![]()
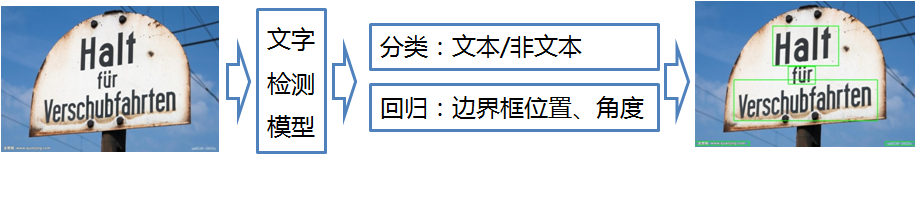
文字检测是AI的一项重要应用,在之前的文章中已经介绍过了几种基于深度学习的文字检测模型:CTPN(详见文章:大话文字检测经典模型CTPN)、SegLink(详见文章:大话文字检测经典模型SegLink)、EAST(详见文章:大话文字检测经典模型EAST),这些模型主要依赖于深度学习,可应用于自然场景中进行文字检测,其主要的实现步骤是判断是不是文本,并且给出文本框的位置和角度,如下图:
![]()
从上图可以看出,CTPN、SegLink、EAST等文字检测模型至少需要执行两个预测:通过分类判断是文本/非文本,通过回归确定边界框的位置和角度。回归的耗时比分类要多得多,而且准确率也是一个挑战。那么有没有一种方法是只需要利用“分类”,就能实现对文本/非文本的判断,并同时给出文本框的位置和角度呢?
答案是“有的”,这就是今天要介绍的另一个文字检测的经典模型:PixelLink(像素连接)
1、PixelLink整体框架
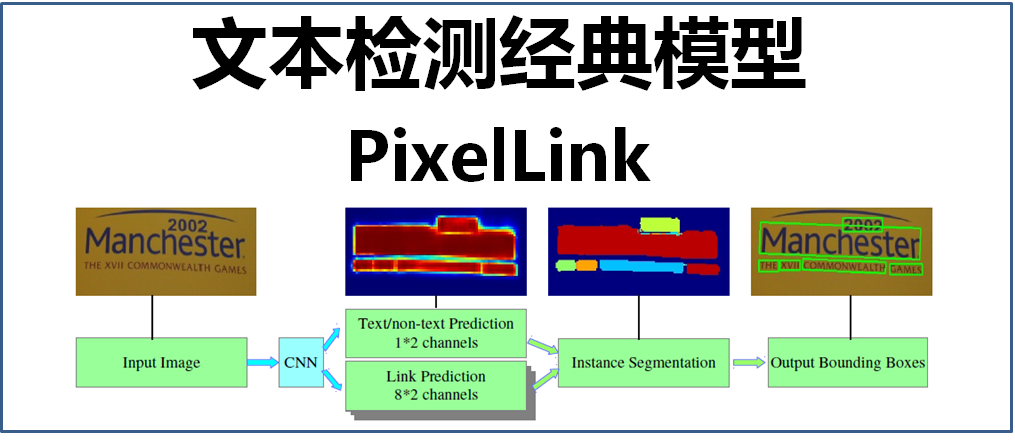
PixelLink的整体框架如下图:
![]()
从模型的名称PixelLink(像素连接)可以看出,该模型主要有两个关键部分:Pixel(像素)、Link(连接)。
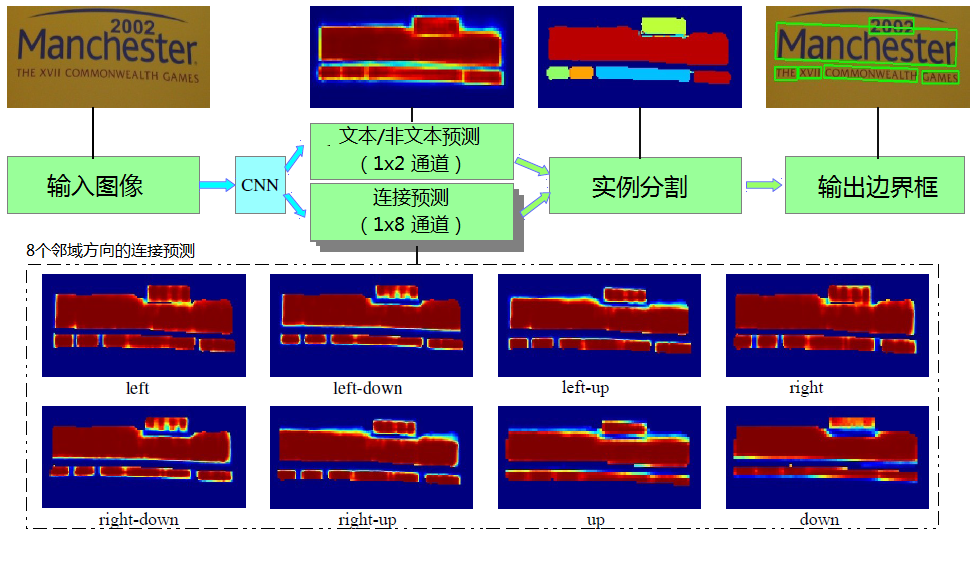
PixelLink主要是基于CNN网络,做某个像素(pixel)的文本/非文本的分类预测,以及该像素的8个邻域方向是否存在连接(link)的分类预测(即上图中虚线框内的八个热图,代表八个方向的连接预测)。然后基于OpenCV的minAreaRect(最小外接矩形)这种基于连通域的操作,获取不同大小的文本连通域,再进行噪声滤除操作,最后通过“并查集”(disjoint-set data structure)并出最终的文本边界框。
2、PixelLink网络结构
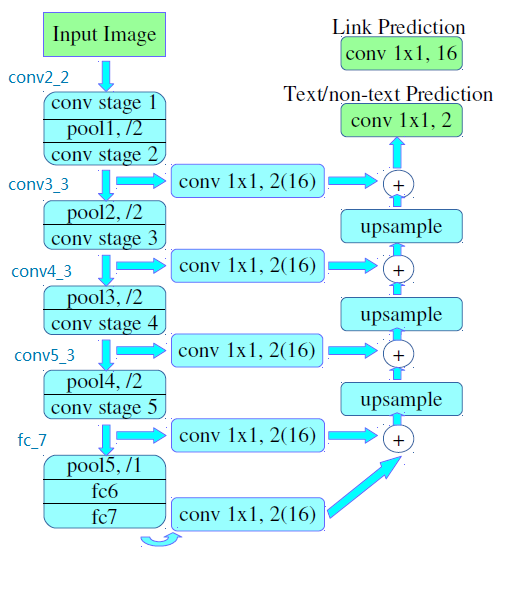
PixelLink的网络结构如下图所示:
![]()
PixelLink网络结构的骨干(backbone)采用VGG16作为特征提取器,将最后的全连接层fc6、fc7替换为卷积层,特征融合和像素预测的方式基于FPN思想(feature pyramid network,金字塔特征网络),即卷积层的尺寸依次减半,但卷积核的数量依次增倍,这种思想跟EAST模型的网络结构很像(详见文章:大话文字检测经典模型EAST)。
该模型结构有两个独立的头,一个用于文本/非文本预测(Text/non-text Prediction),另一个用于连接预测(Link Prediction),这两者都使用了Softmax,输出1x2=2通道(文本/非文本的分类)和8x2=16通道(8个邻域方向是否有连接的分类)。
在论文中作者给出了两种网络结构:PixelLink+VGG16 2s和PixelLink+VGG16 4s 。其中conv2_2的feature map(特征图)大小为原图1/2,而conv3_3的feature map(特征图)大小为原图1/4,如果最后的输出部分是从conv2_2中汇聚出来,则为PixelLink+VGG16 2s,如果是从conv3_3中汇聚出来,则为PixelLink+VGG16 4s。
3、PixelLink实现过程
(1)Pixel定义
Pixel(像素)分为正像素(positive)、负像素(negative)。所有落在文本区域内的像素标记为正像素(positive),文本区域以外的像素标记为负像素(negative),多个文本交叠区域也标记为负像素(negative)。
(2)Link定义
Link是由两个Pixel双向决定的,对于一个给定的像素以及其临近的八个像素点,如果:
两个像素都是正像素(positive),则它们之间的Link为正连接(positive)
如果一个像素是正像素,另一个是负像素,则它们之间的Link也为正连接(positive)
如果两个像素都是负像素,则它们之间的Link为负连接(negative)
(3)实例分割
对于Pixel(像素)、Link(连接)的预测结果,通过设定两个不同的阈值得到pixel positive集合和link positive集合(如超过指定阈值,则判为positive,否则为negative),使用正连接将正像素分组在一起,产生CCs(conected compoents,连通域)集合,集合中的每个元素代表的就是文本实例,每个CC就表示检测到的文本实例,这就实现了文本的实例分割,如下图:
![]()
(4)提取文本框
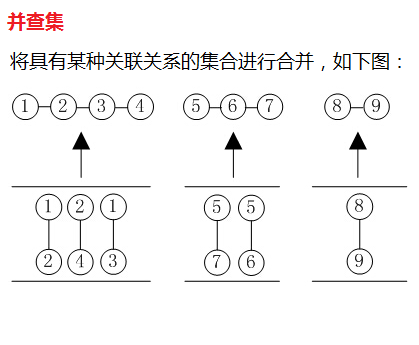
通过对CC(连通域)集合使用OpenCV的连通域方法minAreaRect获得最终的连通域,此时每个连通域都有自己的最小外接矩形,最后使用disjoint-set(并查集)方法形成最终的文本框,并查集主要用于将具有某种关联关系的集合进行合并的操作方法,如下图对集合的合并处理:
![]()
从这一步可以看出,文本边界框是直接从实例分割获得的,并不是通过位置回归获得的,这是跟其它检测方法的区别。另外,对文本的方向没有限制,也即可实现多角度的检测。
(5)去除噪声
由于使用基于连通域的方法进行文本像素汇聚,该方法对噪声比较敏感,最终会产生一些比较小的错误连通域,因此,通过对长度、宽度、面积、长宽比等信息,根据一定的阈值进行去除处理。具体方法是,选择训练数据集中排在99%位的作为阈值,例如在IC15数据集中99%的文本实例短边≥10像素,99%的文本域面积≥300像素,因此,将短边小于10像素或面积小于300像素的当作错误连通域进行去除。
4、PixelLink检测效果
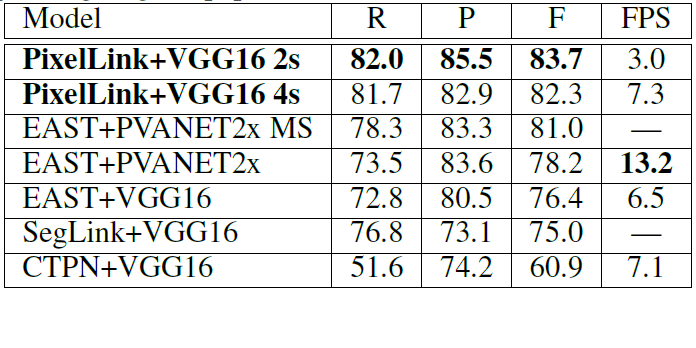
基于IC15数据集的检测效果,如下表所示:
![]()
可以看出,PixelLink在召回率(R)、准确率(P)、F分值(F)都要比EAST、SegLink、CTPN等方法的效果要好
PixelLink的检测效果,如下图所示,支持多角度的文本检测:
![]()
5、总结
(1)PixelLink采用纯分割的思路,完全没有利用目标检测的方法,放弃了采用边界框回归的方法,而是进行实例分割,再直接生成边界框。PixelLink全部转化为分类任务,这样做的优势是训练更容易学习,训练速度更快,效果更好。
(2)PixelLink方法,只需对feature map(特征图)上的像素以及它相邻的像素进行预测,即每个神经元只负责检测自己及其邻域内的状态,这就不需要大的感受野就能把这些信息学到,对感受野的要求少,因此也就更加容易学习,减少迭代次数。但也导致不能检测字与字之间相隔太远的文本(因为太远了Link不到)。
(3)不需要采用预训练模型,直接使用通过xavier(一种很有效的神经网络初始化方法)随机初始化的VGG网络,在训练过程中也不需要太多的数据,迭代次数也比较少。
(4)该方法适合于进行端到端的文字检测,直接输入图片,然后得到检测结果。
欢迎关注本人的微信公众号“大数据与人工智能Lab”(BigdataAILab),获取更多信息
![]()
推荐相关阅读
1、AI 实战系列
2、大话深度学习系列
3、图解 AI 系列
4、AI 杂谈
5、大数据超详细系列