一、前言
在进行自动化测试的过程中, ocr 文字识别一直是大家最想要实现以及最需要的能力,今天就来介绍一个由百度飞浆提供的一个免费的 ocr 识别库—— PaddleOCR ,以及探讨一下, PaddleOCR 与 Airtest 协作能擦出怎么样的火花~
在使用 PaddleOCR 之前,需要在自己的本地环境中安装对应的 PaddleOCR 库,方便我们后续调用。我们建议是安装到本地的python环境内,后续将AirtestIDE的python环境更换为本地python环境即可。
#安装PaddlePaddle
pip install paddlepaddle
#安装PaddleOCR whl包
pip install paddleocr
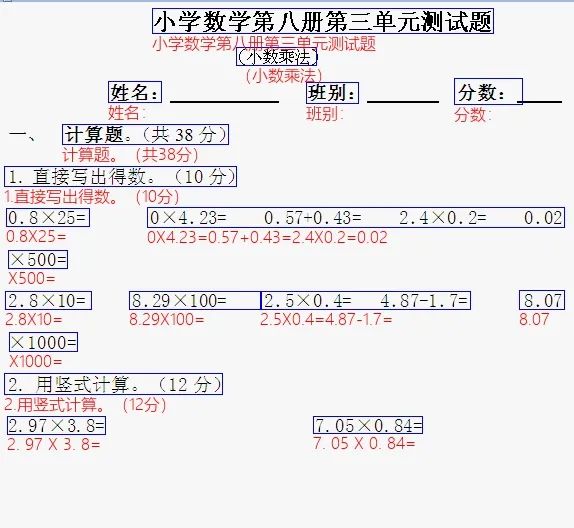
在开始使用之前,我们来了解一下 PaddleOCR 识别的效果以及返回的情况, PaddleOCR 主要是通过我们传入需要识别的图片,通过调用 PaddleOCR 模型库,去进行识别并返回识别结果或识别后的图片,例如下图这样:
通过 PaddleOCR 识别打印文字信息如下,分别以列表的形式返回了所识别到的文字的左上角坐标、右上角坐标、右下角坐标、左下角坐标、识别到的文字以及识别置信度:
[[[154.0, 9.0], [492.0, 9.0], [492.0, 33.0], [154.0, 33.0]], ('小学数学第八册第三单元测试题', 0.9987085461616516)]
[[[238.0, 47.0], [319.0, 47.0], [319.0, 66.0], [238.0, 66.0]], ('(小数乘法)', 0.9819607138633728)]
[[[109.0, 80.0], [160.0, 80.0], [160.0, 103.0], [109.0, 103.0]], ('姓名:', 0.9986250996589661)]
[[[305.0, 81.0], [358.0, 81.0], [358.0, 104.0], [305.0, 104.0]], ('班别:', 0.9987398982048035)]
.............
接下来,我们来看一下如何使用 PaddleOCR 库来识别图像中的文字,并与 Airtest 进行联动,实现基于 ocr 的文字识别点击功能。
