今年下半年机缘巧合下公司决定搭建自己的数据中台,中台的建设势必少不了数据集成。首先面临的就是数据集成技术选型的问题,按照社区活跃度、数据源适配性、同步效率等要求对市面上几个成熟度较高的开源引擎进行了深度调研。
最终经过内部讨论决定用Apache SeaTunnel作为数据集成的基础能力。
贡献经历
在了解Apache SeaTunnel之前,自己基本没有深入参与过开源项目,大多都是工作需要从而来使用。虽然内心有想尝试开源,但由于没有合适的机会,就一直没有实践。而SeaTunnel目前正处于高速迭代的阶段,这让我看到了一丝契机。
碰到问题
大概是在今年的7月份,公司在使用MySql-CDC做数据同步时遇到了一个问题,在数据同步前期任务可以正常运行,但是在运行一段时间后发现Server端日志中出现大量的GC输出,并且看到GC对内存回收效率不高。
尝试解决
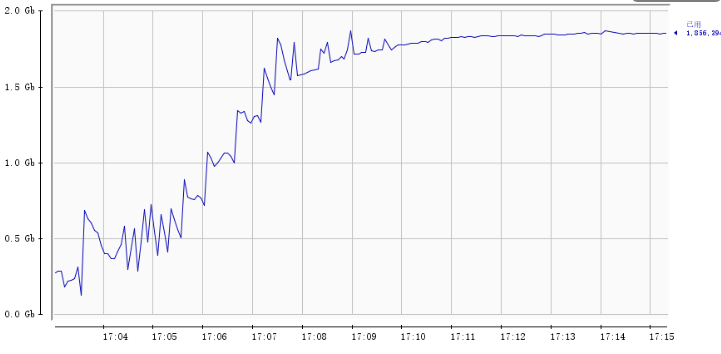
因为在这之前我们的批作业是能够正确完成,所以首先排除了由于使用不当的原因。由于是内存问题,我们尝试减小JVM堆内存参数,并开启了JMX内存监控,重新运行CDC任务尝试复现问题,不出意外问题再一次出现了,根据内存监控发现CDC任务运行过程中堆内存持续增长,如下图所示:
![file]()
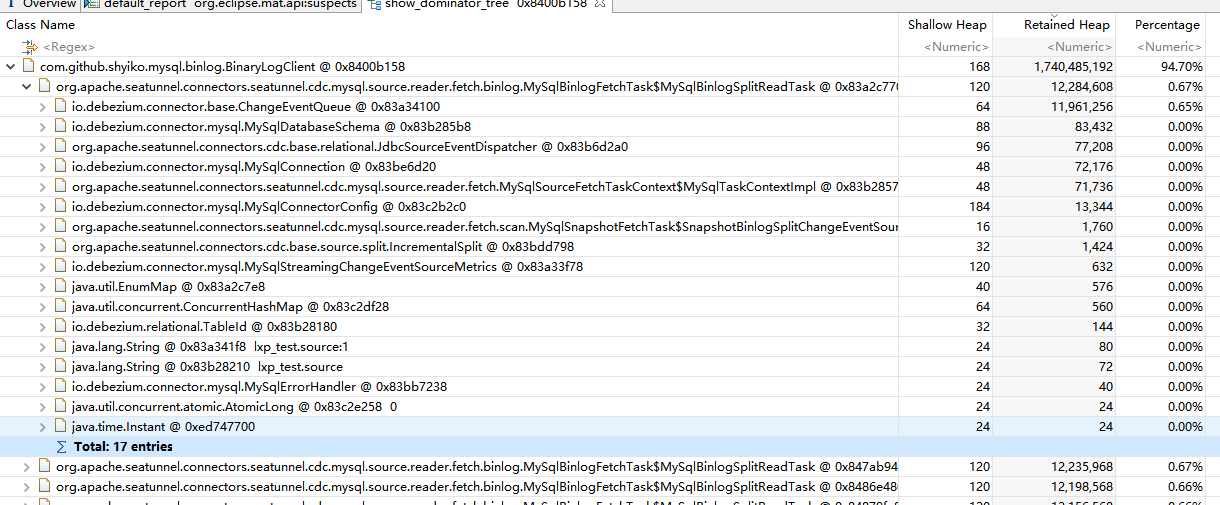
到这里基本能够确定是代码导致的内存泄漏。此时就需要深入分析当前JVM的内存情况了,这里我是通过jmap将堆内存dump到本地,使用MemoryAnalyzer进行分析,具体情况如下图:
![file]()
上图是MemoryAnalyzer中的Leak Suspects,它反映的是堆中的占比较大对象,有很大概率是这些对象导致了内存异常,从图中可以看到一个BinaryLogClient的对象无法被回收,与它关联的对象大概占用了1.7个G内存,再深入分析其关联对象,如下图:
![file]()
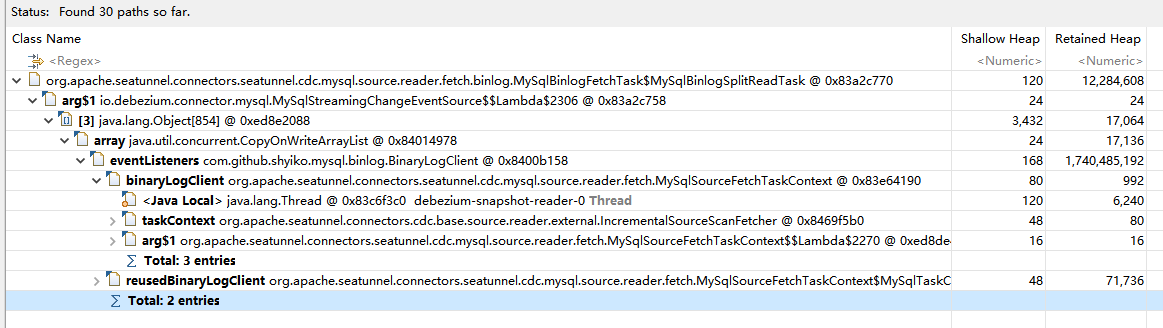
可以看到在MySqlBinlogSplitReadTask中持有了这个引用,接下来再继续深入分析该对象的引用:
![file]()
找到原因
最终发现在BinaryLogClient对象中,存在一个eventListeners的事件监听器,此时带着这个点,深入源码进行问题排查。
阅读源代码
在阅读源码的过程中,了解到eventListeners是在数据同步抽取阶段用来监听binlog的变更,将变更数据收集到一个队列中,再由后续任务处理。
而MySqlBinlogSplitReadTask是用来补偿CDC快照阶段时产生的变更数据,每个MySqlBinlogSplitReadTask的执行都会向BinaryLogClient中注册一个当前的事件监听,当监听到binlog有变更时,将变更数据收集到自己分片的队列中去,且每个任务只处理当前分片范围内的binlog记录,处理完后补偿任务就会结束。但是在图3中可以看到当前仍有较多数量的Task未被释放,这与设计不符。
分析到这儿,问题的原因就浮出水面了,由于的BinaryLogClient是复用的,补偿任务在执行前会向其注册事件监听,但是未在任务结束后剔除该监听,导致后续阶段的binlog变更会因为监听未释放从而不断地写入各自分片队列且无法被消费,最终导致内存持续增长。
动手解决
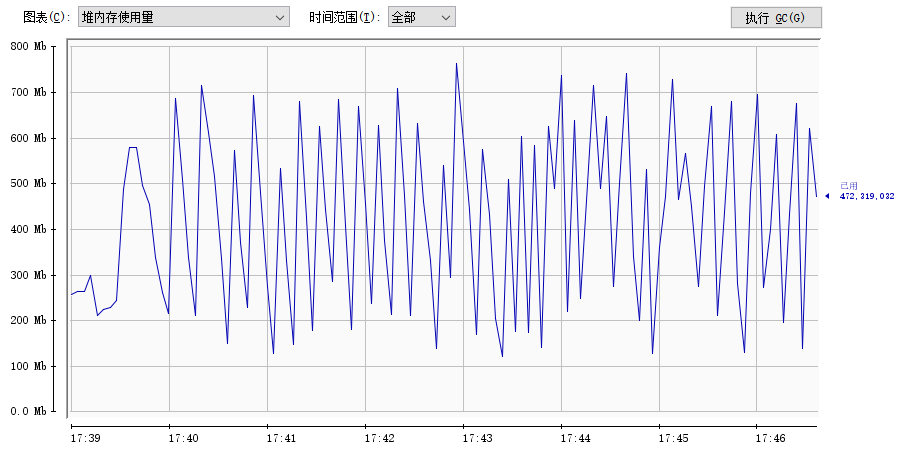
根据上述分析,我调整了对应代码,在快照分片任务初始化时,手动注销上个分片注册的监听,然后进行调试,最终发现内存曲线恢复正常,如下图:
![file]()
至此问题在本地算是解决了,但是考虑到项目性质是开源的,首先这个问题只在本地修复,以后版本更新需要再次修正,其次其他正在使用SeaTunnel的小伙伴也会遇到这样的问题。想到这里,我决定迈出自己的开源第一步,将这个问题的发现及解决提交到社区,同样也希望自己解决问题的办法能够得到社区的认可。
