原文 From Zero to 50 Million Uploads per Day: Scaling Media at Canva
作为一款设计工具,Canva 吸引人的一个重要特色就是拥有数以亿计的照片和图形资源,支持用户上传个人素材。
Canva 于 2013 年推出,设立了一个包含大量照片和图形的资源库,并允许用户上传自己的素材以用于设计。从发布之日起,Canva 的用户群就迅速扩大:现在我们的月活用户已超过一亿,Canva 用户每天上传 5000 万个媒体素材。为了支持这种快速增长,同时让用户能够全天二十四小时使用 Canva,我们必须不断改进 Canva 的媒体存储方式。
Canva 的微服务和媒体服务
我们采用微服务架构来构建 Canva,大多数服务面向资源,管理 Canva 内部不同资源的操作,例如用户、文档、文件夹和媒体。服务提供公开的 API,具有独立的持久性,并且每个服务都由一个小型工程师团队负责。
![file]()
媒体服务的简化架构概述
Canva 的媒体服务管理媒体资源的操作并封装媒体资源的状态。对于每个媒体,服务都会存储:
- 资源的唯一标识 ID。
- 它的所属用户。
- 是否属于 Canva 媒体库。
- 外部资源信息。
- 状态(激活、已销毁或待删除)。
- 有关其内容的大量元数据,包括标题、创作者、关键词和颜色信息。
- 它的媒体文件及其存储位置。
媒体服务的读取次数多于写入次数,而且大多数媒体在创建后很少被修改。大多数媒体读取的都是最近创建的媒体,但官方图片库中的媒体除外。
MySQL 在 Canva:成长的烦恼
在 Canva 发展史的大部分时间里,大多数面向资源的微服务都是围绕托管在 AWS RDS 上的 MySQL,除了最繁忙的服务外,这已经足够了。最初,我们通过使用大实例对数据库进行纵向扩展,后来又进行了横向扩展,引入了最终一致性的只读副本,由 MySQL 读取副本提供支持的某些服务。
当对我们最大的媒体表进行 schema 变更操作开始需要耗时数天,问题开始显现。然后,MySQL 的在线 DDL 操作导致性能严重下降,以至于我们无法在为用户流量提供服务的同时执行这些操作。
幸运的是,就在这个时候,gh-ost项目开始流行起来,使我们能够在不影响用户的情况下安全地执行在线 schema 变更。然而,很快就出现了更多问题,包括:
- MySQL 5.6 复制速度的硬限制使得我们可读副本的写入速度达到了上限。
- 即使使用 gh-ost,schema 变更最终也需要长达六周的时间,这阻碍了功能的发布。
- 当时,我们已经接近 RDS MySQL EBS 卷大小(16TB)的极限。
- 我们注意到,EBS 卷大小的每次增加都会导致 I/O 延迟的小幅增加,这极大地影响了用户请求的长尾延迟。
- 为我们的正常生产环境流量提供服务需要一个热缓冲池,因此,如果不接受一定的停机时间,就无法进行实例重启和版本升级。
- 由于我们使用 ext3 文件系统通过快照创建了 RDS 实例,因此 MySQL 表文件的容量限制在 2TB。
调研替代方案,缩小差距
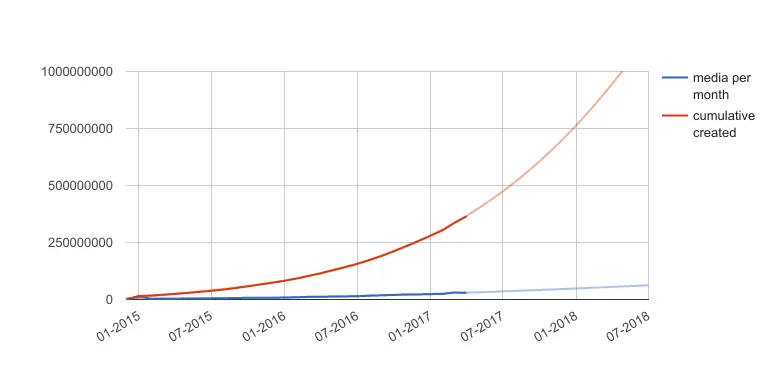
![file]()
自 2015 年 1 月以来每月媒体增长情况和累计创建媒体数
2017 年年中,随着 Canva 媒体数量接近 10 亿,并呈指数级增长,我们开始调研迁移路径,并强烈倾向于采用渐进式方法,使我们能够继续扩大规模,而不是将所有赌注押在单一未经验证的技术选择上。
在这一点上,我们采取了多项措施来延长现有 MySQL 解决方案的使用寿命,其中包括:
- 将媒体内容元数据(schema 中最常修改的部分)迁移到 JSON 列中,其 schema 由媒体服务管理。
- 对一些表 de-normalize,以减少锁争用和连接
- 删除重复内容(例如,s3 存储桶名称)或将其改为更短的形式。
- 删除了外键约束。
- 改变媒体导入方式,减少元数据更新次数。
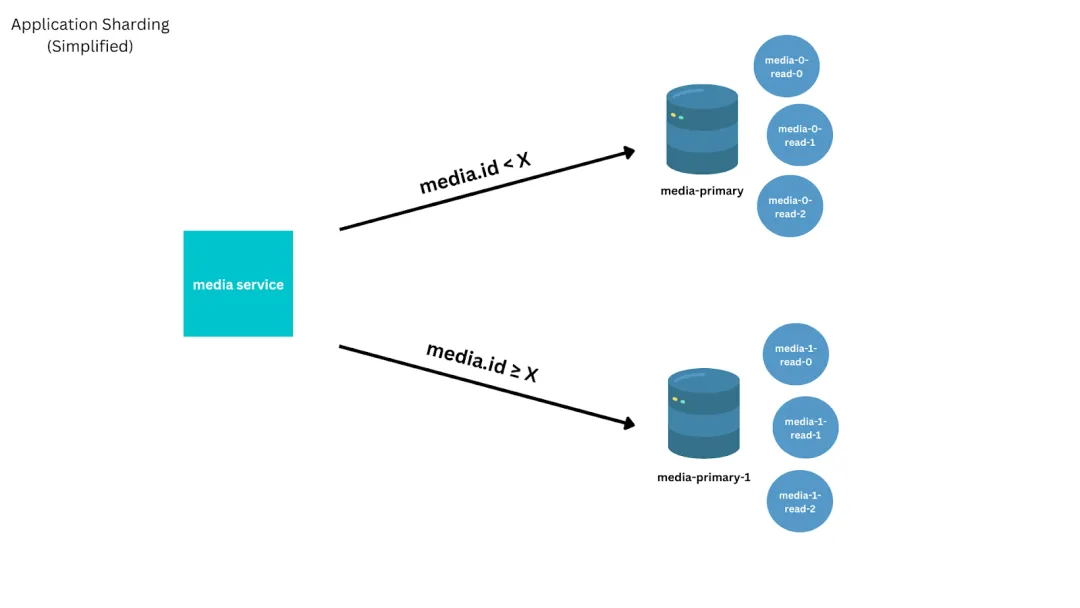
在 MySQL 解决方案的生命周期即将结束时,为了避开 2TB ext3 表文件大小限制、避免复制吞吐量上限,并为用户提高性能,我们实施了一个简单的分片解决方案。我们针对最常见的请求(加载设计时使用的 ID 查找)优化了解决方案,但对于不太常见的请求(如列出用户拥有的所有媒体),则通过低效的分散查询来收集。
![file]()
应用程序分片简化图
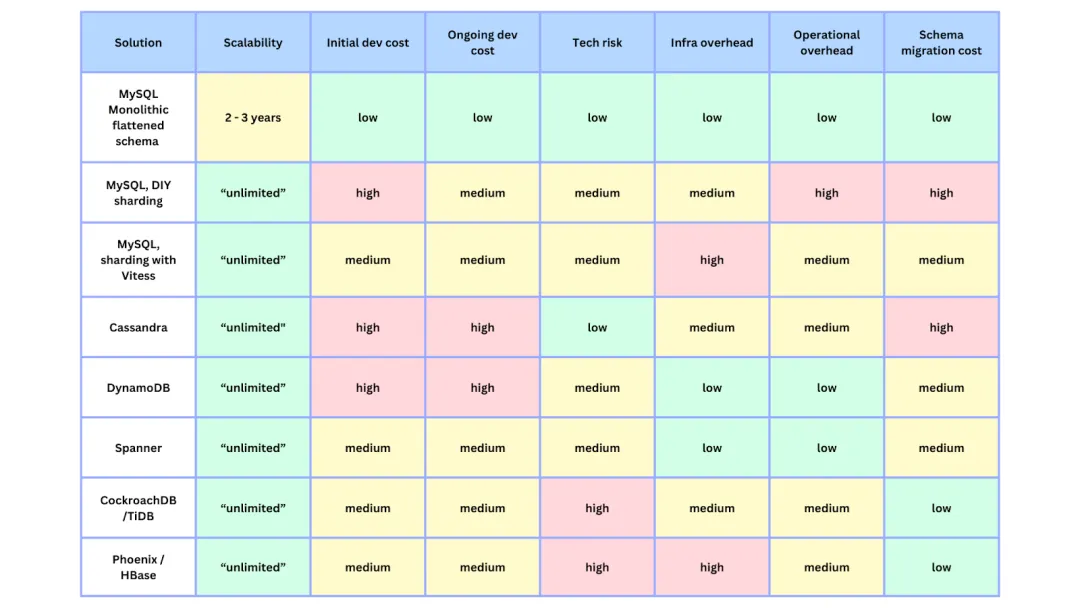
与此同时,我们还对不同的长期解决方案进行了调研和原型设计。由于时间紧迫,我们更倾向于托管的解决方案,Canva 之前有使用 DynamoDB 服务(不太复杂)的经验,而且我们已经能够对其进行原型设计,因此选择了 DynamoDB 作为暂定的目标。然而,我们还需要验证它在实际工作负荷的运行情况。此外,我们还需要一个迁移策略,能够在不影响用户的情况下进行迁移,并在零停机时间内完成切换。下表是我们在这一过程中的早期想法。
![file]()
各种数据库解决方案的比较
实时迁移
在设计迁移流程时,我们需要将所有旧的、新创建的和更新的媒体迁移到 DynamoDB。但也希望尽快减轻 MySQL 集群的负载。我们考虑了多个把数据从 MySQL 复制到 DynamoDB 的方案,包括:
- 在处理创建或更新请求时同时写入到两个数据存储系统。
- 构建并重放所有创建或更新操作的有序日志。
- AWS DMS。
我们决定采用这样一种方法:
- 让我们能够完全控制将数据映射到 DynamoDB 的方法。
- 允许我们逐步进行实时迁移。
- 通过首先迁移最近创建、更新和最近读取的媒体,尽早减轻 MySQL 集群的负载。
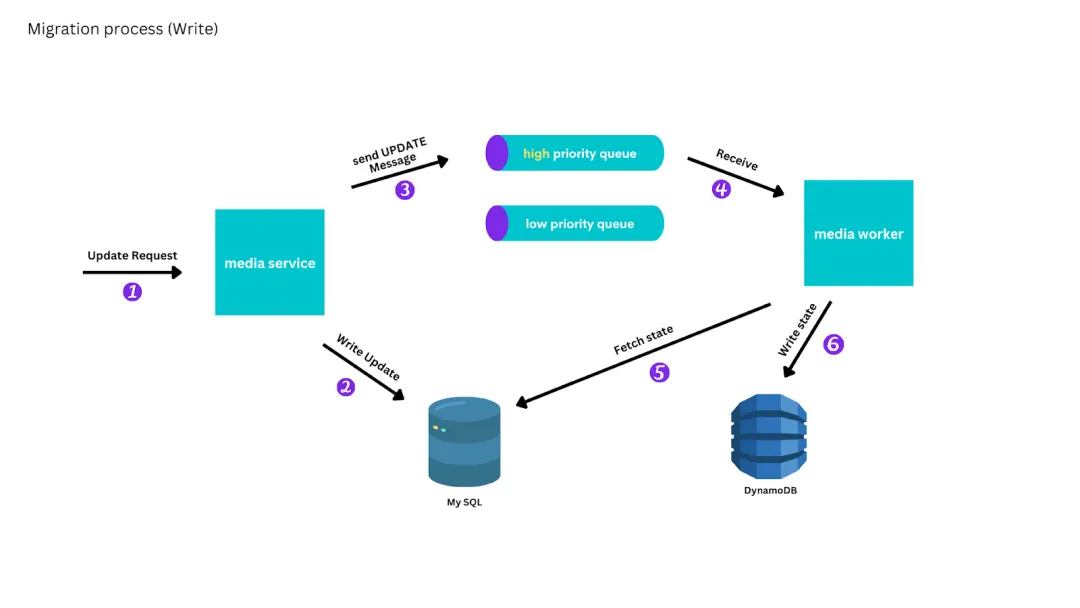
我们避免了生成有序日志的困难,也避免了编写自定义 MySQL binlog 解析器的困难,通过向 AWS SQS 队列发送消息来标记特定媒体的创建、更新或读取状态,这些消息不包括更新内容。工作实例会处理这些消息,从 MySQL 主库中读取当前状态,并在必要时更新 DynamoDB。这样,消息可以任意重新排序或重试,消息处理也可以暂停或减慢。
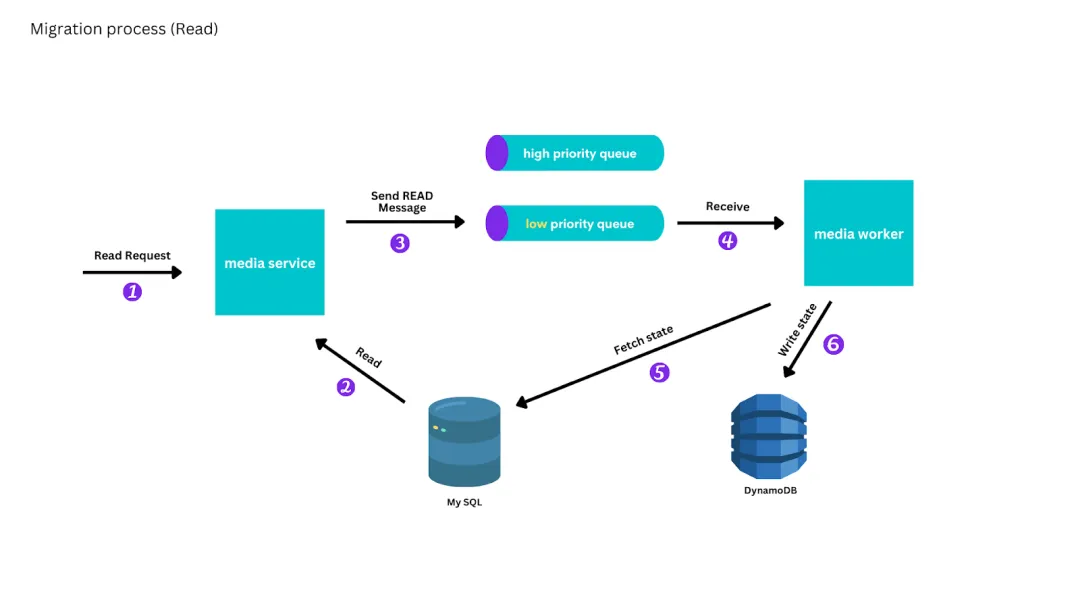
为了最终能从 DynamoDB 提供一致的读取服务,我们将写入的复制优先于读取:创建和更新消息放在高优先级队列中,读取消息放在低优先级队列中。工作实例从高优先级队列中读取,直到队列耗尽,然后再从低优先级队列中读取。
![file]()
迁移过程中的写入
![file]()
迁移过程中的读取
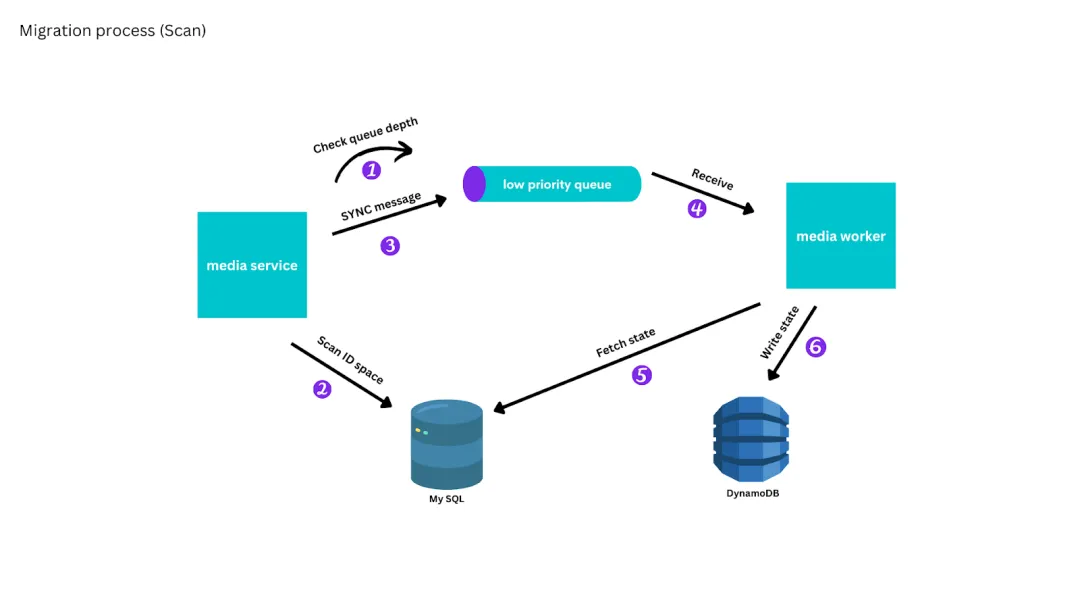
为了迁移剩余的媒体,我们实施了一个扫描流程,该流程会根据媒体的访问模式,从最近创建的媒体开始,扫描所有媒体,然后在低优先级队列中放置一条消息,将媒体复制到 DynamoDB。我们使用了反压机制 (backpressure),只有当低优先级队列大致为空时,同步进程才会向前推进。
![file]()
在迁移过程中进行扫描
在生产中进行测试
在开始完全从 DynamoDB 提供最终一致性读取之前,我们实施了双重读取和比较流程来测试我们的复制流程,该流程将 MySQL 的结果与新 DynamoDB 媒体服务实现进行了比较。在解决了复制流程中发现的问题后,我们开始从 DynamoDB 提供个别媒体的最终一致读取,对于尚未复制完成的少数媒体,则暂时回退到 MySQL。
由于我们是逐个复制媒体,因此在所有媒体复制到 DynamoDB 之前,无法提供不通过 ID 识别媒体的读取请求,例如查找用户拥有的所有媒体。扫描过程完成后,我们采用相同的方法从两个数据存储系统中读取数据,直到从 DynamoDB 提供所有最终一致的读取数据。
零停机时间切换和快速回滚策略
将所有写入切换到 DynamoDB 是整个过程中风险最大的部分。这需要运行新的服务代码来处理创建和更新请求,其中包括使用事务性写入和条件写入,以保证与之前的实施具有相同的合约。为了降低风险,我们采取了以下措施:
- 把针对媒体更新请求的集成测试迁移到了同时支持在 DynamoDB 上迁移过的媒体和直接在 DynamoDB 上创建的媒体。
- 将其他的集成测试迁移到了基于 DynamoDB 服务的实施中,并与 MySQL 的测试同时进行。
- 在本地开发环境中测试新实现。
- 使用端到端测试套件测试新实施。
- 编写切换运行手册,使用我们的标记系统,以便在需要时在几秒钟内将读取切换回 MySQL。
- 在我们通过开发和预发环境推出变更时,对运行手册进行演练。
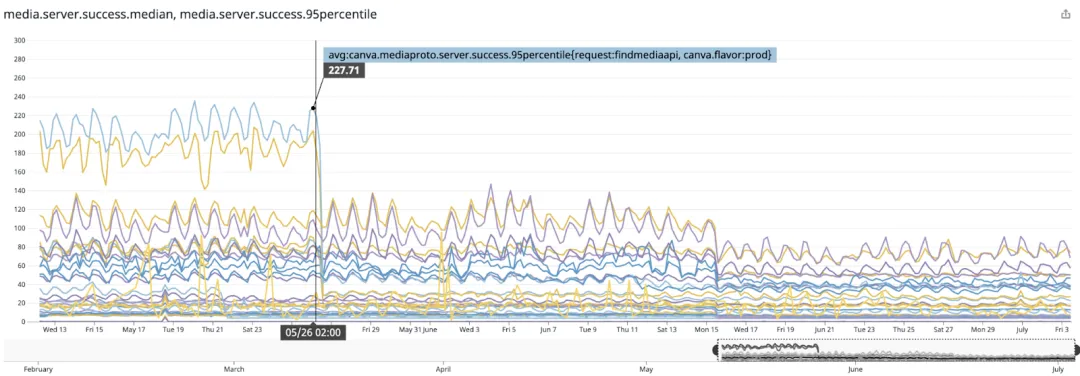
