这个算是一个经典面试题了,虽说是一个场景题,但是也算是老八股了。
今天就从系统设计的角度来和小伙伴们聊一聊这个话题。
一般来说秒杀系统需要考虑到下面这样一些问题:
- 瞬时高并发流量
- 热点商品数据
- 库存管理
- 重复下单
- 黄牛
接下来我们就这里提到的点逐一进行分析。
本文主要和大家讲思路,不讲具体做法,具体做法在松哥之前的文章中很多已经和大家聊过了。
一 瞬时高并发流量
应对瞬时高并发流量,不是某一种方案就可以,是一个组合拳。另外大家要记得,系统设计没有银弹。
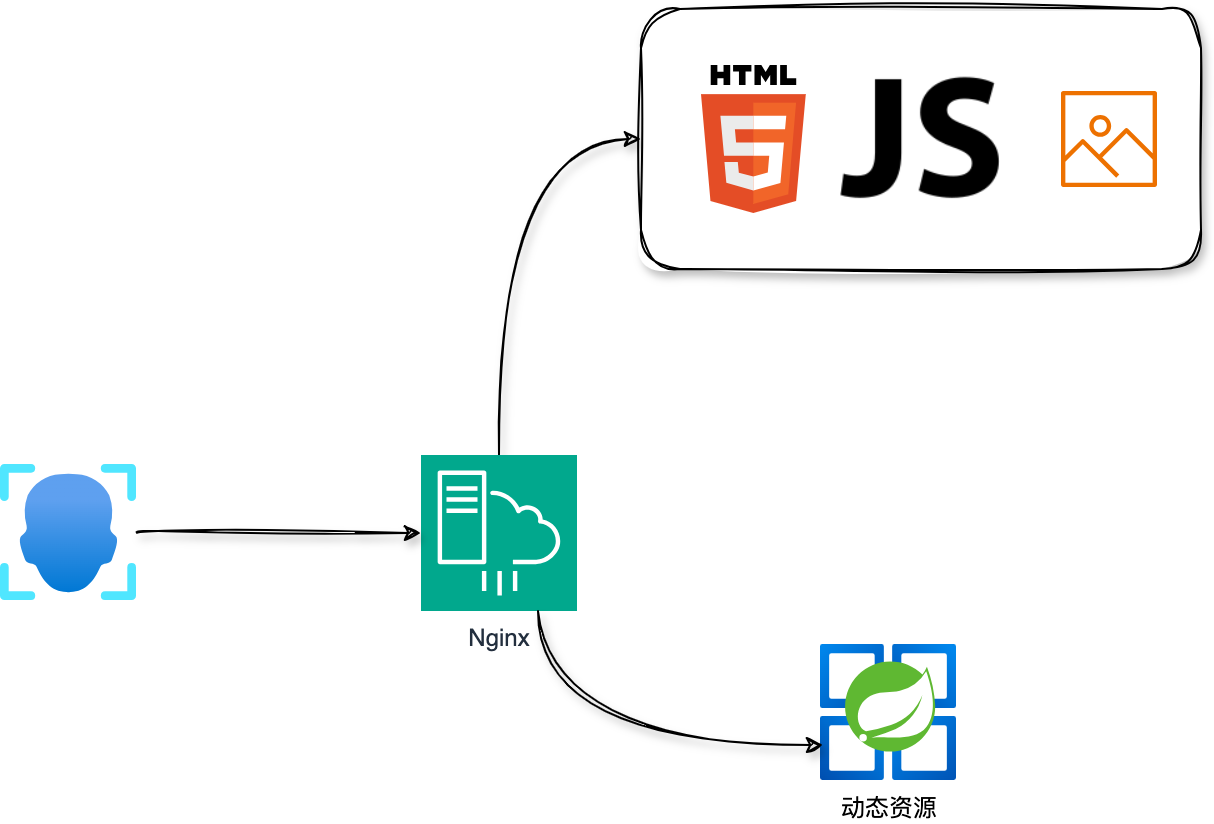
1.1 动静分离部署
这算是一个基本要求了,引入 Nginx,将静态资源和动态资源利用 Nginx 分流,静态资源直接返回,动态资源则转发给后端服务器去处理。
![]()
这一点其实还蛮重要,松哥之前就有遇到这个问题,一开始没有动静分离部署,后来动静分离部署之后,系统并发能力提升 2 倍以上。
不过如果愿意花点钱,把静态资源都交给云服务商的 CDN 来处理,那就更好了。
一般来说使用 CDN 是比较划算的,因为 CDN 流量费往往比云主机的流量费便宜。
1.2 数据库独立部署
这个也算是基操了,将应用程序和数据库部署到一起,往往无法让数据库发挥自己的极限性能。正常来说,一台 1C2G 的服务器上只部署 MySQL,就能做到每秒处理 200 次查询请求,这样的数据基本上就能满足一个每天 100W PV 的小网站了。
但是你想想,1C2G 的服务器部署 MySQL 和应用程序的话,估计卡的没法用了。
将 MySQL 和应用程序部署到一台服务器上,往往会因为两者互相影响而降低整体的并发性能,具体来说可能会发生这些问题:
- 高并发导致 CPU 被耗尽,进而 MySQL 响应变慢。
- 应用程序处理请求的时候需要等待更长的时间获取数据库的数据,这个过程占用了大量的内存。
- 系统内存紧张导致 MySQL 中缓存的数据被回收,进而拖慢 MySQL。
- 如此循环往复,系统最终越来越慢甚至崩溃。
因此我们要做的第二件事情就是将数据库和应用程序独立分开部署。
1.3 流量过滤
秒杀本来就是一个看运气的事,谁秒到算谁的,没秒到就算失败,产品数量往往有限,秒到的必然是少数人,所以在请求从客户端到达服务端并处理的过程中,可以对流量进行层层过滤。
一般来说,请求主要经过如下节点:
![]()
由于秒杀的随机性,我们可以这么做:
- Client 处也就是用户请求发起的地方,我们就可以随机丢弃一些请求,直接弹出秒杀失败、网络阻塞等等。
- 当请求到达 Nginx 之后,可以在 Nginx 处进行限流,利用像 limit_req_zone、limit_req_conn 等模块来实现不同的限流策略。
- 当请求从 Nginx 上转发到 Java 服务上之后,我们可以继续使用一些限流工具,比如 Sentinel,或者自己利用 Redis 写限流工具也可以,在这里继续进行限流。
- 当请求突破层层关卡到达业务层之后,对于实时性要求不高的数据,直接从缓存查询,缓存优先查本地缓存,其次是远程分布式缓存如 Redis,缓存中没有数据的话,最后再是 MySQL。
1.4 页面静态化
对于热点数据页面可以进行静态化处理。
比如秒杀商品页、秒杀商品详情页等等这些热点页面直接自动进行静态化处理,这样用户每次访问的时候,直接返回现成的页面,就不用走数据库了。
如果页面数据发生变化,重新自动生成静态页面即可。
二 热点商品数据
接下来就是热点商品数据的处理了。
秒杀这种事情,在秒杀活动开始之前,我们基本上就能够确定哪些数据是热点数据了,所以处理处理起来相对来说并不难。
不过需要注意的是,能缓存的数据肯定是一些商品信息类的数据,对于像库存这类实时性要求极高的数据,是不适合缓存的。
2.1 缓存预热
缓存预热主要从两方面入手:
- 本地缓存预热
- Redis 缓存预热
查询的时候先查本地缓存,没有再查 Redis 缓存,这样能够有效避免 Redis 的热 Key 问题。
2.2 数据拆分
另一方面就是我们要避免热点数据聚集到一起,将热点数据进行拆分。避免从一个缓存处去获取多个热点数据,这样就能降低缓存的压力。
比如:
可以对这些热点数据进行拆分,其实拆分之后,热点数据也就不那么"热"了。
三 库存管理
库存因为实时性要求比较高,因此就不方便用缓存。
库存管理要是做不好,可能会发生超卖或者少卖。
那么库存管理怎么做呢?保险的方案当然就是直接去数据库扣减,但是数据库并发能力有限,所以往往还需要结合缓存来做。
我们分别来看。
3.1 数据库扣减
数据库扣减,为了避免把库存扣成负数,一般来说我们有两种思路:
- 悲观锁
- 乐观锁
在高并发场景下,悲观锁会导致更新效率降低很多;而乐观锁则会导致大量的失败。似乎都不是一个很好的选择。
其实我们只是要保证库存不被减为负数而已,那么其实就可以在更新 SQL 中添加一个条件就行了,像下面这样:
***** and 库存>=0
大致上这样就可以了。
不过只是这样做还不够,因为数据库的并发能力在哪摆着呢。所以我们还是要利用缓存。
3.2 缓存扣减
由于 Redis 本身就是单线程执行的,因此我们再结合上 Lua 脚本,就可以保证扣减库存这个操作的原子性。
在 Lua 脚本中我们可以获取到库存数据,然后判断库存,没问题再进行扣减。
Redis 本身的高性能+单线程执行+Lua 脚本的原子性,这三点结合起来就可以确保上述操作是没有问题的。
3.3 最佳实践
在具体实践中,往往是 3.1 和 3.2 结合起来。
具体流程是这样:
首先 Redis 做扣减,扣减完了之后,发送一条消息给 MQ,应用程序再去消费这条消息,消费消息时完成数据库的扣减。
这个过程中我们需要确保好 MQ 消息的可靠性和幂等性,处理好消息积压。
当然,稳妥起见还需要有对账机制,定时拉取 Redis 中的数据和数据库中的数据进行对比,保证数据的一致性。
四 重复下单
秒杀场景下用户由于比较焦急,频繁点击可能造成重复下单,因此我们需要处理好下单操作的幂等性。
这个也有很多思路,需要多管齐下。
4.1 前端置灰
前端用户点击之后,就对秒杀按钮进行置灰操作,同时提醒用户目前正在进行秒杀。
这是基操,但是不能从根本上解决问题,还得配合后段幂等性处理。
4.2 后端幂等性处理
后段幂等性处理有很多方案,可以利用 Token 机制,这个松哥之前也有很多文章介绍,不多说。
同时因为秒杀这种场景往往是限购的,因此在用户下单的时候可以判断是否有在途订单或者用户是否已经下单,进而决定当前下单操作是否能够成功。
五 黄牛
薅羊毛的黄牛也是我们要考虑的一个问题。
5.1 识别黄牛
首先我们要识别出来哪些用户可能是黄牛,一般来说,我们可以通过如下方式来识别:
- 请求频率:监测用户的请求频率,若某一账户的请求过于频繁,则可能是黄牛使用自动化工具发出的。
- 访问模式:分析用户的访问模式,例如短时间内大量的重复请求或者非正常人类行为的访问模式。
- IP 地址:检查请求来源的 IP 地址,对于同一 IP 地址下频繁的请求进行限制或标记。
如果公司有足够的人力资源,这块可以建立预测模型,通过模型去分析哪些人可能是黄牛。
5.2 防止黄牛
当我们识别出来黄牛之后,一般来说有如下一些办法:
- 图形验证码(CAPTCHA):在关键环节加入图形验证码,要求用户识别并输入相应的字符,以防止自动化工具的使用。
- 滑动验证:在关键环节采用滑动验证等交互式验证方式,这类验证方式难以被自动化工具模拟,这也是大家目前见到的最多的验证方式了。
- 行为验证:基于用户的行为轨迹(如鼠标移动轨迹、键盘输入模式等)来进行验证,这个目前松哥只在京东图书上见过这种验证方式。
- 请求频率限制:对识别出来的用户或 IP 地址的请求频率进行限制,超出限制则暂时禁止访问,这块利用 Nginx 或者 Sentinel 就能实现。
- 黑名单:对于已知的黄牛 IP 地址或账户进行封禁处理,这块可以直接在 Nginx 上处理,也可以在网关如 Spring Cloud Gateway 上处理。
- 动态调整:根据系统的实时负载情况动态调整限流阈值。
六 小结
秒杀是一个大工程,以上是松哥和大家分享的一些实现思路,具体落实下来还有很多细节需要处理。
借助本文希望小伙伴们在面试的时候不怯场,能够回答出来。
欢迎小伙伴们在评论区分享自己的方案或者提出补充。