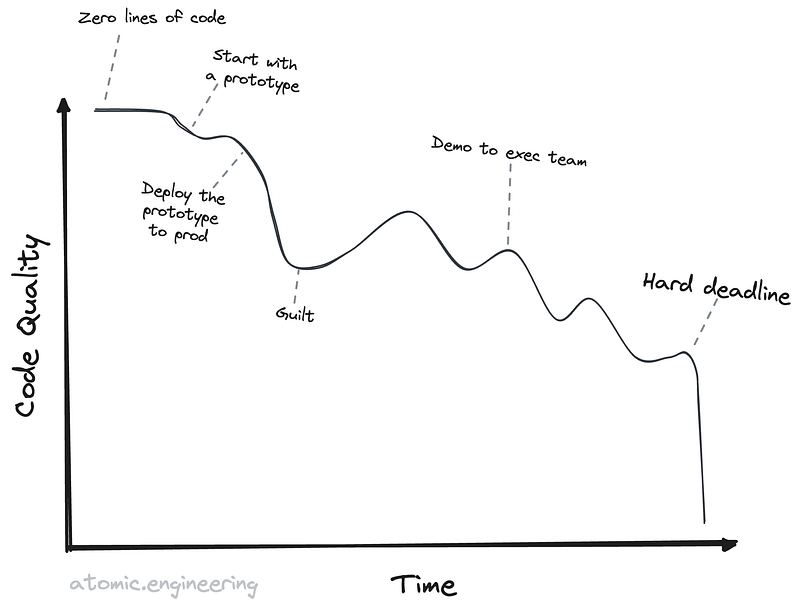
我共事过的每个团队都会讨论技术债。有些团队知道如何管理它,也有些团队因此崩溃瘫痪,甚至有一家公司因为技术债务没有得到解决而宣告失败。
什么是技术债务?
![]()
「债务」这个比喻非常恰当。最早提出「技术债务 Technical Debt」比喻的工程师 Ward Cunningham 对此做了详细的解释:
有了借来的钱,你可以比采用其他方式更快地做某件事情,但在还清这笔钱之前,你需要支付利息。我认为借钱是个好主意,我也认为赶快对外发布软件以获得经验是个好主意,但当然,你最终会回到这来,并且随着你愈加了解软件,你会通过重构程序来偿还那笔贷款,以此反映你所获得的经验。
本文将与你讨论技术债是如何产生的。但在那之前,我们先了解一些与技术债的产生原因和本质有关的常见误解。
误区一:技术债务 == 坏代码
到底什么是「坏代码」?
好的代码或许是整洁的代码,也可以概括为不会迫使你在未来做出特定决策的代码,它保留了选择的余地。而坏代码则不留余地,还会强加上一些原本不存在的约束。
我几乎没见过由「糟糕的开发者」编写的「坏代码」,至少在生产项目中没有(这正是代码审查的作用)。我遇到的大多数「坏代码」都出自受到约束影响的优秀的开发者。
![]()
误区二:技术债是错误的
技术债务和金融债务一样不分对错好坏。在非理想状态下——即没有足够的「现金」来满足需要——它就是产品开发工具箱中的一个有效工具。
误区三:构建完成就万事大吉
最常见的软件开发的比喻是修建建筑。在建筑行业,工作是按顺序进行的:
- 建筑设计师设计建筑并绘制图纸;
- 工人们挖掘地基、修建上层建筑、铺设管线并进行室内装修;
- 业主和租户高兴地搬进来,如有任何问题,再找维修人员解决。
这是一个通俗易懂的比喻,但却和软件行业不怎么类似。
与建筑相比,软件更像是园艺——它比混凝土更有机。你根据最初的计划和各种条件在花园里种植许多花木。有些花木茁壮成长,另一些注定要成为堆肥。你可能会改变植株的相对位置,以有效利用光影、风雨的交互作用。过度生长的植株会被分栽或修剪,颜色不协调的会被移栽到从美学上看更怡人的地方。你拔除野草,并给需要额外照料的植株施肥。你不断关注花园的兴旺,并按照需要(对土壤、植株、布局)做出调整。——《程序员修炼之道》
在(错误的)建筑比喻中,大部分成本是预先产生的。维护成本要么是名义上的,要么被视作偶发事件而忽略不计。
在园艺的比喻中,构建功能是漫长工作中的一个步骤(就像种植作物)。花园越大,所需的维护就越多。这是在重新种植以改变布局(重构),或扩大花园并种植新作物(添加新功能——这也需要维护)之外的工作。
90% 的软件成本均与维护有关——我很多年前就知晓这个数据,但每每想到还是觉得难以置信。
技术债是怎么产生的?
那么,技术债究竟从何而来?它可以避免吗?
技术债务的另一种理解可能是,项目当前所处的状态与「假设利用积累的知识重新开始而现在应处的状态」之间的差值。
技术债有两个来源:
![]()
(图:技术债务象限)
理想情况下,你会在充分了解情况且不向约束条件妥协的前提下做出决策。但现实可能是,你在没有全盘了解信息和背景时就启动了项目,还要根据时间限制(如利益相关者给的截止日期)或成本限制等约束做出权衡。
如何避免技术债是一门学问,而对「技术债可否避免」这一问题,我的回答是:
“可以避免,但技术债是一种工具,不是敌人。”
如何量化技术债?
「现在有多少技术债?」这么抽象的概念真的能被量化吗?
真的很难,或者说你无法可靠地跟踪技术债。如果向软件工程师了解如何实现某个功能或修复产品的某个部分,他们可能会提供一个估算结果,并将需要偿还的技术债务涵盖在内,但你仍然无法追踪它。
Chelsea Troy 提出了一个与技术债务高度相关的可量化指标:维护负载(maintenance load) 。
维护负载描述了开发团队花费多少精力来保持现有功能同以前一样运行。—— Chelsea Troy
维护负载是有关项目年限和构建实践的函数,其衡量单位是持续付出维护精力的开发者数量(ongoing developer effort)。
需要说明的是,维护负载 != 技术债务。
但它依然是一个非常不错的技术债务指标。如果需要更多的工程师来防止系统/项目崩溃,那么很可能意味着你有很多技术债。如果仅靠十几个人就能建立一家价值 10 亿美元的公司,那么他们大概率很好地控制住了技术债。
(作者 Jacob Bennett,内容经 LigaAI 翻译整理。)
了解更多技术干货、研发管理实践等分享,请关注 LigaAI。
邀您体验 LigaAI-智能研发协作平台,开启 AI 驱动的智能研发协作!