深分页怎么导致索引失效了?提供6种优化的方案!
上篇文章说到索引失效的几种规则,其中就有包括 深分页回表太多导致索引失效 的场景
本篇文章来聊聊深分页场景中的问题并提供几种优化方案,以下是本篇文章的思维导图:
![image-20240128150009803.png]()
深分页问题
那么什么是深分页问题呢?
在MySQL的limit中:limit 100,10MySQL会根据查询条件去存储引擎层找到前110条记录,然后在server层丢弃前100条记录取最后10条
这样先扫描完再丢弃的记录相当于白找,深分页问题指的就是这种场景(当limit的偏移量过大时会导致性能开销)
-- 0.04s
select SQL_NO_CACHE * from student where age = 18 limit 10;
-- 4.049s
select SQL_NO_CACHE * from student where age = 18 limit 5000,10;
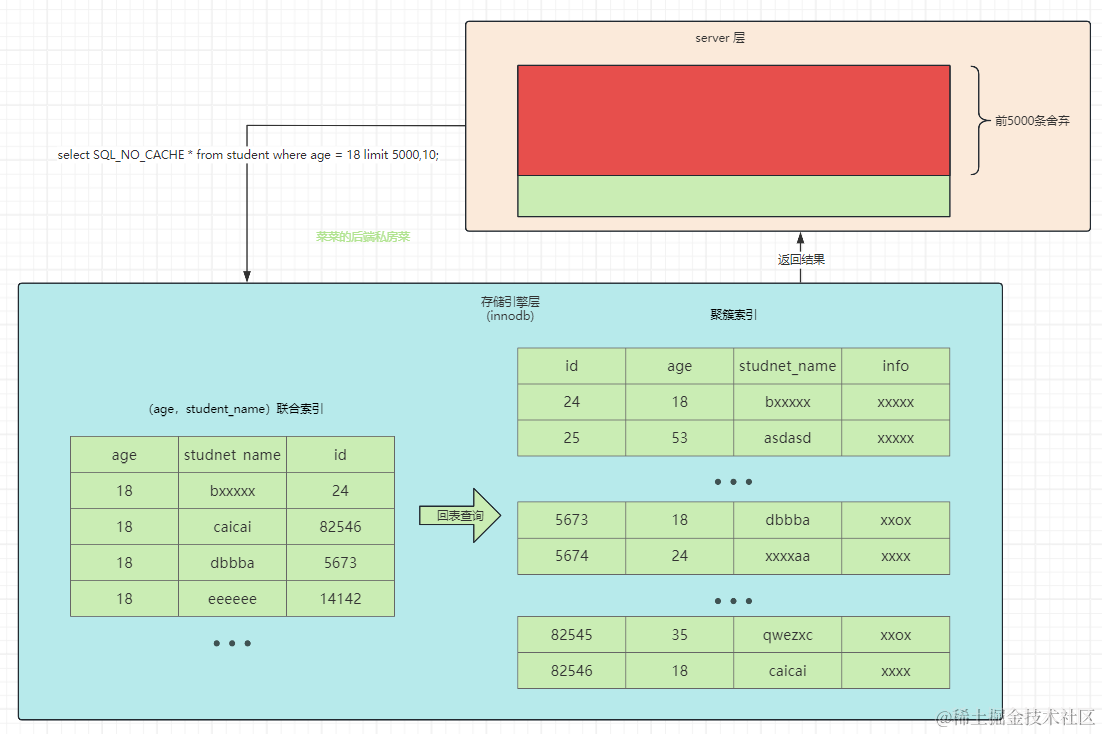
该表中存在二级索引:idx_age_name 是学生年龄age和学生名称name的联合索引(该二级索引上只存在字段age,name,id)
这条SQL会基于MySQL最优成本选择使用 idx_age_name 或者 聚簇索引
假设它使用二级索引 idx_age_name,我们来分析一下使用二级索引的流程:
-
它会先根据二级索引定位到第一条满足age=18的记录
-
由于二级索引上的记录没有完整字段,因此会回表查询聚簇索引获取完整字段
-
将结果返回给server层,并根据这条记录的next找到下一条记录
循环1-3的过程,在二级索引上找到满足查询条件age=18的前5010条记录(或者直到不满足age=18),然后舍弃前5000条,取最后10条
![image-20240128120002319.png]()
在这个过程中:先查二级索引接着回表获取完整记录然后返回给server层再查下一条记录
由于二级索引是联合索引,当age相等时,主键id不一定是有序的,这样回表就会产生随机IO
当深分页场景使用二级索引时会涉及回表(随机IO),如果偏移量太大回表的数据量也会很大,MySQL认为成本太大不偏向使用二级索引从而导致索引失效
那么该如何优化深分页这样的问题呢?从这里分析可以得到从两个方面进行优化:
- 让它不要回表,避免回表的开销
- 让它不要舍弃前XX条记录,避免白查询
接下来结合不同的方法进行讨论
覆盖索引避免回表
当业务上允许时可以使用覆盖索引避免回表,查完二级索引就交给server层再去查下一条记录
-- 4.049s
select SQL_NO_CACHE *
from student
where age = 18 limit 5000,10;
-- 0.034s
select SQL_NO_CACHE id,age,student_name
from student
where age = 18 limit 5000,10;
虽然说覆盖索引依旧会舍弃前XX条记录,但没有回表的开销已经快了不少
但如果业务上不允许还是要查较多在聚簇索引上的字段,又或者偏移量还是太大的情况,我们还是需要使用其他的方案
游标分页
为了避免limit中的偏移量,可以自己来存储该偏移量
我们可以使用上次查询的最大值来当作这次的查询条件(游标分页)
-- 12.899s
select * from seat
where seat_code = 'caicaiseat'
limit 99990,10; -- 最后一条记录 seat_id = 988380
select * from seat
where seat_code = 'caicaiseat' limit 100000,10;
-- 0.189s 满足查询条件情况下主键有序 可以使用上一次记录
select * from seat