如下图所示,我们在生产中进行了无缝切换,没有出现停机或错误,媒体服务延迟也得到了显著改善。
![file]()
媒体服务延迟,显示迁移期间延迟的中位数和 95 百分位数
经验教训
在迁移过程中,我们总结了以下经验教训:
- 偷懒。了解你的访问模式,如果可以,先迁移经常被访问到的数据。
- 实地操作。通过在生产环境中直接迁移,我们能够收集更多信息,及早发现并修复错误,同时也加深了对技术的使用和操作的理解。
- 在生产环境中测试。生产环境中的数据总是比测试环境中的数据更具启发性,所以在可能的情况下,应在生产环境中进行测试和检查。
DynamoDB 是正确的选择吗?
自迁移以来,Canva 的月活跃用户数量增长了两倍多,而 DynamoDB 表现极为稳定,随着我们的成长而自动扩展,成本也低于它所取代的 AWS RDS 集群。在迁移过程中,我们牺牲了一些便利性:schema 变更和回填现在需要编写并严格测试并行扫描迁移代码,我们失去了在 MySQL 副本上运行临时 SQL 查询的能力,不过我们现在通过 CDC 来满足我们数据仓库的这一需求。与其他许多使用 DynamoDB 的用户一样,我们需要复合全局二级索引来支持现有的访问模式,但令人惊讶的是,我们仍然需要通过将属性连接在一起来手动创建二级索引。值得庆幸的是,在 Canva 发展的现阶段,核心媒体元数据的结构相对稳定,新的访问模式很少出现。
如果我们今天面临同样的问题,我们会再次大力考虑成熟的托管 「NewSQL」产品,如 Spanner 或 CockroachDB。
当前,Canva 的媒体服务已经存储了超过用户上传的 250 亿个媒体,每天还有 5000 万个媒体素材上传。
💡 更多资讯,请关注 Bytebase 公号:Bytebase