前言
我们在刚开始学习ClickHouse的MergeTree引擎时,就会发现建表语句的末尾总会有SETTINGS index_granularity = 8192这句话(其实不写也可以),表示索引粒度为8192。在每个data part中,索引粒度参数的含义有二:
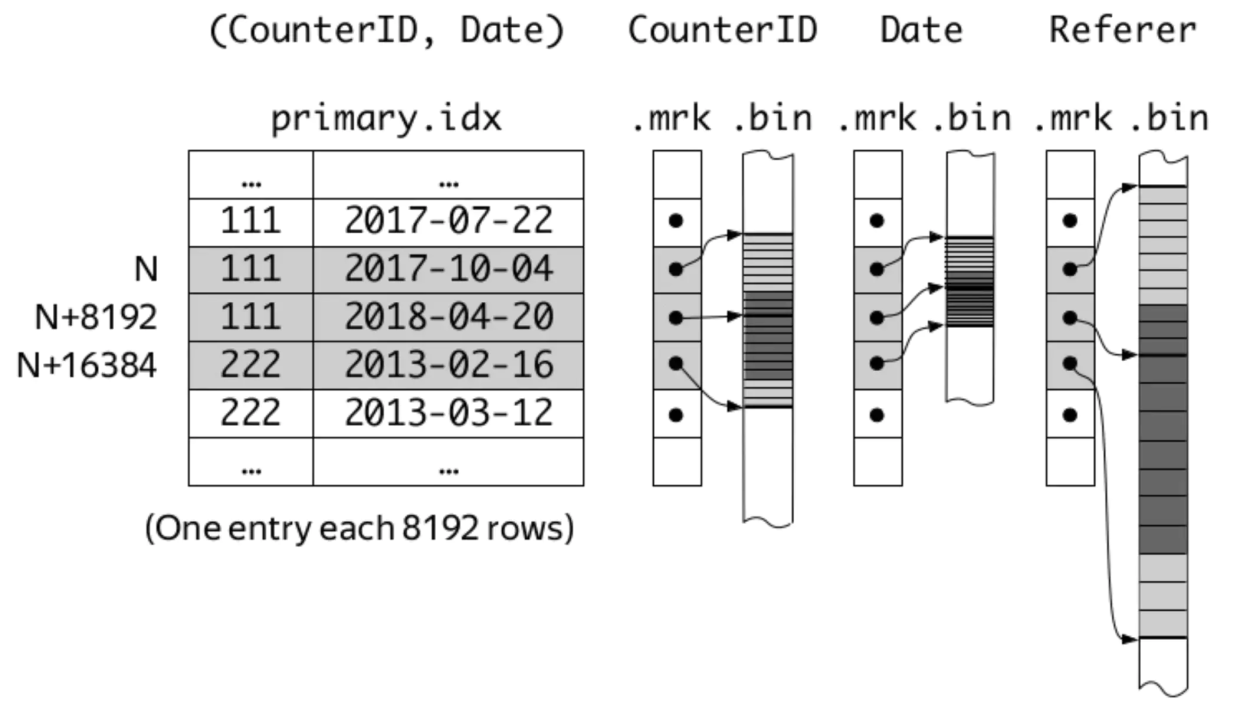
index_granularity、primary.idx、[column].bin/mrk之间的关系可以用ClickHouse之父Alexey Milovidov展示过的一幅简图来表示。
![image.png]()
但是早在ClickHouse 19.11.8版本,社区就引入了自适应(adaptive)索引粒度的特性,并且在之后的版本中都是默认开启的。也就是说,主键索引和数据标记生成的间隔可以不再固定,更加灵活。下面通过简单实例来讲解固定索引粒度和自适应索引粒度之间的不同之处。
固定索引粒度
利用Yandex.Metrica提供的hits_v1测试数据集,创建如下的表。
CREATE TABLE datasets.hits_v1_fixed
(
`WatchID` UInt64,
`JavaEnable` UInt8,
`Title` String,
-- A lot more columns...