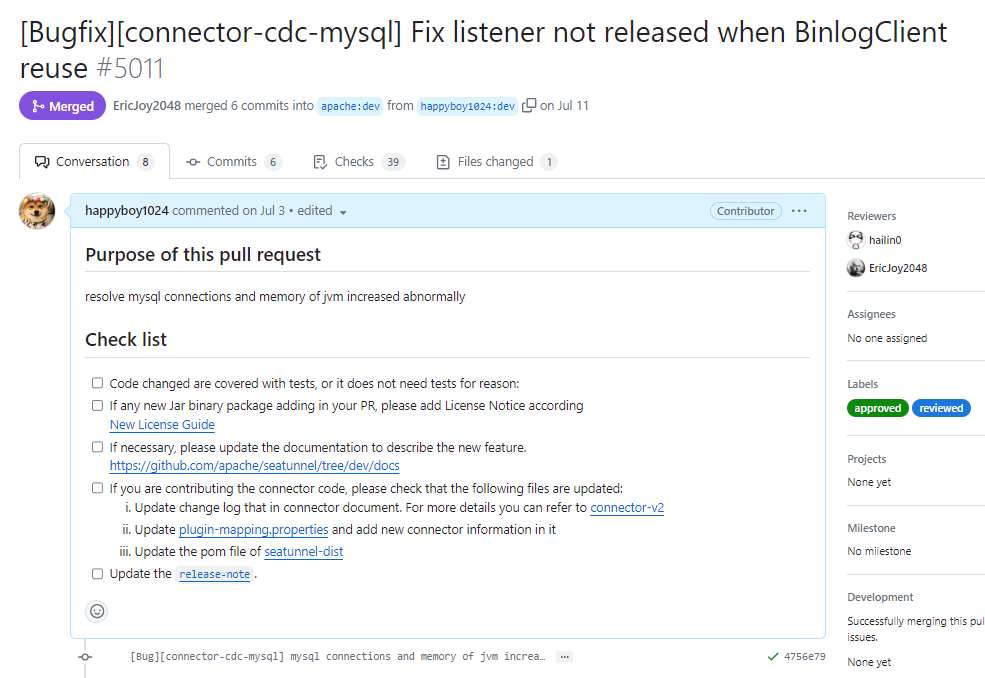
以下便是解决这个问题提交的PR:
![file]()
当然这个PR并没有想象中的一帆风顺,具体原因是在修复代码时没有考虑好维护性,因此社区大佬给出了调整意见,经过后续修改最终这个PR还是被成功合并。
在这次提交PR的经历上,虽然过程有一些小插曲,但结果总算是好的,看到自己的PR能够被社区采纳,内心还是十分喜悦。正是因为这一份喜悦,让我有了更多的动力,愿意解决更多的问题。通过这次经历也想告诉大家,参与开源,贡献开源并不是想象中的那么困难,如果你不去尝试,那么你永远不会知道结果会如何。
如何参与社区
开源社区的贡献形式有很多,如代码贡献、文档贡献、发现并提交问题、问题答疑等。今天主要和大家分享一下如何在SeaTunnel中贡献自己的代码,也就是大家提到的PR(Pull Request)。
因为环境由公司到社区的转变,相对应的规范肯定也有所不同,没有统一的规范,开源将变得没有规则,那么大家提交的东西一定是乱成一团。
因此我们首先需要了解SeaTunnel提交PR的流程规范,具体大家可以搜索这篇文章:【共建开源】手把手教你贡献一个SeaTunnel PR,教程超级详细!我在这篇文章的基础上补充了几个点,防止后续小伙伴们踩坑,具体我已经标注,整个过程分为如下几个步骤: ● Fork项目 ● Clone fork项目到本地环境中 ● 基于开发分支dev创建新的分支,分支命名能够体现这次修改内容 ● 代码修改、测试
在SeaTunnel中,代码测试有几个步骤,首先是自己本地的测试,在修正完代码后,需要本地运行或是打包到服务器上测试功能是否正常。
