随着生成式 AI 概念的火爆,以 ChatGPT、通义大模型为代表,市场上涌现了一系列商用或者开源的大模型,同时基于大语言模型(LLM )以及 AI 生态技术栈构建的应用以及业务场景也越来越多。
众所周知,LLM 包含数十亿甚至万亿级别的参数,其架构复杂,训练和推理涉及大量计算资源。这些特性使得它们在实际应用中可能表现出意料之外的行为,同时也带来了性能、安全性和效率等方面的挑战。
![]()
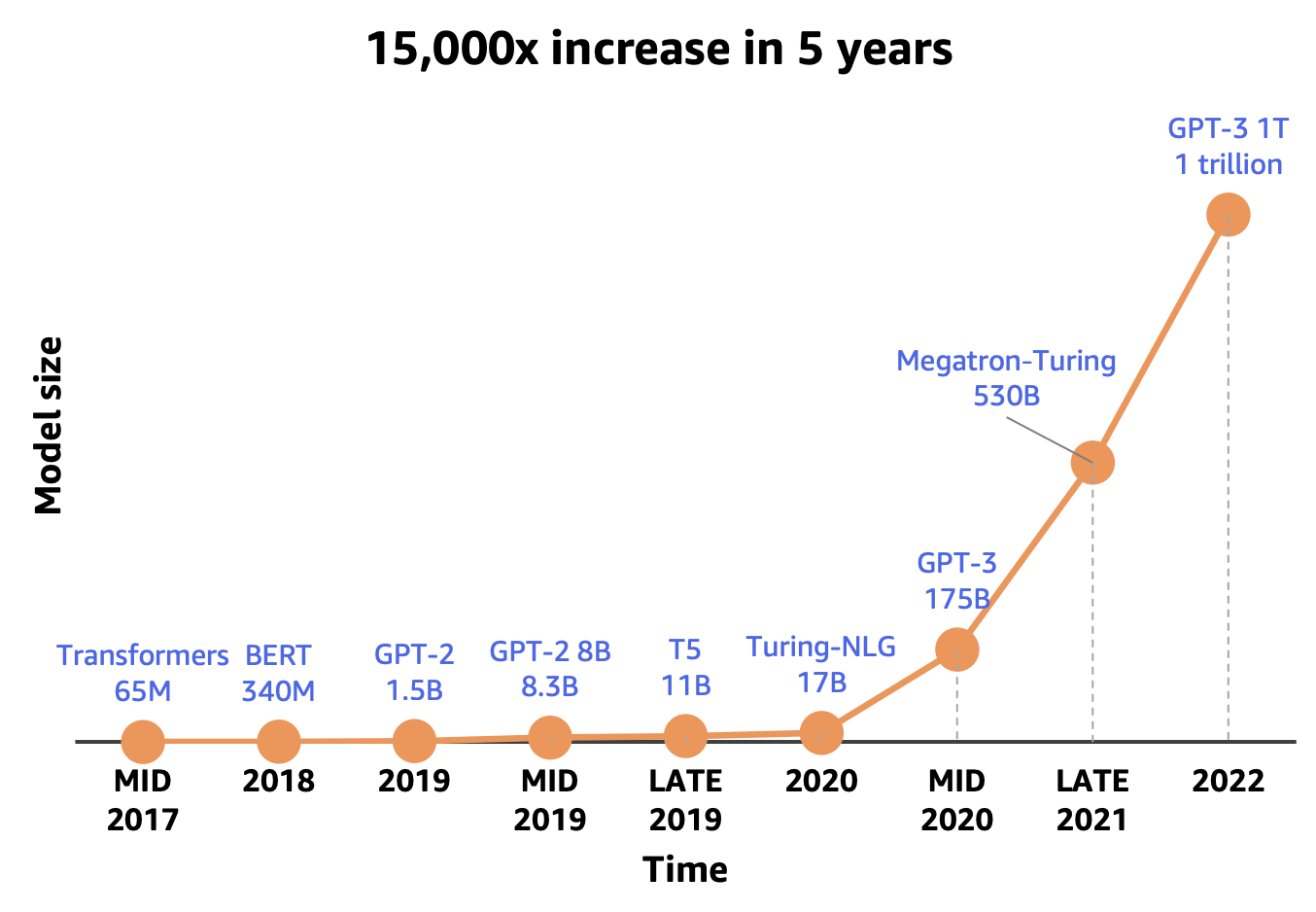
LLM参数量不断增长
(图片来源:https://www.alidraft.com/2023/12/19/deploy-your-llm-model-on-cloud-efficent/)
那么,如何监控并保障大模型应用上线的性能以及用户体验?如何支持复杂拓扑场景下 LLM 应用领域的链路可视化分析以及问题根因定位?需要从成本以及效果等方面获得线上实际表现,辅助选择、分析、评估以及优化迭代大语言模型等。因此,针对 LLM 应用技术栈,构建行之有效的可观测能力解决方案就成为关键。
由于模型本身的复杂性、数据处理的规模以及应用的动态环境,实现 LLM 应用的可观测性面临着诸多难点,比如:
-
数据量与复杂度:
-
性能与实时性:
-
安全与隐私:
-
集成与兼容性:
-
语义理解和模型解释:
-
动态调整与自适应:
-
成本与效率:
解决这些难点通常需要采用先进的数据处理技术、高性能的计算架构、安全的通信协议、智能的分析算法以及灵活的资源配置策略。此外,持续的监控和迭代改进也是保持可观测性系统有效性的关键。
当然,这些问题和挑战,对阿里云技术专家蔡健来说,已经有了相应的解决方案。蔡健从事可观测产品 ARMS 与 EagleEye 的研发、设计与布道,具备丰富的可观测领域技术架构以及实践经验,成功推进 ARMS 应用性能监控和应用安全(RASP)融合解决方案落地,关注 APM 以及 OpenTelemetry 开源社区生态等最新动态。目前关注大语言模型领域可观测需求场景,探索支持 LLM 应用层到底层基础设施的全栈可观测能力解决方案以及最佳实践。
8 月 15 日至 16 日,GOTC 2024 大会将于上海张江科学会堂举行。在“LLMOps 最佳实践”论坛,蔡健将以《LLM 应用可观测解决方案探索与实践》为题发表演讲,深入探讨 LLM 应用可观测的关键关注点、高质量数据采集与上报方法,并详细介绍阿里云的LLM应用可观测解决方案,分享客户实践案例,展望未来 LLM 应用可观测的发展趋势与面临的挑战。
![]()
GOTC 2024 与上海浦东软件园联合举办,并结合 “GOTC(全球开源技术峰会)” 与 “GOGC(全球开源极客嘉年华)”,旨在打造一场全新的开源盛会。
全球开源技术峰会(Global Open-source Technology Conference,简称 GOTC)始于 2021 年,是面向全球开发者的开源技术盛会;2024 全球开源极客嘉年华(GOGC 2024)由浦东软件园携手 S 创共建,与开源中国、Linux 基金会等品牌联合呈现。
此次大会将集结全球范围内对开源技术充满热情的开发者、社区成员、创业者、企业领袖、媒体人,以及各开源项目应用场景的产业精英、跨界才俊与年轻力量。通过主题演讲、圆桌讨论、创新集市、人才集市、黑客松、技术展示和互动工作坊等形式,与会者将有机会交流实践经验、探索前沿技术,让我们一起激发创新活力、展示开源魅力、促进跨领域合作。
更多大会信息,访问官网查看:https://gotc.oschina.net