从 greptimedb#1733 开始,GreptimeDB 使用 Jemalloc 作为默认的内存分配器,这不仅有助于提升性能和降低内存碎片,也提供了便捷的内存分析功能。在 记一次 Rust 内存泄漏排查之旅 | 经验总结篇 这篇文章中,我们介绍了分析 Rust 应用内存泄漏的几种常用方法,而在本文中将详细介绍基于 Jemalloc 的排查手段。
当您在使用或者开发 GreptimeDB 的过程中,如果遇到内存使用量异常的问题,可以参照本篇文章快速排查和定位可能存在的内存泄漏。
准备工作
安装必要工具
安装 flamegraph.pl 脚本
curl -s https://raw.githubusercontent.com/brendangregg/FlameGraph/master/flamegraph.pl > ${HOME}/.local/bin/flamegraph.pl
chmod +x ${HOME}/.local/bin/flamegraph.pl
export PATH=$PATH:${HOME}/.local/bin
flamegraph.pl 是由 Brendan Gregg 编写的用于可视化热点代码调用栈的一个 Perl 脚本。Brendan Gregg 是一位致力于系统性能优化的专家,在此感谢他开发并开源了包括 flamegraph.pl 在内的诸多工具。
安装 jeprof 命令
# For Ubuntu
sudo apt install -y libjemalloc-dev
# For Fedora
sudo dnf install jemalloc-devel
对于其他操作系统,您可以通过 pkgs.org 来查找 jeprof 的依赖包。
启用 GreptimeDB 的内存分析功能
GreptimeDB 的内存分析功能是一个默认关闭的特性,您可以通过在编译 GreptimeDB 时打开 mem-prof feature 来启用此功能。
cargo build --release -F mem-prof
关于是否应该默认开启 mem-prof 特性,greptimedb#3166 正在进行讨论,您也可以留下您的看法。
启动 GreptimeDB 并启用 mem-prof 功能
为了启用内存分析功能,在启动 GreptimeDB 进程时也需要设置环境变量MALLOC_CONF:
MALLOC_CONF=prof:true ./<path_to_greptime_binary> standalone start
您可以通过 curl 命令来检查内存分析功能是否正常使用:
curl <greptimedb_ip>:4000/v1/prof/mem
如果内存分析功能已经启用,此命令会返回类似如下的响应:
heap_v2/524288
t*: 125: 136218 [0: 0]
t0: 59: 31005 [0: 0]
...
MAPPED_LIBRARIES:
55aa05c66000-55aa0697a000 r--p 00000000 103:02 40748099 /home/lei/workspace/greptimedb/target/debug/greptime
55aa0697a000-55aa11e74000 r-xp 00d14000 103:02 40748099 /home/lei/workspace/greptimedb/target/debug/greptime
...
否则如果返回 {"error":"Memory profiling is not enabled"} ,则说明 MALLOC_CONF=prof:true 环境变量未正确设置。
关于 内存分析 API 所返回的数据格式,请参考 HEAP PROFILE FORMAT - jemalloc.net。
开始您的内存探险!
通过 curl <greptimedb_ip>:4000/v1/prof/mem 命令,您可以快速获取 GreptimeDB 所分配的内存详情;通过 jeprof 和 flamegraph.pl 可以将内存使用详情可视化为火焰图:
# 获取内存分配详情
curl <greptimedb_ip>:4000/v1/prof/mem > mem.hprof
# 生成内存分配的火焰图
jeprof <path_to_greptime_binary> ./mem.hprof --collapse | flamegraph.pl > mem-prof.svg