where seat_code = 'caicaiseat' and seat_id > 上次查询最大记录
limit 10;
select * from seat
where seat_code = 'caicaiseat' and seat_id > 988380
limit 10;
其中limit 100000,10 与 seat_id > 988380 limit 10 查询结果相同,但是这种做法是有前提条件的
前提条件
- 需要一个列来记录上一次查询的最大值(通常是主键,后面就直接用主键表达,大家明白就好),并且满足查询条件时主键需要是有序的
- 因为本次查询需要依赖上一次查询的主键最大值,因此分页查询只能是连续的,不能进行跳页(比如查完第一页直接查第一百页)
在上面案例SQL中会使用二级索引 idx_seat_code (seat_code,seat_id),当使用二级索引时,由于seat_code是等值查询,满足条件时id是有序的
如果是原来的SQL使用这种做法会导致查询出来的结果不一致,因为在二级索引上当age = 18时主键不一定有序
select SQL_NO_CACHE * from student
where age = 18 and id > 6726705
limit 10;
乱序该如何解决呢?当然是排序呀!
select SQL_NO_CACHE * from student
where age = 18 and id > 上次查询最大记录
order by id
limit 10;
但是排序又会带来新的问题:可能更偏向使用聚簇索引(全表扫描),如果使用二级索引还需要对id排序(临时表),具体还要查看执行计划分析
游标分页排序下的SQL和原始limitSQL结果是不同的,因为原始的id无序,但它们都满足(业务)查询条件age=18,只是做分页时顺序不同
-- 原始limit SQL
select SQL_NO_CACHE * from student
where age = 18
limit 5000,10;
-- 游标分页
select SQL_NO_CACHE * from student
where age = 18 and id > 上次查询最大记录
order by id
limit 10;
使用游标分页时需要使用主键记录每次查询的最大值,并且需要满足查询条件后主键值是有序的,只能在连续分页的场景使用,不能跳页,比如滑动分页(一边滑动一边分页)
子查询定位
另一种避免limit 偏移量太大的方式是通过子查询定位到第一条记录
子查询也是类似于游标分页,定位第一条记录就相当于先找到偏移量
select * from seat
where seat_code = 'caicaiseat'
limit 100000,10;
-- 0.068s 通过二级索引先定位到主键值
select * from seat
where seat_code = 'caicaiseat'
and seat_id >=
(select seat_id from seat
where seat_code = 'caicaiseat'
limit 100000,1)
limit 10;
使用子查询 select seat_id from seat where seat_code = 'caicaiseat' limit 100000,1 定位到第一条记录的主键值
然后再通过 seat_id >= 定位到的第一条记录 limit 10 查出需要的10条记录
子查询定位的方案也有使用前提:
-
子查询可以使用二级索引快速定位(不用回表)
-
满足查询条件后主键需要有序(因为使用 seat_id >= )
子查询定位支持跳页,但需要使用二级索引定位且满足条件后主键值有序
in + 子查询
在游标分页与子查询使用二级索引定位的场景中总是需要记录偏移量的列(主键)有序,遇到无序的场景还需要排序,增加性能开销
有没有更好的办法避免排序呢?