首先,我们需要导入 PaddleOCR 库,并准备好要识别的图片文件。通过调用 PaddleOCR 的接口,我们可以将图片路径作为参数传入。在识别过程中, PaddleOCR 会在 result 变量中返回识别结果,其中包括文本框的坐标和对应的文字内容。
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = './imgs/11.jpg'
#开始ocr识别图片文字信息
result = ocr.ocr(img_path, cls=True)
通过 PaddleOCR 获取的图像中的文字信息,我们可以利用 Airtest 提供的接口和语句,创建一个名为 ocr_touch() 的函数。这个函数将执行以下步骤:
-
-
-
从
PaddleOCR 获取识别到的文字及其在图像中的位置坐标。
-
利用
Airtest 根据坐标信息点击文字的中心点。
通过这种方式, ocr_touch() 函数将实现从识别到点击的自动化操作,简化了整个流程。具体参考代码如下:
def ocr_touch(target_text) :
# 截屏
pic_path=r"./now.png"
snapshot(pic_path)
# 使用PaddleOCR识别文字
ocr_result = ocr.ocr(pic_path, cls=True)
# 遍历识别结果,找到目标文字的坐标
target_coords = None
for line in ocr_result:
for word_info in line:
#获取识别结果的文字信息
textinfo = word_info[1][0]
print(textinfo)
if target_text in textinfo:
# 获取文字的坐标(中心点)
x1, y1 = word_info[0][0]
x2, y2 = word_info[0][2]
target_coords = ((x1 + x2) / 2, (y1 + y2) / 2)
break
if target_coords:
break
# 点击坐标
if target_coords:
touch(target_coords)
else:
print(f"未找到目标文字:{target_text}")
三、PaddleOCR与Airtest协作案例
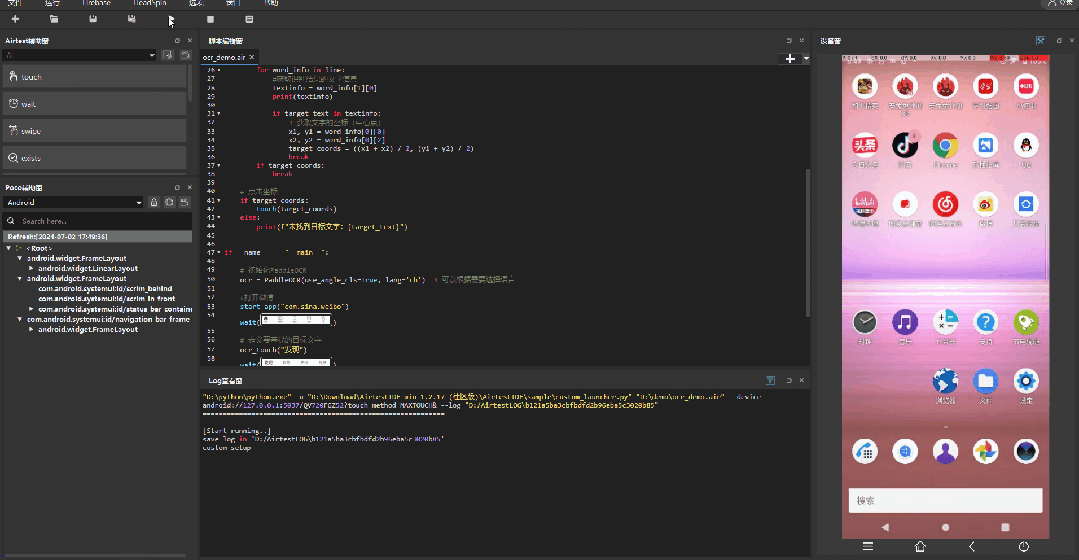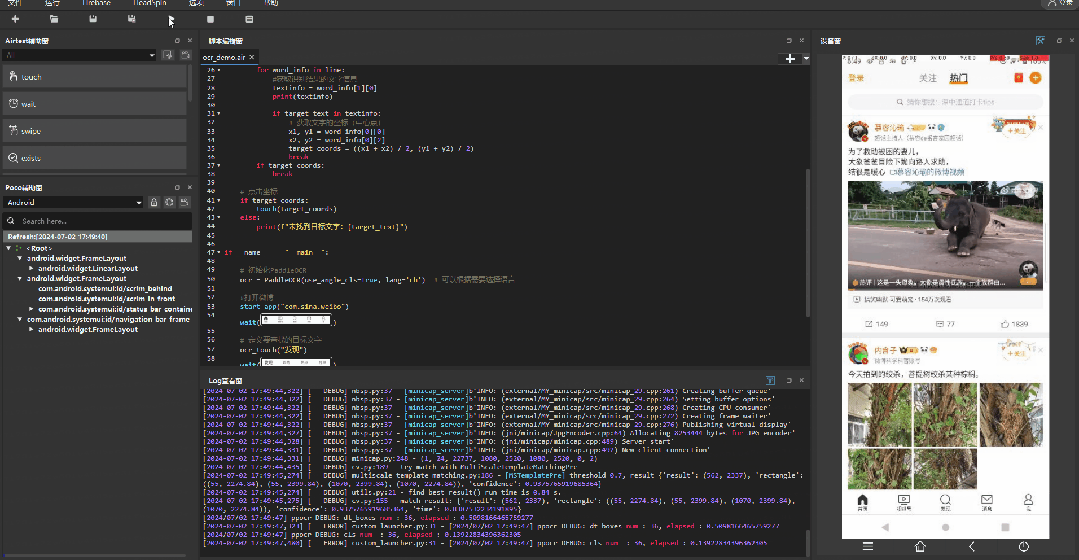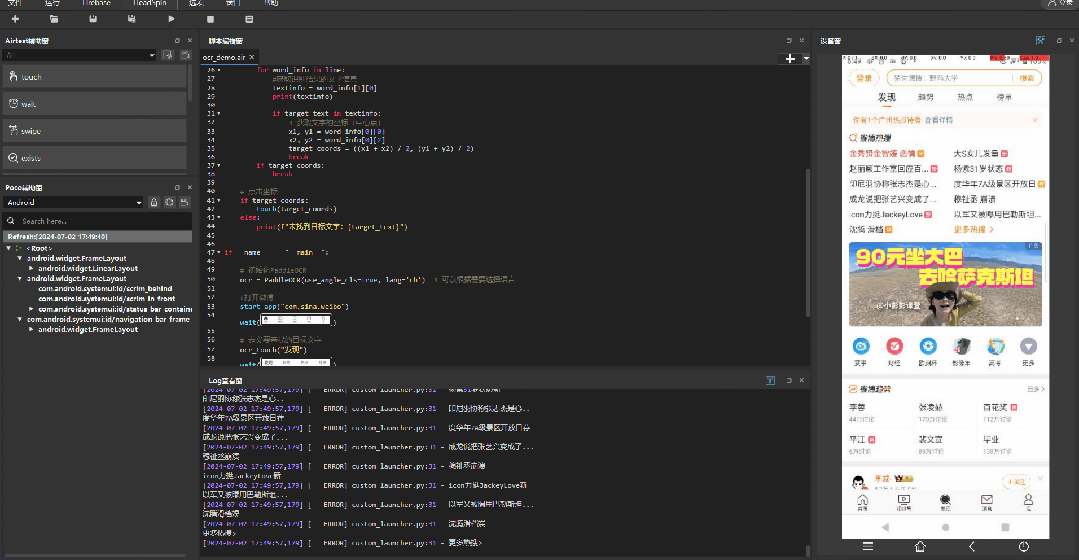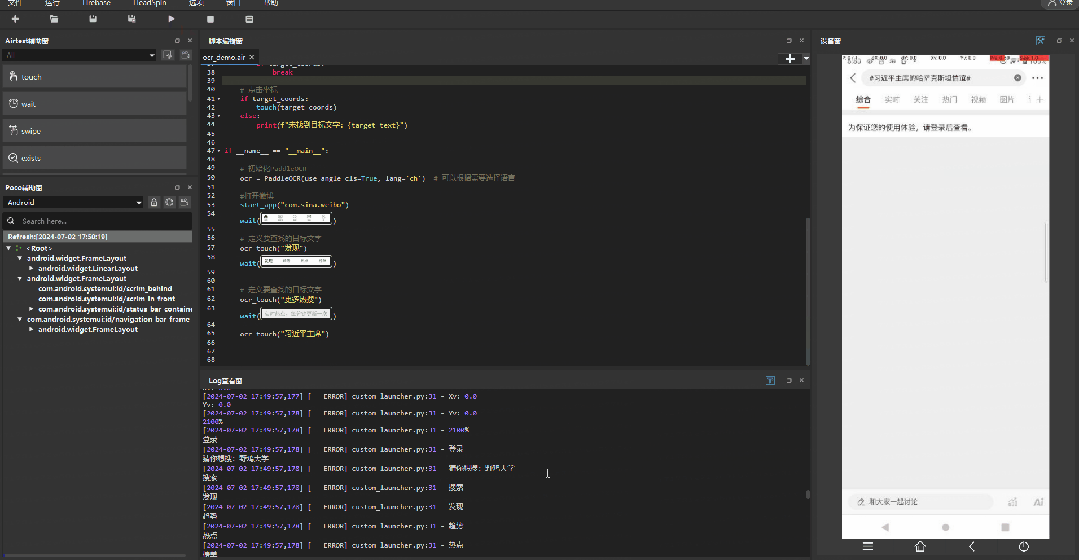
那么我们一起来通过一个小案例来看一下,在日常测试中的表现情况吧~
![]()
# -*- encoding=utf8 -*-
__author__ = "Airtest"
from airtest.core.api import *
auto_setup(__file__)
from paddleocr import PaddleOCR
def ocr_touch(target_text) :
# 截屏当前画面
pic_path=r"./now.png"
snapshot(pic_path)
# 使用PaddleOCR识别图片文字
ocr_result = ocr.ocr(pic_path, cls=True)
# 遍历识别结果,找到目标文字的坐标
target_coords = None
for line in ocr_result:
for word_info in line:
#获取识别结果的文字信息
textinfo = word_info[1][0]
print(textinfo)
if target_text in textinfo:
# 获取文字的坐标(中心点)
x1, y1 = word_info[0][0]
x2, y2 = word_info[0][2]
target_coords = ((x1 + x2) / 2, (y1 + y2) / 2)
break
if target_coords:
break
# 使用Airtest点击坐标
if target_coords:
touch(target_coords)
else:
print(f"未找到目标文字:{target_text}")
if __name__ == "__main__":
# 初始化PaddleOCR
ocr = PaddleOCR(use_angle_cls=True, lang='ch') # 可以根据需要选择语言
#打开微博
start_app("com.sina.weibo")
wait(Template(r"tpl1719891218354.png", record_pos=(0.021, 0.998), resolution=(1080, 2520)))
# 传入并点击“发现”
ocr_touch("发现")
wait(Template(r"tpl1719891346582.png", record_pos=(0.008, -0.957), resolution=(1080, 2520)))
# 传入并点击“更多热搜”
ocr_touch("更多热搜")
wait(Template(r"tpl1719891584526.png", record_pos=(-0.291, -0.606), resolution=(1080, 2520)))
# 传入并点击“热搜”
ocr_touch("热搜")
四、Airtest_ocr的表现情况
在 Airtest 私有云内,我们也有对应的一款商业化的 Airtest-ocr 的文字识别库,这个库已经封装好对应的 ocr 的识别以及对应的操作执行能力,具体介绍可以看 往期推文 ,我们是封装好了日常使用较多的操作,在购买我们的商业化版本后,可以直接调用的~
# 点击某文字
ocr_touch("开始")
# 与 ocr_click("开始") 等价
# 双击某文字
ocr_double_click("开始")
# 某些情况下,文字处于按钮附近(比如按钮下方),使用offset设置点击偏移量
ocr_touch("开始", offset=(0, -20))
# 以“开始”文字的中心为起点, x轴不偏移,y轴向上偏移20个像素点
ocr_double_click("开始", offset=(0, -20))
# 指定高优先级区域 (version>=1.0.10)
ocr_touch("开始", location=(100, 100), threshold=0.98)
# 对于置信度高于0.98的多个 “开始”, 优先点击靠近 (100,100) 的
# ocr_swipe 与 swipe函数类似
ocr_swipe("生活", "学习")
# 从“生活”滑向“学习”
ocr_swipe("生活", vector=(0, 100))
# 从“生活”向下滑动100个像素
ocr_swipe((780, 1842), (780, 1000))
# 从坐标1滑向坐标2
......
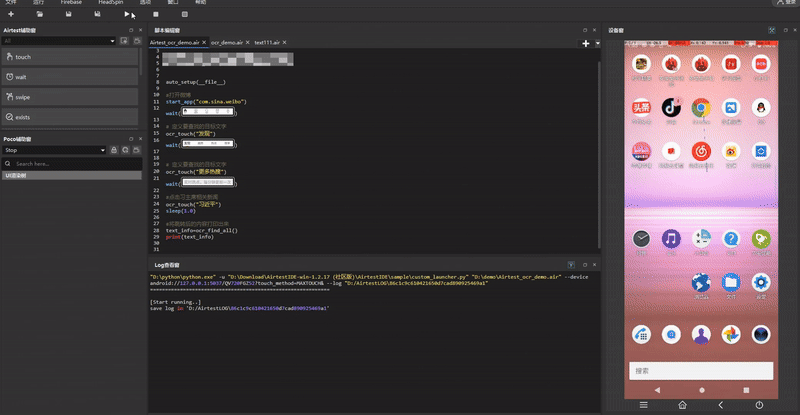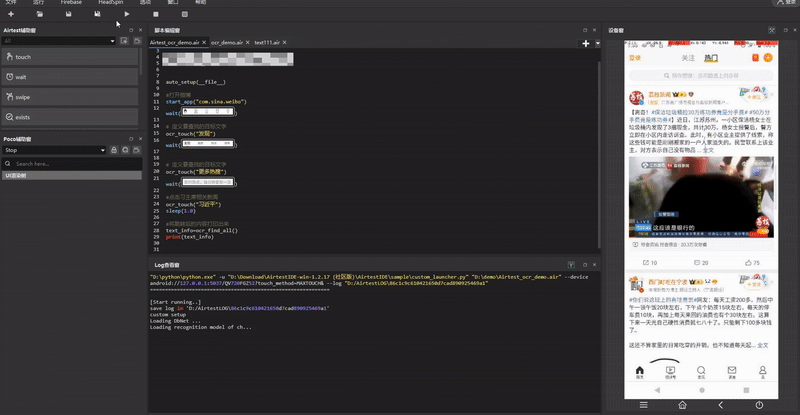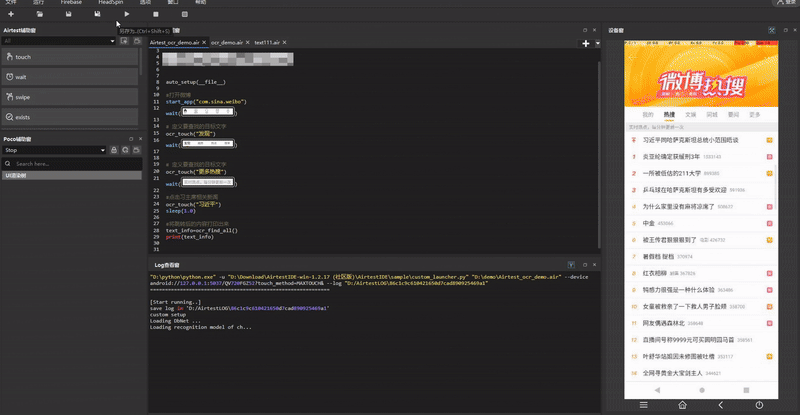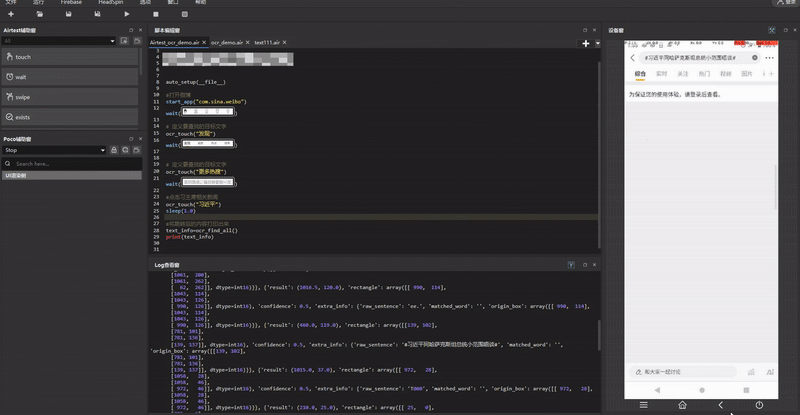
我们 Airtest-ocr 的图片文字识别情况如下图:
与 PaddleOCR 相比,我们 Airtest-ocr 除了可以直接识别传入图片内容外,还可以动态识别所连接的设备画面。具体的动态识别情况如下(在本地python环境中已加入Airtest-ocr库):
五、小结
我们本期推文介绍了 PaddleOCR 的文字识别能力,以及如何与 Airtest 协作,实现在脚本中可以 ocr 文字识别并点击的操作。当然,我们这里只是简单的封装实现了一个识别文字并点击的操作,还有更多的日常操作可以通过自己的需求去进行封装实现。或者有需要的同学,也可以联系我们,购买我们 Airtest 私有云,就可以直接调用 Airtest-ocr 的操作接口~
如果在测试的过程中,遇到了问题,或者有任何想要深入了解的知识点,欢迎在官方交流群(526033840)里告诉我们或者提交issue,也欢迎大家投稿其他不同的使用小技巧。