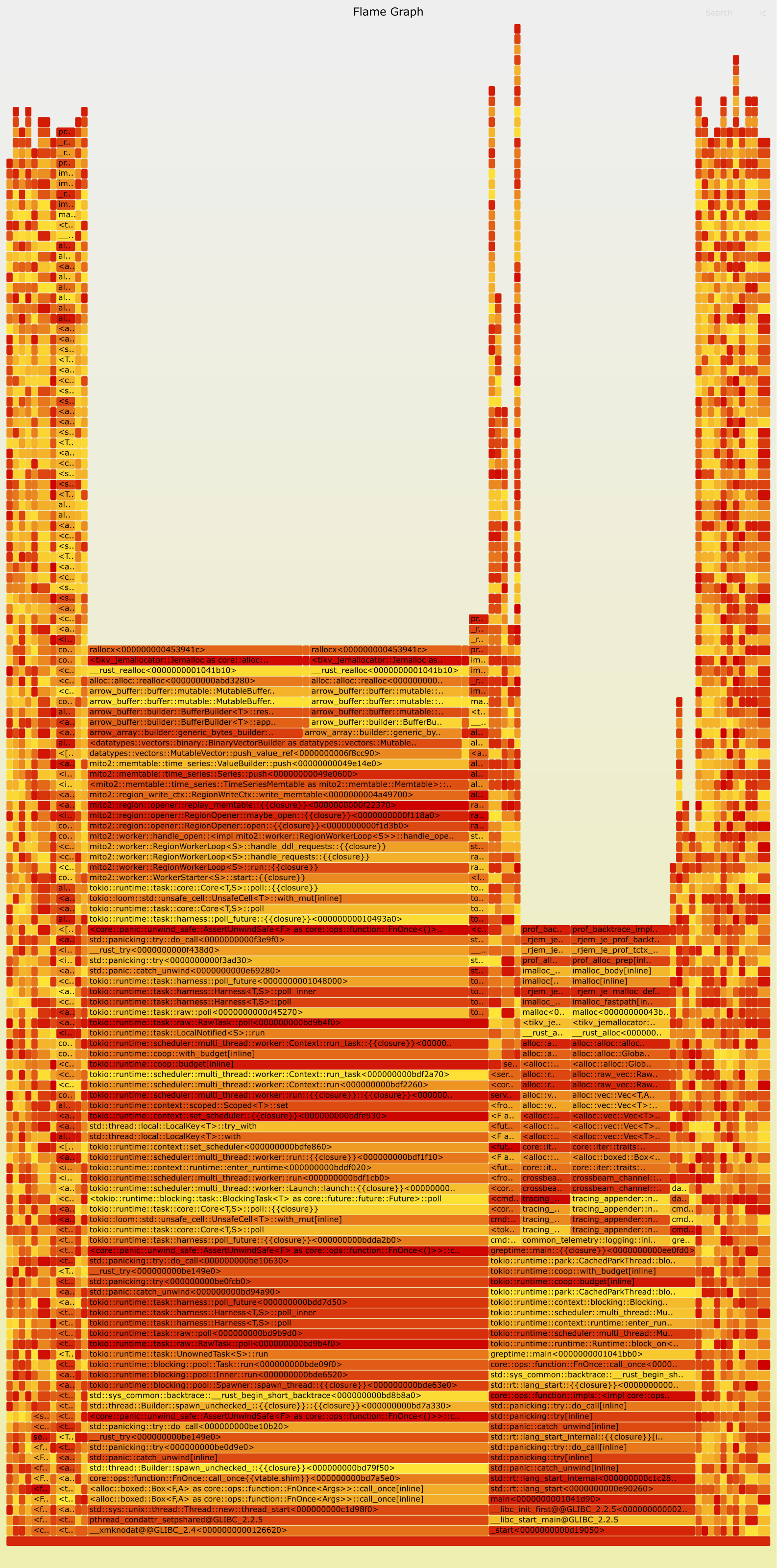
执行完以上命令后将在当前目录生成文件名为 mem-prof.svg 的火焰图: ![]()
如何阅读火焰图
火焰图是由 Brendan Gregg 创造的一种能够对 CPU 开销和内存分配详情进行分析的利器,其生成原理是,在每次采样内存分配事件时,记录触发此次内存分配的函数调用栈。在记录足够多次后,将每次分配的调用栈合并,从而得到每个函数调用以及其所调用的函数所分配的内存大小。
- 火焰图的最下方为函数栈的栈底,而最上方为栈顶;
- 火焰图中每一个格子代表一个函数调用,格子下方为此函数的调用者(caller),格子上方为此函数所调用的子函数(callee);
- 格子的宽度代表此函数及其子函数所有分配内存的总量。当我们发现某些函数的格子较宽,说明此函数分配的内存较多。如果某些函数分配内存较多但是其子函数分配却并不多(如下图,火焰图中存在较宽的栈顶,即 plateaus),说明此函数自身可能存在大量分配操作;
![]()
- 火焰图中每个格子的颜色是随机的;
- 在浏览器中打开火焰图的 SVG 文件可以交互式地点击进入每个函数进行更加具体的分析。
快 1 倍!加速火焰图的生成
Jemalloc 返回的堆内存详情包含了调用栈各个函数的地址,在生成火焰图时需要将地址翻译成文件名和行号,而这正是耗时最长的步骤。通常在 Linux 系统下,这项工作是由 GNU Binutils 中的 addr2line 工具完成的。为了加快火焰图生成的速度,我们可以用 glimi-rs/addr2line 来替换 Binutils 的 addr2line 工具,从而可以获得至少 1 倍的速度提升。
git clone https://github.com/gimli-rs/addr2line
cd addr2line
cargo build --release
sudo cp /usr/bin/addr2line /usr/bin/addr2line-bak
sudo cp target/release/examples/addr2line /usr/bin/addr2line
通过内存分配差值来捕捉内存泄漏
在常见的内存泄漏场景中,内存的使用量往往是缓慢增长的。因此我们在内存增长的过程中,分别截取两个时间点的内存使用情况,两者之差往往指示着可能出现内存泄漏的地方。
我们可以在初始时间点采集一次内存作为基准:
curl -s <greptimedb_ip>:4000/v1/prof/mem > base.hprof
当内存缓慢增长,疑似出现内存泄漏时,再一次采集内存:
curl -s <greptimedb_ip>:4000/v1/prof/mem > leak.hprof
然后以 base.hprof 作为基准分析内存占用并生成火焰图:
jeprof <path_to_greptime_binary> --base ./base.hprof ./leak.hprof --collapse | flamegraph.pl > leak.svg
在使用 --base 参数指定基准生成的火焰图中,只会包含本次采集内存分配和基准之间的内存差值的分配情况,从而能够更加清晰地看到内存使用量的增长到底是由哪些函数调用产生的。
关于 Greptime 的小知识:
Greptime 格睿科技于 2022 年创立,目前正在完善和打造时序数据库 GreptimeDB,格睿云 GreptimeCloud 和可观测工具 GreptimeAI 这三款产品。
GreptimeDB 是一款用 Rust 语言编写的时序数据库,具有分布式、开源、云原生和兼容性强等特点,帮助企业实时读写、处理和分析时序数据的同时降低长期存储成本;GreptimeCloud 可以为用户提供全托管的 DBaaS 服务,能够与可观测性、物联网等领域高度结合;GreptimeAI 为 LLM 量身打造,提供成本、性能和生成过程的全链路监控。
GreptimeCloud 和 GreptimeAI 已正式公测,欢迎关注公众号或官网了解最新动态!
官网:https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
文档:https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime/