上篇文章深入浅出JVM(十一)之如何判断对象“已死”已经深入浅出的解析JVM是如何评判对象不再使用,不再使用的对象将变成“垃圾”,等待回收
垃圾回收算法有多种,适用于不同的场景,不同的垃圾收集器使用不同的算法
本篇文章将围绕垃圾回收算法,深入浅出的解析垃圾回收分类以及各种垃圾回收算法
垃圾回收算法
垃圾回收分类
垃圾收集器有着多种GC方式,不同的GC方式有自己的特点,回收的堆内存部分也不同
堆内存分为新生代和老年代,新生代存储“年轻”的对象,老年代存储“老”或内存大的对象,对象年龄由经历多少次GC来判断
其中整堆收集时不仅会回收整个堆还会回收元空间(直接内存)
标记-清除算法
Mark-Sweep
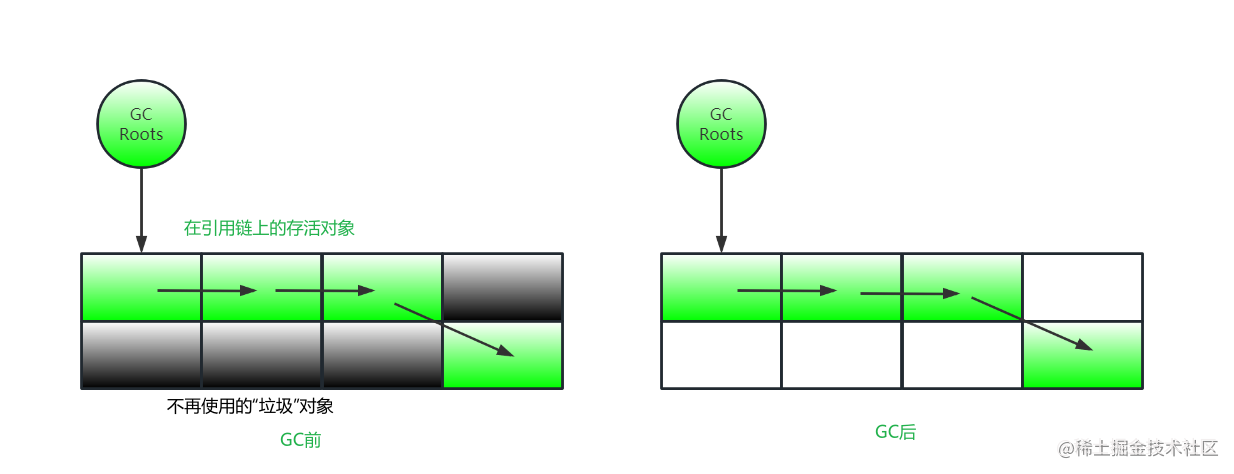
标记:从GCRoots开始遍历引用链,标记所有可达对象 (在对象头中标记)
清除:从堆内存开始线性遍历,发现某个对象没被标记时对它进行回收
![image-20221222171839962.png]()
标记-清除算法实现简单、不需要改变引用地址,但是需要两次遍历扫描效率不高,并且会出现内存碎片
注意:这里的清除并不是真正意义上的回收内存,只是更新空闲列表(标记这块内存地址为空闲,后续有新对象需要使用就覆盖)
复制算法
Copying
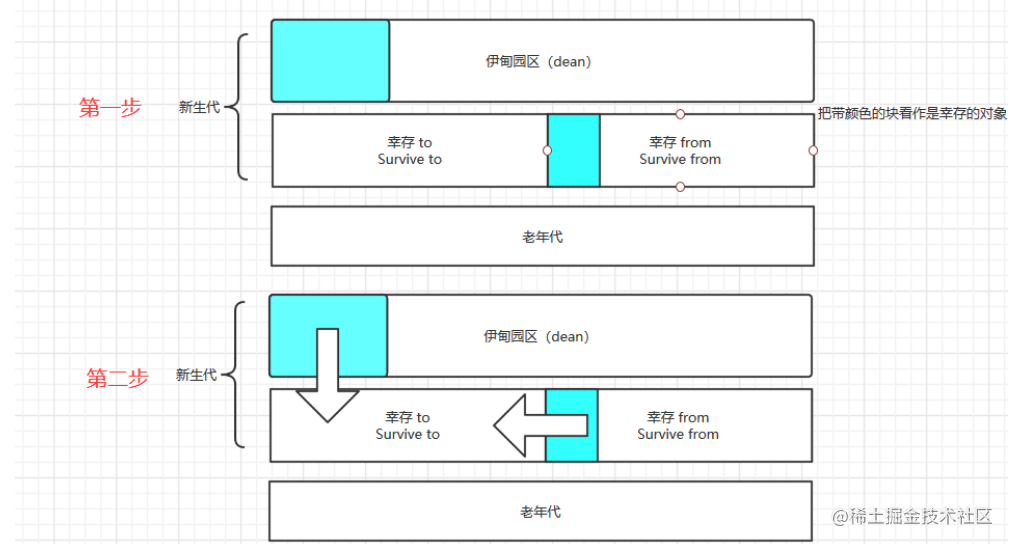
Survive区分为两块容量一样的Survive to区和Survive from区
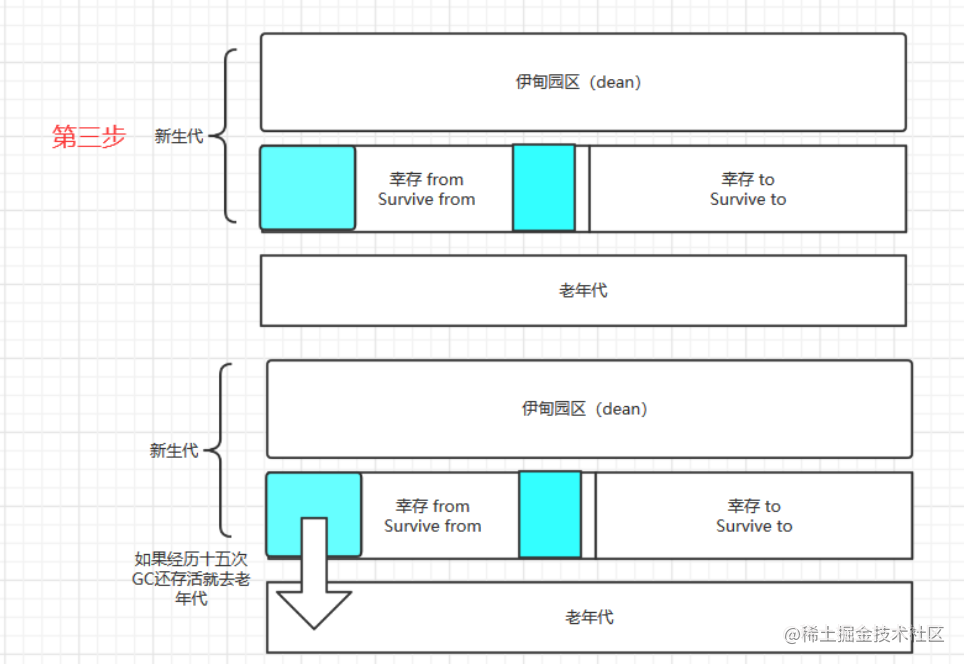
每次GC将Eden区和Survive from区存活的对象放入Survive to区,此时Survive to区改名为Survive from区,原来的Survive from区改名为Survive to区 保证Survive to区总是空闲的
如果Survive from区的对象经过一定次数的GC后(默认15次),把它放入老年代
流程图
注意:图中的dean为Eden区(写错)
![image-20201120164106097.png]()
![image-20201120164200591.png]()
注意:最终的survive from区存活对象占用的内存应该是(那两块蓝色)挨着一起的,图中为了标识字分开来了
复制算法不需要遍历,并且不会产生内存碎片,但是会浪费survive区一半的内存,移动对象时需要STW暂停用户线程,并且复制后会改变引用地址(hotspot使用直接指针访问,还要改变栈中reference执行新引用地址)
如果复制算法中对象存活率太高会导致十分消耗资源,因此一般只有新生代才使用复制算法
标记-整理算法
Mark-Compact
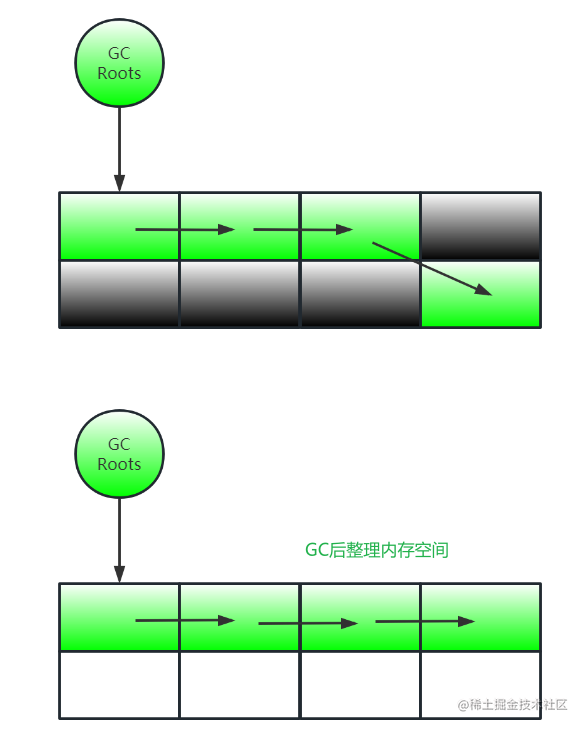
标记:从GCRoots开始遍历引用链,标记所有可达对象(在对象头中标记) (与标记-清除算法一致)
整理:让所有存活对象往内存空间一端移动,然后直接清理掉边界以外的所有内存
![image-20221222172409619.png]()
标记-整理算法不会出现内存碎片也不会浪费空间,但是效率低(比标记-清除还多了整理功能),移动对象导致STW和改变reference指向
如果不移动对象会产生内存碎片,内存碎片过多,将无法为大对象分配内存
还有种方法:多次标记-清除,等内存碎片多了再进行标记-整理
分代收集算法
|
标记清除mark-sweep |
复制copying |
标记整理mark-compact |
| 速度 |
中 |
快 |
慢 |
| GC后是否需要移动对象 |
不移动对象 |
移动对象 |
移动对象 |
| GC后是否存在内存碎片 |
存在内存碎片 |
不存在内存碎片 |
不存在内存碎片 |
需要移动对象 意味着 要改变改对象引用地址 也就是说要改变栈中reference指向改对象的引用地址,并且会发生STW停顿用户线程
当空间中存在大量内存碎片时,可能导致大对象无法存储
分代收集算法 : 对待不同生命周期的对象可以采用不同的回收算法(不同场景采用不同算法)
年轻代: 对象生命周期短、存活率低、回收频繁,采用复制算法,高效
老年代: 对象生命周期长、存活率高、回收没年轻代频繁,采用标记-清除 或混用 标记-整理
增量收集算法
mark-sweep、copying、mark-compact算法都存在STW,如果垃圾回收时间很长,会严重影响用户线程的响应
增量收集算法: 采用用户线程与垃圾收集线程交替执行
增量收集算法能够提高用户线程的响应时间,但存在GC、用户线程切换的开销,降低了吞吐量,GC成本变大
分区算法
堆空间越大,GC时间就会越长,用户线程响应就越慢
分区算法: 将堆空间划分为连续不同的区,根据要求的停顿时间合理回收n个区,而不是一下回收整个堆
每个区独立使用,独立回收,根据能承受的停顿时间控制一次回收多少个区
G1收集器以及两块低延迟收集器Shenandoah、ZGC就使用到这种分区算法
总结
本篇文章围绕垃圾回收算法,深入浅出解析垃圾回收分类、标记清除、复制、标记整理、分代收集、增量收集、分区算法等多种算法
从垃圾回收空间上划分可以分为Full GC回收整个堆加上元空间、Minor GC回收新生代、major GC回收老年代、mixed GC回收新生代加老年代
标记清除算法会遍历引用链标记可达对象从而清理不可达对象,会产生内存碎片,速度一般
复制算法不会产生内存碎片,并且速度很快,但是会浪费survivor区一半空间,并且会移动对象
标记整理算法在标记清理基础上增加整理功能,不会产生内存碎片,但会移动对象,速度慢
不同的算法有不同的特点,应对新生代可以使用复制算法,应对老年代可以使用标签清除/整理算法
增量收集使用GC、用户线程交替执行,虽然降低用户响应,但线程切换、吞吐量下降会增加GC成本
分区算法将堆内存划分为多个区,根据能够接收的停顿时间来回收性价比高的多个区,停顿时间既在能够接收时间内,又能够回收性能比高的区
最后(一键三连求求拉~)
本篇文章将被收入JVM专栏,觉得不错感兴趣的同学可以收藏专栏哟~
本篇文章笔记以及案例被收入 gitee-StudyJava、 github-StudyJava 感兴趣的同学可以stat下持续关注喔~
有什么问题可以在评论区交流,如果觉得菜菜写的不错,可以点赞、关注、收藏支持一下~
关注菜菜,分享更多干货,公众号:菜菜的后端私房菜
本文由博客一文多发平台 OpenWrite 发布!