其次是如果是新功能则需要添加对应的e2e测试用例,需要注意的是数据源以及Flink、Spark引擎相关功能的e2e都是运行在docker上,因此这类测试还需要本地安装docker环境。具体可以参考TestContainers官方。
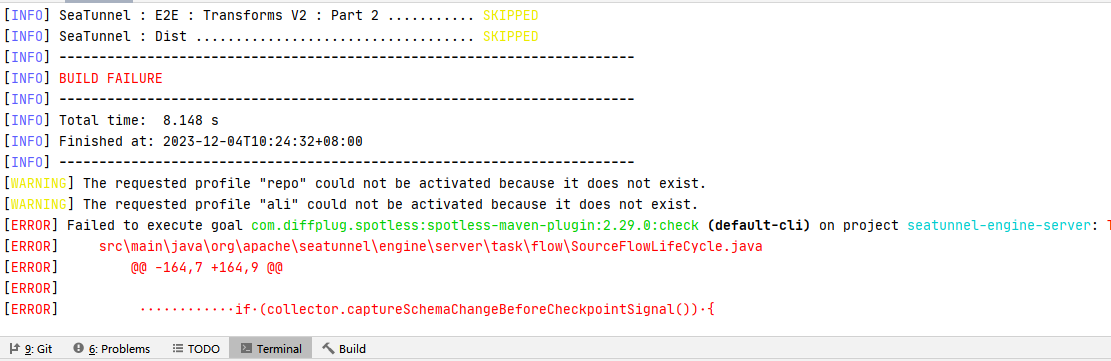
● 代码格式检查 在前文提到的PR贡献教程文章中没有提到代码格式检查的步骤,在SeaTunnel中使用了maven插件spotless来规范我们的代码格式,首先我们需要执行mvn spotless:check命令,若在编译阶段发现有未通过格式检查的代码,则需要通过mvn spotless:apply来格式化。
这是使用spotless check检查失败的输出,我们可以看到在某个类中的某些代码未通过格式检查。
![file]()
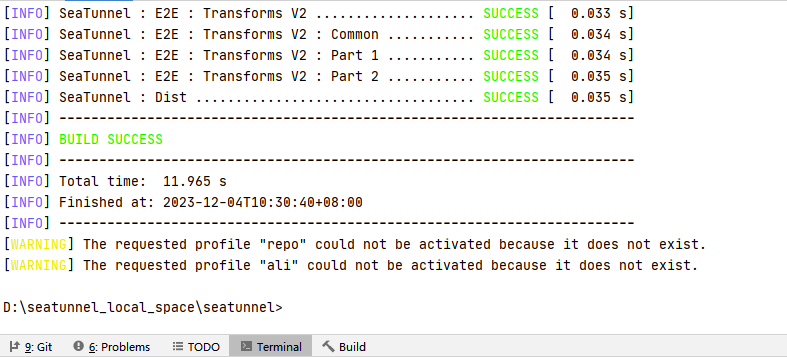
发现有代码未通过检查后,我们通过spotless apply来格式化代码。
![file]()
● 提交代码,以 [Feature/Bugfix/Improve/...][Modul Name] message 的格式规范自己的Commit Message ● 创建issue,描述清楚自己遇到的问题,并提供运行环境、引擎版本、配置信息、异常日志等
注意事项:大家在提交issue的时候附上自己Server端日志会方便社区排查 ● 到GitHub中创建PR,同样PR命名也需要遵守[Feature/Bugfix/Improve/...][Modul Name] title 格式,PR需要描述解决了如何问题,以及关联对应的issue ● 等待社区成员review代码,若需要修改,则在之前提交的分支中进行调整,并重新推送 ● 等待CI检查,完成后等待审核
以上就是我如何参与SeaTunnel社区,以及贡献的经历,相信大家看了我的经历会发现开源离自己并不是那么的遥远,当然也希望有更多小伙伴能够积极参与进来!
本文由 白鲸开源科技 提供发布支持!