作者:潘伟龙(豁朗)
背景
日志服务 SLS 是云原生观测与分析平台,为 Log、Metric、Trace 等数据提供大规模、低成本、实时的平台化服务,基于日志服务的便捷的数据接入能力,可以将系统日志、业务日志等接入 SLS 进行存储、分析;阿里云 Flink 是阿里云基于 Apache Flink 构建的大数据分析平台,在实时数据分析、风控检测等场景应用广泛。阿里云 Flink 原生支持阿里云日志服务 SLS 的 Connector,用户可以在阿里云 Flink 平台将 SLS 作为源表或者结果表使用。
阿里云 Flink SLS Connector 对于结构化的日志非常直接,通过配置,SLS 的日志字段可以与 Flink SQL 的 Table 字段列一一映射;然后仍有大量的业务日志并非完全的结构化,例如会将所有日志内容写入一个字段中,需要正则提前、分隔符拆分等手段才可以提取出结构化的字段,基于这个场景,本文介绍一种使用 SLS SPL 配置 SLS Connector 完成数据结构化的方案,覆盖日志清洗与格式规整场景。
弱结构化日志处理的痛点
弱结构化日志现状与结构化处理需求的矛盾
日志数据往往是多种来源,多种格式,往往没有固定的 Schema,所以在数据处理前,需要先对数据进行清洗、格式规整,然后在进行数据分析;这类数据内容格式是不固定的,可能是 JSON 字符串、CSV 格式,甚至是不规则的 Java 堆栈日志。
Flink SQL 是一种兼容 SQL 语法的实时计算模型,可以基于 SQL 对结构化数据进行分析,但同时也要求源数据模式固定:字段名称、类型、数量是固定;这也是 SQL 计算模型的基础。
日志数据的弱结构化特点与 Flink SQL 结构化分析之间有着一道鸿沟,跨越这道鸿沟需要一个中间层来进行数据清洗、规整;这个中间层的方案有多种选择可以使用,下面会对不同的方案做简单对比,并提出一种新的基于 SLS SPL 的方案来轻量化完成解决数据清洗规整的工作。
弱结构化日志数据
下面是一条日志示例,日志格式较为复杂,既有 JSON 字符串,又有字符串与 JSON 混合的场景。其中:
- Payload 为 JSON 字符串,其中 schedule 字段的内容也是一段 JSON 结构。
- requestURL 为一段标准的 URL Path 路径。
- error 字段是前半部分包含 CouldNotExecuteQuery:字符串,后半部分是一段 JSON 结构。
- tag:path 包含日志文件的路径,其中 service_a 可能是业务名称。
- caller 中包含文件名与文件行数。
{
"Payload": "{\"lastNotified\": 1705030483, \"serverUri\": \"http://test.alert.com/alert-api/tasks\", \"jobID\": \"44d6ce47bb4995ef0c8052a9a30ed6d8\", \"alertName\": \"alert-12345678-123456\", \"project\": \"test-sls-project\", \"projectId\": 123, \"aliuid\": \"1234567890\", \"alertDisplayName\": \"\\u6d4b\\u8bd5\\u963f\\u91cc\\u4e91\\u544a\\u8b66\", \"checkJobUri\": \"http://test.alert.com/alert-api/task_check\", \"schedule\": {\"timeZone\": \"\", \"delay\": 0, \"runImmediately\": false, \"type\": \"FixedRate\", \"interval\": \"1m\"}, \"jobRunID\": \"bf86aa5e67a6891d-61016da98c79b-5071a6b\", \"firedNotNotified\": 25161}",
"TaskID": "bf86aa5e67a6891d-61016da98c79b-5071a6b-334f81a-5c38aaa1-9354-43ec-8369-4f41a7c23887",
"TaskType": "ALERT",
"__source__": "11.199.97.112",
"__tag__:__hostname__": "iabcde12345.cloud.abc121",
"__tag__:__path__": "/var/log/service_a.LOG",
"caller": "executor/pool.go:64",
"error": "CouldNotExecuteQuery : {\n \"httpCode\": 404,\n \"errorCode\": \"LogStoreNotExist\",\n \"errorMessage\": \"logstore k8s-event does not exist\",\n \"requestID\": \"65B7C10AB43D9895A8C3DB6A\"\n}",
"requestURL": "/apis/autoscaling/v2beta1/namespaces/python-etl/horizontalpodautoscalers/cn-shenzhen-56492-1234567890123?timeout=30s",
"ts": "2024-01-29 22:57:13"
}
结构化数据处理需求
对于这样的日志提取出更有价值的信息需要进行数据清洗,首先需要提取重要的字段,然后对这些字段进行数据分析;本篇关注重要字段的提取,分析仍然可以在 Flink 中进行。
假设提取字段具体需求如下:
- 提取 error 中的 httpCode、errorCode、errorMessage、requestID。
- 提取 tag:path 中的 service_a 作为 serviceName。
- 提取 caller 中的 pool.go 作为 fileName,64 作为 fileNo。
- 提取 Payload 中的 project;提取 Payload 下面的 schedule 中的 type 为 scheuleType。
- 重命名 source 为 serviceIP。
- 其余字段舍弃。
最终需要的字段列表如下,基于这样一个表格模型,我们可以便捷的使用 Flink SQL 进行数据分析。
![]()
解决方案
实现这样的数据清洗,有很多种方法,这里列举几种基于 SLS 与 Flink 的方案,不同方案之间没有绝对的优劣,需要根据不同的场景选择不同的方案。
数据加工方案: 在 SLS 控制台创建目标 Logstore,通过创建数据加工任务,完成对数据的清洗。
![]()
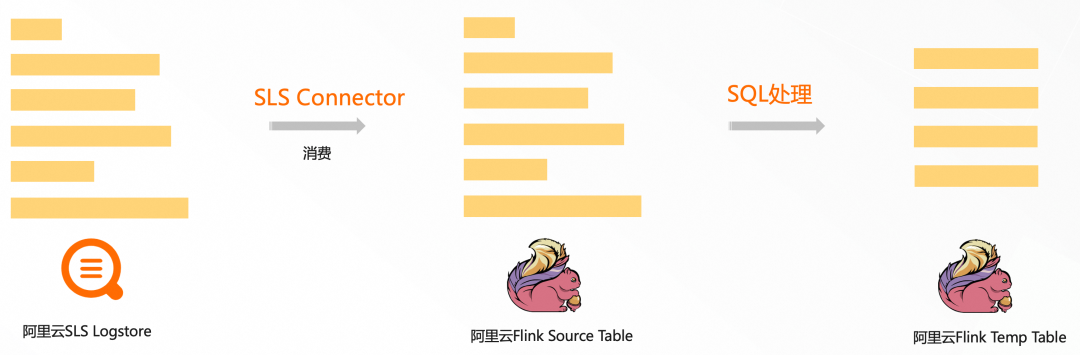
Flink 方案: 将 error 和 payload 指定为源表字段,通过 SQL 正则函数、JSON 函数对字段进行解析,解析后的字段写入临时表,然后对临时表进行分析。
![]()
SPL 方案: 在 Flink SLS Connector 中配置 SPL 语句,对数据进行清洗,Flink 中源表字段定义为清洗后的数据结构。
![]()
从上述三种方案的原理不难看出,在需要数据清洗的场景中,在 SLS Connector 中配置 SPL 是一种更轻量化的方案,具有轻量化、易维护、易扩展的特点。
在日志数据弱结构化的场景中,SPL 方案既避免了方案一中创建临时中间 Logstore,也避免了方案二中在 Flink 中创建临时表,在离数据源更近的位置进行数据清洗,在计算平台关注业务逻辑,职责分离更加清晰。
如何在 Flink 中使用 SPL
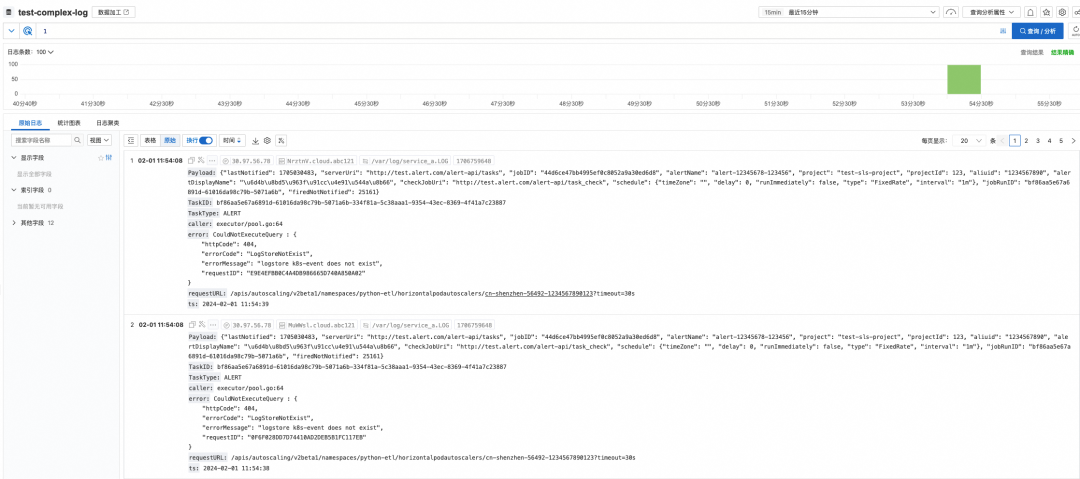
接下来以一段弱结构化日志为例,来介绍基于 SLS SPL 的能力来使用 Flink。为了便于演示,这里在 Flink 控制台配置 SLS 的源表,然后开启一个连续查询以观察效果。在实际使用过程中,仅需修改 SLS 源表配置,即可完成数据清洗与字段规整。
SLS 准备数据
- 开通 SLS,在 SLS 创建 Project,Logstore,并创建具有消费 Logstore 的权限的账号 AK/SK。
- 当前 Logstore 数据使用 SLS SDK 写入模拟数据,格式使用上述日志片段,其中包含 JSON、复杂字符串等弱结构化字段。
![]()
预览 SPL 效果
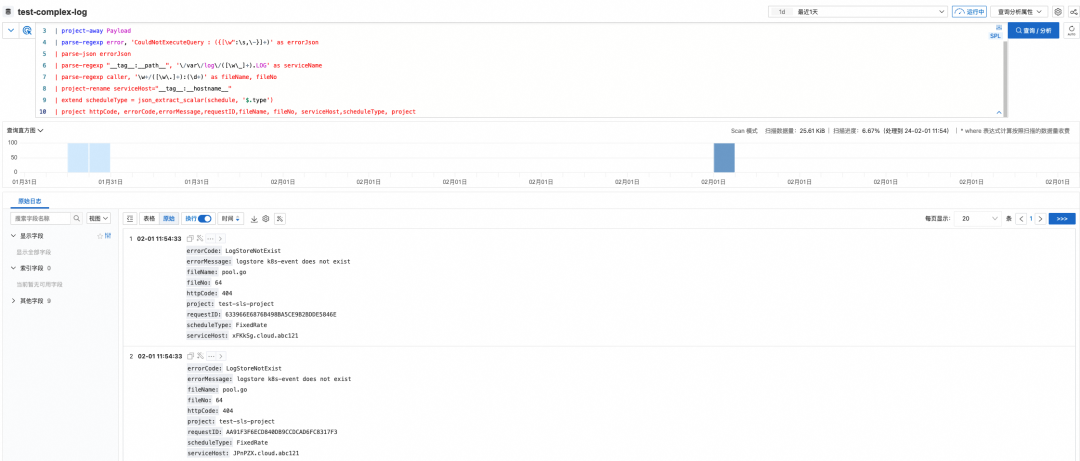
在 Logstore 可以可以开启扫描模式,SLS SPL 管道式语法使用丨分隔符分割不同的指令,每次输入一个指令可以即时查看结果,然后增加管道数,渐进式、探索式获取最终结果。
![]()
对上图中的 SPL 进行简单描述:
* | project Payload, error, "__tag__:__path__", "__tag__:__hostname__", caller
| parse-json Payload
| project-away Payload
| parse-regexp error, 'CouldNotExecuteQuery : ({[\w":\s,\-}]+)' as errorJson
| parse-json errorJson
| parse-regexp "__tag__:__path__", '\/var\/log\/([\w\_]+).LOG' as serviceName
| parse-regexp caller, '\w+/([\w\.]+):(\d+)' as fileName, fileNo
| project-rename serviceHost="__tag__:__hostname__"
| extend scheduleType = json_extract_scalar(schedule, '$.type')
| project httpCode, errorCode,errorMessage,requestID,fileName, fileNo, serviceHost,scheduleType, project
- 1 行:project 指令:从原始结果中保留 Payload、error、tag:path、caller 字段,舍弃其他字段,这些字段用于后续解析。
- 2 行:parse-json 指令:将 Payload 字符串展开为 JSON,第一层字段出现在结果中,包括 lastNotified、serviceUri、jobID 等。
- 3 行:project-away 指令:去除原始 Payload 字段。
- 4 行:parse-regexp 指令:按照 error 字段中的内容,解析其中的部分 JSON 内容,置于 errorJson 字段。
- 5 行:parse-json 指令:展开 errorJson 字段,得到 httpCode、errorCode、errorMessage 等字段。
- 6 行:parse-regexp 指令:通过正则表达式解析出 tag:path 种的文件名,并命名为 serviceName。
- 7 行:parse-regexp 指令:通过正则表达式捕获组解析出 caller 种的文件名与行数,并置于 fileName、fileNo 字段。
- 8 行:project-rename 指令:将 tag:hostname 字段重命名为serviceHost。
- 9 行:extend 指令:使用 json_extract_scalar 函数,提取 schedule 中的 type 字段,并命名为 scheduleType。
- 10 行:project 指令:保留需要的字段列表,其中 project 字段来自于 Payload。
创建 SQL 作业
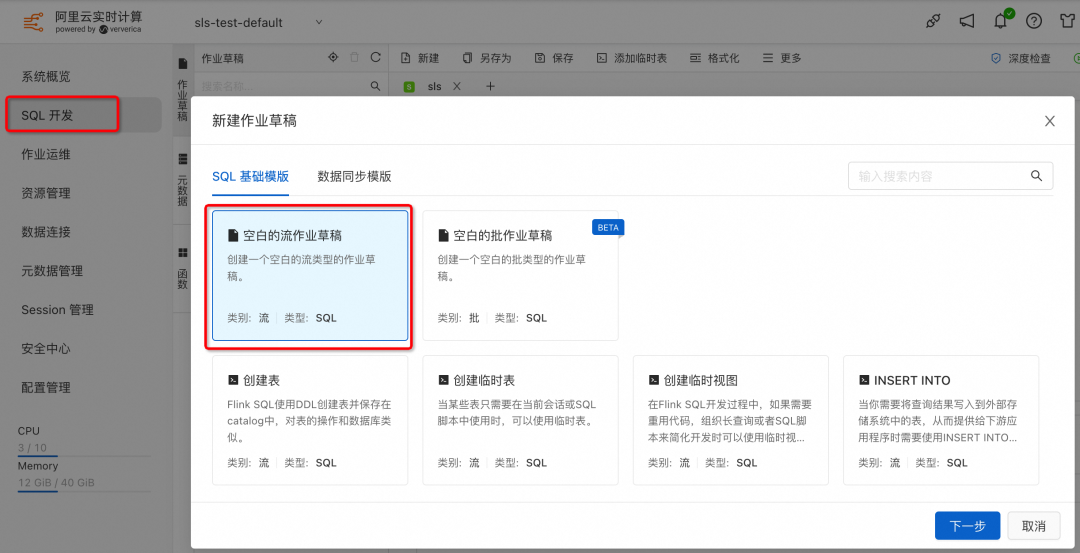
在阿里云 Flink 控制台创建一个空白的 SQL 的流作业草稿,点击下一步,进入作业编写。
![]()
在作业草稿中输入如下创建临时表的语句:
CREATE TEMPORARY TABLE sls_input_complex (
errorCode STRING,
errorMessage STRING,
fileName STRING,
fileNo STRING,
httpCode STRING,
requestID STRING,
scheduleType STRING,
serviceHost STRING,
project STRING,
proctime as PROCTIME()
) WITH (
'connector' = 'sls',
'endpoint' ='cn-beijing-intranet.log.aliyuncs.com',
'accessId' = '${ak}',
'accessKey' = '${sk}',
'starttime' = '2024-02-01 10:30:00',
'project' ='${project}',
'logstore' ='${logtore}',
'query' = '* | project Payload, error, "__tag__:__path__", "__tag__:__hostname__", caller | parse-json Payload | project-away Payload | parse-regexp error, ''CouldNotExecuteQuery : ({[\w":\s,\-}]+)'' as errorJson | parse-json errorJson | parse-regexp "__tag__:__path__", ''\/var\/log\/([\w\_]+).LOG'' as serviceName | parse-regexp caller, ''\w+/([\w\.]+):(\d+)'' as fileName, fileNo | project-rename serviceHost="__tag__:__hostname__" | extend scheduleType = json_extract_scalar(schedule, ''$.type'') | project httpCode, errorCode,errorMessage,requestID,fileName, fileNo, serviceHost,scheduleType,project'
);
- 其中 ${ak},${sk},${project},${logstore} 需要替换为有消费权限的 AK 账号。
- query 字段,替换为上述 SPL,注意在阿里云 Flink 控制台需要对单引号使用单引号转义,并且消除换行符。
- SPL 最终得到的字段列表与 TABLE 中字段对应。
连续查询及效果
在作业中输入分析语句,查看结果数据:
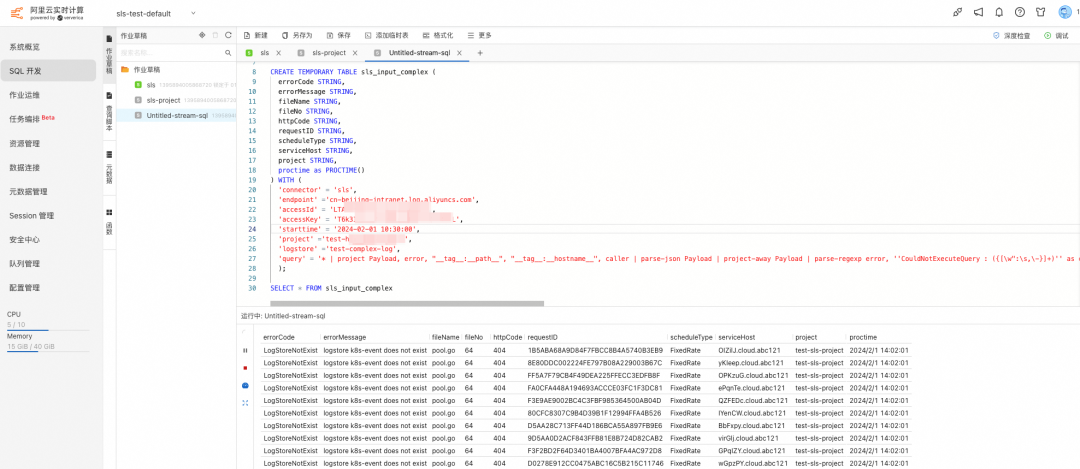
SELECT * FROM sls_input_complex
点击右上角调试按钮,进行调试,可以看到 TABLE 中每一列的值,对应 SPL 处理后的结果。
![]()
总结
为了适应弱结构化日志数据的需求,Flink SLS Connector 进行了升级,支持直接通过 Connector配置 SPL 的方式实现 SLS 数据源的清洗下推,特别是需要正则字段提取、JSON 字段提取、CSV 字段提取场景下,相较原数据加工方案和原 Flink SLS Connector 方案更轻量级,让数据清洗的职责更加清晰,在数据源端完成数据清洗工作,也可以减少数据的网络传输流量,使得到达 Flink 的数据已经是规整好的数据,可以更加专注在 Flink 中进行业务数据分析。
同时为了便于 SPL 验证测试,SLS 扫描查询也已支持使用 SPL 进行查询,可以实时看到 SPL 管道式语法执行结果。
参考链接:
[1] 日志服务概述
https://help.aliyun.com/zh/sls/product-overview/what-is-log-service
[2] SPL 概述
https://help.aliyun.com/zh/sls/user-guide/spl-overview
[3] 阿里云 Flink Connector SLS
https://help.aliyun.com/zh/flink/developer-reference/log-service-connector
[4] SLS 扫描查询
https://help.aliyun.com/zh/sls/user-guide/scan-based-query-overview
参与体验赢惊喜大会门票
通义灵码,是阿里云出品的一款基于通义大模型的智能编码辅助工具,提供行级/函数级实时续写、自然语言生成代码、单元测试生成、代码优化、注释生成、代码解释、研发智能问答、异常报错排查等能力,并针对阿里云的云服务使用场景调优,助力开发者高效、流畅的编码。
官网链接:https://tongyi.aliyun.com/lingma
本次ArchSummit 架构师峰会期间,通义灵码联合InfoQ 策划发起 AI编程体验活动,保存小程序卡片,微信扫码进入小程序,参与通义灵码体验抽奖活动,有机会赢全球架构师峰会专属免费门票(票价5440元)
![]()