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID)
SETTINGS index_granularity = 8192,
index_granularity_bytes = 0; -- Disable adaptive index granularity
注意使用SETTINGS index_granularity_bytes = 0取消自适应索引粒度。将测试数据导入之后,执行OPTIMIZE TABLE语句触发merge,以方便观察索引和标记数据。
来到merge完成后的数据part目录中——笔者这里是201403_1_32_3,并利用od(octal dump)命令观察primary.idx中的内容。注意索引列一共有3列,Counter和intHash32(UserID)都是32位整形,EventDate是16位整形(Date类型存储的是距离1970-01-01的天数)。
[root@ck-test001 201403_1_32_3]# od -An -i -j 0 -N 4 primary.idx
57 # Counter[0]
[root@ck-test001 201403_1_32_3]# od -An -d -j 4 -N 2 primary.idx
16146 # EventDate[0]
[root@ck-test001 201403_1_32_3]# od -An -i -j 6 -N 4 primary.idx
78076527 # intHash32(UserID)[0]
[root@ck-test001 201403_1_32_3]# od -An -i -j 10 -N 4 primary.idx
1635 # Counter[1]
[root@ck-test001 201403_1_32_3]# od -An -d -j 14 -N 2 primary.idx
16149 # EventDate[1]
[root@ck-test001 201403_1_32_3]# od -An -i -j 16 -N 4 primary.idx
1562260480 # intHash32(UserID)[1]
[root@ck-test001 201403_1_32_3]# od -An -i -j 20 -N 4 primary.idx
3266 # Counter[2]
[root@ck-test001 201403_1_32_3]# od -An -d -j 24 -N 2 primary.idx
16148 # EventDate[2]
[root@ck-test001 201403_1_32_3]# od -An -i -j 26 -N 4 primary.idx
490736209 # intHash32(UserID)[2]
能够看出ORDER BY的第一关键字Counter确实是递增的,但是不足以体现出index_granularity的影响。因此再观察一下标记文件的内容,以8位整形的Age列为例,比较简单。
[root@ck-test001 201403_1_32_3]# od -An -l -j 0 -N 320 Age.mrk
0 0
0 8192
0 16384
0 24576
0 32768
0 40960
0 49152
0 57344
19423 0
19423 8192
19423 16384
19423 24576
19423 32768
19423 40960
19423 49152
19423 57344
45658 0
45658 8192
45658 16384
45658 24576
上面打印出了两列数据,表示被选为标记的行的两个属性:第一个属性为该行所处的压缩数据块在对应bin文件中的起始偏移量,第二个属性为该行在数据块解压后,在块内部所处的偏移量,单位均为字节。由于一条Age数据在解压的情况下正好占用1字节,所以能够证明数据标记是按照固定index_granularity的规则生成的。
自适应索引粒度
创建同样结构的表,写入相同的测试数据,但是将index_granularity_bytes设为1MB(为了方便看出差异而已,默认值是10MB),以启用自适应索引粒度。
CREATE TABLE datasets.hits_v1_adaptive
(
`WatchID` UInt64,
`JavaEnable` UInt8,
`Title` String,
-- A lot more columns...
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID)
SETTINGS index_granularity = 8192,
index_granularity_bytes = 1048576; -- Enable adaptive index granularity
index_granularity_bytes表示每隔表中数据的大小来生成索引和标记,且与index_granularity共同作用,只要满足两个条件之一即生成。
触发merge之后,观察primary.idx的数据。
[root@ck-test001 201403_1_32_3]# od -An -i -j 0 -N 4 primary.idx
57 # Counter[0]
[root@ck-test001 201403_1_32_3]# od -An -d -j 4 -N 2 primary.idx
16146 # EventDate[0]
[root@ck-test001 201403_1_32_3]# od -An -i -j 6 -N 4 primary.idx
78076527 # intHash32(UserID)[0]
[root@ck-test001 201403_1_32_3]# od -An -i -j 10 -N 4 primary.idx
61 # Counter[1]
[root@ck-test001 201403_1_32_3]# od -An -d -j 14 -N 2 primary.idx
16151 # EventDate[1]
[root@ck-test001 201403_1_32_3]# od -An -i -j 16 -N 4 primary.idx
1579769176 # intHash32(UserID)[1]
[root@ck-test001 201403_1_32_3]# od -An -i -j 20 -N 4 primary.idx
63 # Counter[2]
[root@ck-test001 201403_1_32_3]# od -An -d -j 24 -N 2 primary.idx
16148 # EventDate[2]
[root@ck-test001 201403_1_32_3]# od -An -i -j 26 -N 4 primary.idx
2037061113 # intHash32(UserID)[2]
通过Counter列的数据可见,主键索引明显地变密集了,说明index_granularity_bytes的设定生效了。接下来仍然以Age列为例观察标记文件,注意文件扩展名变成了mrk2,说明启用了自适应索引粒度。
[root@ck-test001 201403_1_32_3]# od -An -l -j 0 -N 2048 --width=24 Age.mrk2
0 0 1120
0 1120 1120
0 2240 1120
0 3360 1120
0 4480 1120
0 5600 1120
0 6720 1120
0 7840 352
0 8192 1111
0 9303 1111
0 10414 1111
0 11525 1111
0 12636 1111
0 13747 1111
0 14858 1111
0 15969 415
0 16384 1096
# 略去一些
17694 0 1102
17694 1102 1102
17694 2204 1102
17694 3306 1102
17694 4408 1102
17694 5510 1102
17694 6612 956
17694 7568 1104
# ......
mrk2文件被格式化成了3列,前两列的含义与mrk文件相同,而第三列的含义则是两个标记之间相隔的行数。可以观察到,每隔1100行左右就会生成一个标记(同时也说明该表内1MB的数据大约包含1100行)。同时,在偏移量计数达到8192、16384等8192的倍数时(即经过了index_granularity的倍数行),同样也会生成标记,证明两个参数是协同生效的。
最后一个问题:ClickHouse为什么要设计自适应索引粒度呢?
当一行的数据量比较大时(比如达到了1kB甚至数kB),单纯按照固定索引粒度会造成每个“颗粒”(granule)的数据量膨胀,拖累读写性能。有了自适应索引粒度之后,每个granule的数据量可以被控制在合理的范围内,官方给定的默认值10MB在大多数情况下都不需要更改。
作者:京东物流 康琪
来源:京东云开发者社区 自猿其说 Tech 转载请注明来源