![file]()
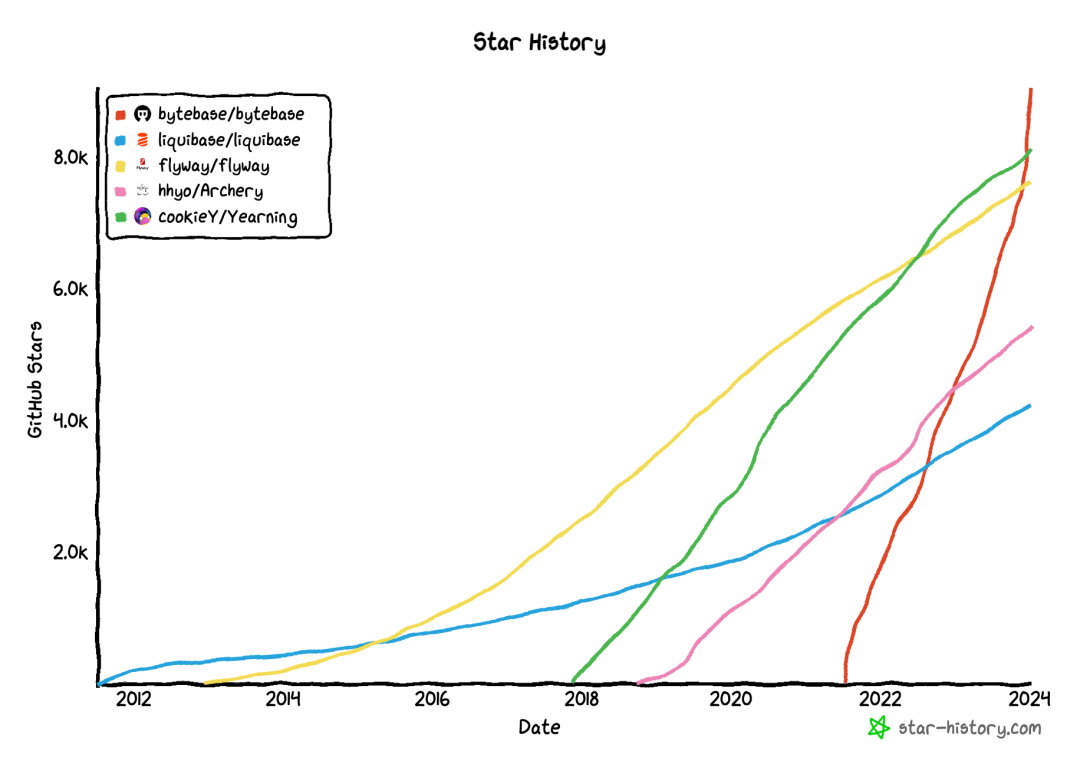
Bytebase 是面向研发和 DBA 的数据库 DevOps 和 CI/CD 协同平台。目前 Bytebase 在全球类似开源项目中 GitHub Star 数排名第一且增长最快。
![file]()
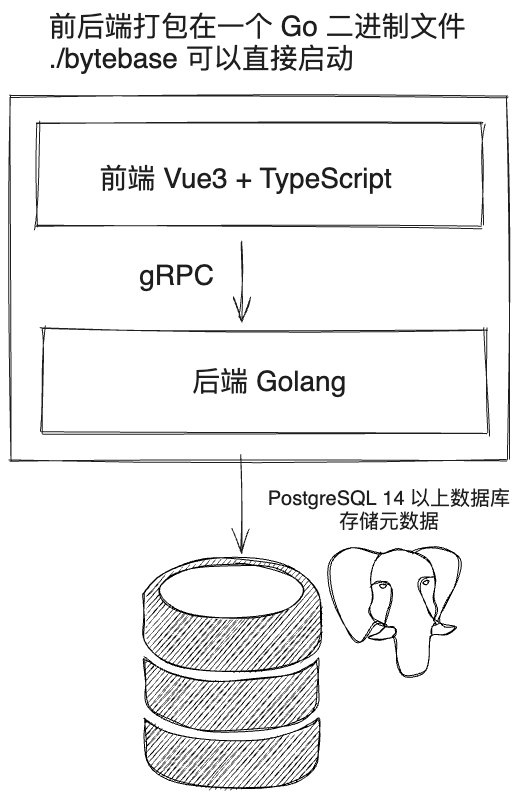
Bytebase 的架构
Bytebase 是一个单体架构 (monolith),前端是 Vue3 + TypeScript,后端是 Go。前端利用 Go 1.6 引入的 embed 功能 把前后端代码打包在了一个二进制文件中。Bytebase 的元数据则存在 PostgreSQL 中。
![file]()
PostgreSQL 元数据库
同样利用 Go embed 功能,Bytebase 的二进制文件也内置了 PG 数据库。这样用户只要在命令行执行 ./bytebase 就能运行一个拥有前后端 + 数据库的完整 Bytebase 应用。不过在生产环境,我们建议用户通过 --pg 来配置外部的 PostgreSQL 数据库,版本要求 14 及以上。这样用户可以独立保障数据库的稳定性以及对数据进行备份。
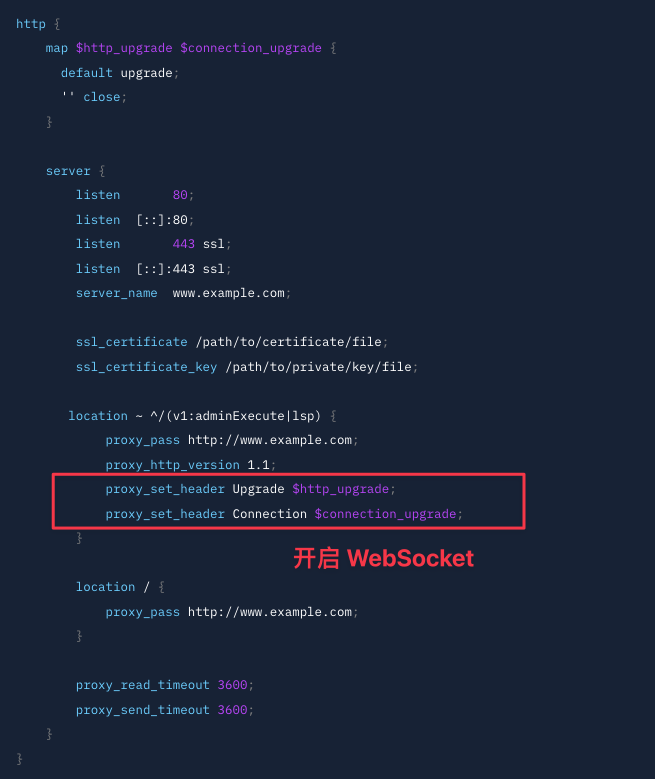
配置 NGINX 网关