id >= X 需要主键有序,但是 id in (x,x...) 似乎就不需要主键有序了呀
使用子查询常用的搭配in,因为分页时子查询数据量也不大,可以使用in来进行查询
select SQL_NO_CACHE * from student
where age = 18
and id in
(select id from student
where age = 18
limit 5000,10);
但是MySQL好像不支持in与limit同时使用,这样使用会报错
1235 - This version of MySQL doesn't yet support 'LIMIT & IN/ALL/ANY/SOME subquery'
于是只能把子查询的结果封装成临时表
select SQL_NO_CACHE *
from student
where age = 18
and id in
(select id
from (select id
from student
where age = 18
limit 5000,10)
tmp);
in + 子查询的方案即支持跳页又不用排序,虽然会生成临时表但数据量较少
联表查询 + 子查询
熟悉MySQL中in优化(半连接)的同学,一定能够知道in与内连接的奇妙关系
在某些符合条件的场景下,in会被优化为内连接
(感兴趣或者不熟悉的同学可以看这篇文章MySQL半连接优化)
当然我们也可以手动编写内连接的联表查询来让其进行关联
-- 4.049s 原始
select SQL_NO_CACHE *
from student
where age = 18
limit 5000,10;
-- 0.033s 联表 + 子查询
select SQL_NO_CACHE *
from student s
inner join (select id tmp_id
from student
where age = 18
limit 5000,10) tmp
on s.id = tmp_id
联表查询的思路与in相同,都能够支持跳页和主键无序
需求沟通
其实这几种方案要么实现不回表,要么实现不用偏移量,在解决这类问题时其实要先与需求进行沟通:
1、是否有必要查这么多记录,记录太多时能否提醒用户减少查询范围(比如起止时间)
2、如果不能修改查询条件的情况下且数据量确实大(比如查18岁学生还有很多分页),考虑是否能让用户翻页翻到这么后呢?
...
总结
本文描述发生深分页问题的原因以及各种解决方案,总结如下:
| 方法 |
描述 |
使用前提 |
优点 |
缺点 |
| 覆盖索引 |
通过覆盖索引避免回表,limit还是会放弃前XX条记录 |
查询的列都在二级索引上 |
不用回表,避免随机IO |
还是会舍弃前XX条记录 |
| 游标分页 |
通过主键记录偏移量,避免limit放弃前XX条记录 |
记录主键,满足条件时主键需要有序 |
避免limit放弃前XX条记录 |
不能跳页,如果满足条件时主键无序还需要排序 |
| 子查询定位 |
通过使用二级索引子查询快速定位第一条偏移量的记录,避免limit放弃前XX条记录 |
使用二级索引定位,满足条件时主键需要有序 |
与游标分页相比,能够跳页 |
子查询时还是会舍弃前XX条记录,如果满足条件时主键无序还需要排序 |
| in + 子查询 |
使用in关联子查询定位的主键 |
使用二级索引定位,使用临时表 |
支持跳页、主键无序 |
生成临时表,子查询数据量大会影响性能 |
| 联表 + 子查询 |
使用内连接关联子查询定位的主键 |
使用二级索引定位,使用临时表 |
支持跳页、主键无序 |
生成临时表,子查询数据量大会影响性能 |
| 需求沟通 |
根据具体场景进行沟通防止深分页问题发生 |
产品经理答应 |
省事 |
产品经理没那么容易答应 |
深分页问题是因为MySQL limit时,会先把记录查询出来,再舍弃前XX条记录所导致的
不同的方案适合不同的业务场景,在收到数据量较大的分页需求时先进行沟通,无法避免时再做优化
如果需要查询的列在二级索引上都存在,可以使用二级索引(覆盖索引)避免回表
如果满足查询条件后主键有序并且业务上不用跳页那么可以选择游标分页
如果满足查询条件后主键有序并且业务上需要支持跳页,可以选择子查询
如果满足查询条件后主键(记录偏移量的列)无序,那么可以选择in或联表的方案
本文由博客一文多发平台 OpenWrite 发布!