的开放与透明程度进行分类,左侧为分类,右侧则是需要开放的对应组件。(见下表)
![]()
-
Class Ⅲ - Open Model :要求在开放许可证下公开发布核心模型(架构、参数、基本文档),允许模型使用者使用、分析和构建模型,但限制了对开发过程的洞察。
-
Class Ⅱ - Open Tooling :以 Ⅲ 类为基础,开放包括用于训练、评估和运行模型的全套代码,以及关键数据集。开放这些组件是为了使社区能够更好地验证模型和调查问题,也是朝着可重复性迈出的重要一步。
-
Class Ⅰ - Open Science :按照“开放科学”原则发放所有文件,除了 Ⅱ 类组件外,还包括原始数据集、一篇详述整个模型开发过程的全面研究论文、中间检查点、日志文件等,为端到端开发提供完美的透明度,从而增强协作、审查和开发的进度。
怎么理解呢?举个简单的例子,某大厂说他们开源了一个大模型 α,将他们开放的组件放在 MOF 这个标准里一对照,发现开放了模型框架、模型参数、技术报告、评估结果、模型卡片、数据卡片,那么这个大模型 α 就属于 Class Ⅲ 这一层级,只能满足模型使用者使用、分析,但限制了进一步的优化与开发,毕竟 Class Ⅲ 的开放程度是最弱的。
如果该模型想要进入到 Class Ⅱ ,那么它不仅要开放 Class Ⅲ 的六个组件,还要开放 Class Ⅱ 包含的训练代码、推理代码、评估代码、评估数据,以及支持库和工具。
这里面其实隐含了一个事实,LF AI & Data 的 MOF 框架,从根本上并没有直接去判定一个大模型“开源”,还是“不开源”,前面我们也说过了,现实情况并没有那么简单,MOF 只是对“开放和透明程度”进行分类。曾经打着“开源”旗号来博眼球这条路自然也就走不通了,想要更多开发者的加入与协作,必然要做到更开放、更透明、更公平。
综合来看,大模型开源与否,并非一个简简单单的二元问题,毕竟时代产物,必然会有其时代的局限性。无论是 OSI 还是 LF AI & Data ,与其说它们是在定义“开源大模型”,倒不如说它们是在进一步拓展“开源”所能惠及的领域,真正将“开放”传递下去。
参考资料: