作者:韩山杰
Databend Cloud 研发工程师
https://github.com/hantmac
![]()
Databend是一个开源、高性能、低成本易于扩展的新一代云数据仓库。bend-ingest-kafka 是一个专为 Databend 设计的实时数据导入工具,它允许用户从 Apache Kafka 直接将数据流导入到 Databend 中,实现数据的实时分析和处理。
为什么选择bend-ingest-kafka?
- 实时性: 能够实时地从 Kafka 中读取数据并导入到 Databend。
- 高吞吐量: 支持高并发的数据导入,满足大规模数据处理的需求。
- 易用性: 提供了简单直观的配置方式,便于用户快速上手。
- 灵活性: 可二次开发支持多种数据格式和自定义转换逻辑。
环境准备
在使用 bend-ingest-kafka 之前,需要确保以下环境已经搭建好:
- 一个运行中的 Databend 实例或者在 Databend Cloud 中创建一个 warehouse(推荐)。
- 一个配置好的 Apache Kafka 集群。
- 已经安装的 bend-ingest-kafka。
快速开始
Step 1: 安装 bend-ingest-kafka
可以从 Databend 的官方 GitHub 仓库 release 页面 下载对应 OS 架构的 bend-ingest-kafka 的可执行二进制文件,或者直接执行命令安装最新版本。
go install github.com/databendcloud/bend-ingest-kafka[@latest](https://my.oschina.net/u/4418429)
Step 2: 配置 bend-ingest-kafka
配置文件通常包括 Kafka 的连接以及配置信息、Databend 的连接信息以及数据转换的逻辑。以下是一个简单的配置示例:
{
"kafkaBootstrapServers": "localhost:9092",
"kafkaTopic": "ingest_test",
"KafkaConsumerGroup": "test",
"mockData": "",
"isJsonTransform": false,
"databendDSN": "https://cloudapp:password@tn3ftqihs--medium-p8at.gw.aws-us-east-2.default.databend.com:443",
"databendTable": "default.kfk_test",
"batchSize": 10,
"batchMaxInterval": 5,
"dataFormat": "json",
"workers": 1,
"copyPurge": false,
"copyForce": false,
"disableVariantCheck": true,
"minBytes": 1024,
"maxBytes": 1048576,
"maxWait": 10,
"useReplaceMode": false,
"userStage": "~"
}
具体的配置参数可以参考 Parameter References,这里对几个比较重要的参数展开解释。
- isJsonTransform: 默认为
true,将 Kafka Json 数据逐字段转换为 Databend 表数据。通过设置 isJsonTransform 为 true 来使用此模式。如果设置为 false 的话,系统将在 Databend 中自动创建一个 raw table, 列包括 (uuid, koffset, kpartition, raw_data, record_metadata, add_time),并将原始数据导入此表。其中 raw_data 为导入的 kafka Json 数据,record_metadata 包含了本条数据的 kafka 元信息 - topic, partition, offset, create_time, key,方便用户查询。
- useReplaceMode:
useReplaceMode 是一种去重模式,开启后如果表中已存在数据,新数据将替换旧数据。但 useReplaceMode 仅在 isJsonTransform 为 false 时支持,因为它需要在目标表中添加 koffset 和 kpartition 字段。在这种模式下,系统可以实现 exactly once 的同步语义,否则为 at-least-once 语义。
- userStage: 用户的自定义 external stage name。
Step 3: 启动数据导入
这里使用 raw-data 模式作演示。
Kafka 的 Json 数据示例为:
{"i64": 10,"u64": 30,"f64": 20,"s": "hao","s2": "hello","a16":[1],"a8":[2],"d": "2011-03-06","t": "2016-04-04 11:30:00"}
模拟 kafka 生产数据
可以使用下面的脚本快速生成 kafka json 数据:
from confluent_kafka import Producer
# 创建一个Producer实例
p = Producer({'bootstrap.servers': 'localhost:9092'})
for i in range(1000000):
json_data = '{"i64": 10,"u64": 30,"f64": 20,"s": "hao","s2": "hello","a16":[1],"a8":[2],"d": "2011-03-06","t": "2016-04-04 11:30:00"}'
p.produce('ingest_test', json_data)
print(i)
p.flush()
使用配置文件启动 bend-ingest-kafka
默认读取 ./config/conf.json 配置文件,开始将 Kafka 中的数据导入到 Databend。
./bend-ingest-kafka
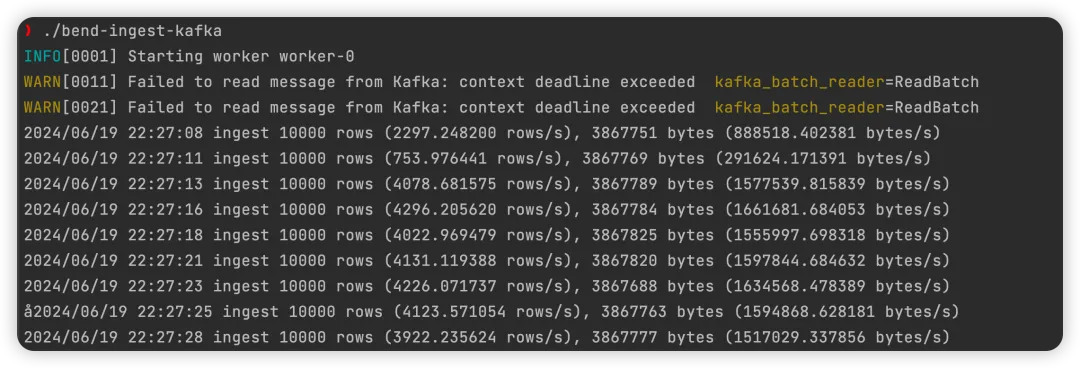
启动后可以看到 log 和 metrics:
![]()
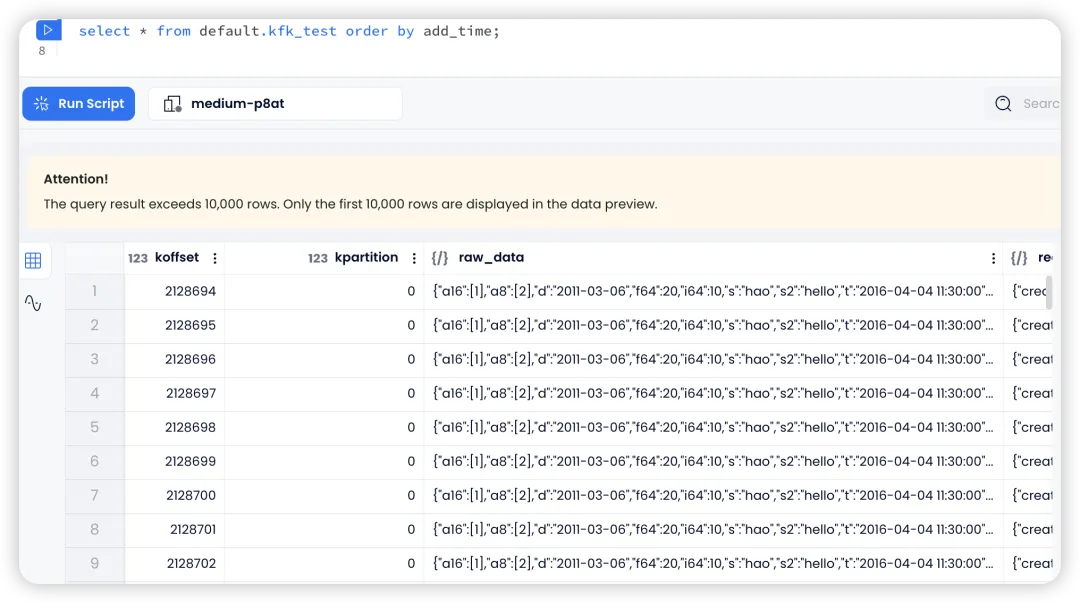
到 Databend 中可以查询到已经同步的数据:
![]()
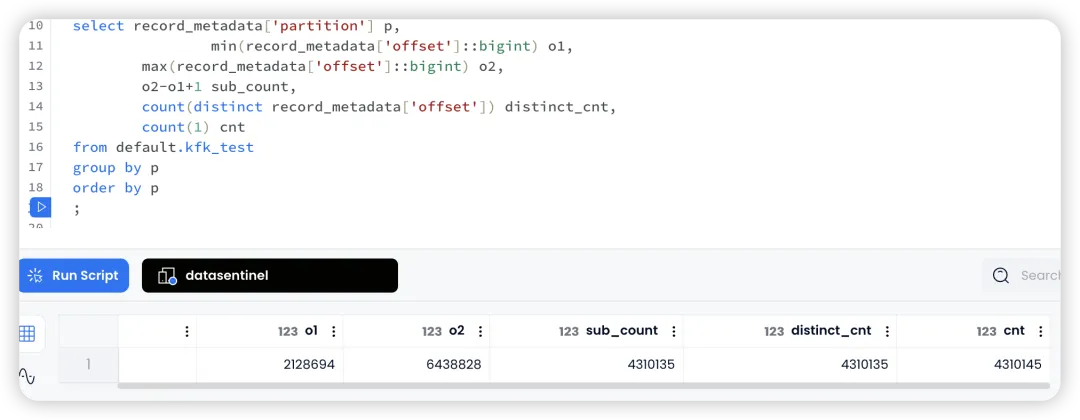
由于 raw_data 和 record_metadata 的字段格式都是 JSON ,所以可以很灵活地做一些数据分析:
select record_metadata['partition'] p,
min(record_metadata['offset']::bigint) o1,
max(record_metadata['offset']::bigint) o2,
o2-o1+1 sub_count,
count(distinct record_metadata['offset']) distinct_cnt,
count(1) cnt
from default.kfk_test
group by p
order by p;
![]()
高级特性
- 错误处理: 能够处理数据导入过程中的异常,并提供重试机制。
- 监控与日志: 提供详细的日志记录和监控指标,方便跟踪数据导入的状态。
结语
bend-ingest-kafka 作为一个强大的工具,为 Databend 用户提供了从 Kafka 实时导入数据的能力。通过本文的介绍,用户应该能够快速上手并利用这个工具来实现实时数据处理的需求。
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式数仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
👨💻 Databend Cloud:https://databend.cn
📖 Databend 文档:https://docs.databend.cn/
💻 Wechat:Databend
✨ GitHub:https://github.com/datafuselabs/databend