Bytebase 本身不提供 https 能力,需要使用如 NGINX 这样的网关来实现 https 访问。此外为了支持 SQL Editor 中的自动补全,还需要在网关中开启 WebSocket。下图是一个 NGINX 配置示例
![file]()
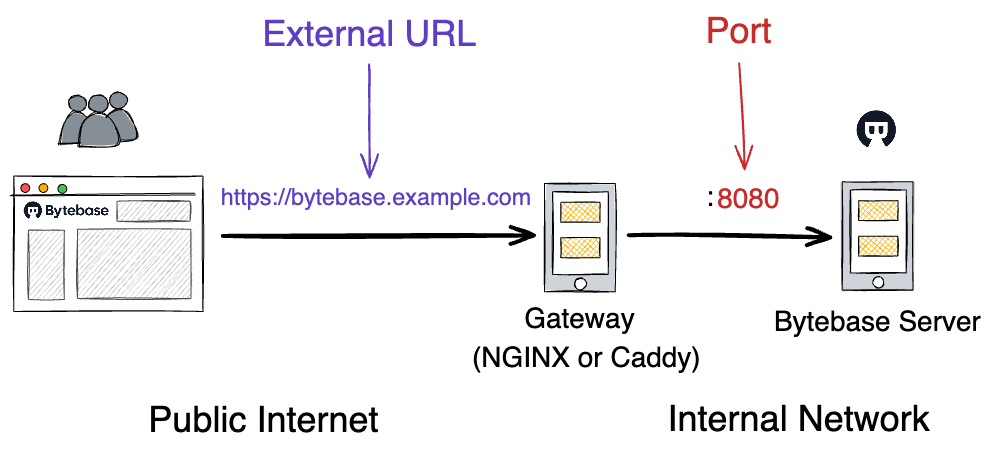
配置 External URL
![file]()
为了使得 SSO 以及 GitOps 流程可以正常工作,用户需要配置正确的 --external-url 参数。这个参数就是用户访问 Bytebase 的网页URL。如果配置了网关,那就是通过网关暴露出的 Bytebase URL。
Docker 以及 Kubernetes
Bytebase 也提供了 Docker 镜像和 Kubernetes 的 Helm Chart。用户也可以到 Sealos, Rainbond, Zeabur 一键部署 Bytebase 镜像。
机器资源
如果已经配置了外部元数据库,那么运行 Bytebase 本身,1C2G 的机器配置就够了。只有在同时变更大批量的大 SQL 时(我们确实有用户会同时变更上百个数据库,并且每条 SQL 都要 10 MB),才需要根据 SQL 的大小调高内存。
总结
从架构上 Bytebase 就做了简化,以达成一行命令 ./bytebase 就能启动完整应用的效果。再通过如上所述的几个配置,Bytebase 就能稳稳地运行在生产环境中了。
💡 更多资讯,请关注 Bytebase 公号:Bytebase