2024 开年巨献,深度解读 DeepSeek 大模型背后的技术秘密..
一个月前,深度求索开源了670 亿参数的大模型 (DeepSeek LLM 67B) ,在近 40 个中英文榜单上全面超越了700 亿的 LLaMA 2。
全系列模型已开源至 Hugging Face, 无需申请免费商用 ,目前已累积 超 5.8 万次下载 。
https://hf.co/deepseek-ai
今天,我们将 40+ 页的DeepSeek LLM技术报告发布至 Arxiv,并在本文深度解读其后的关键技术。
论文地址:https://arxiv.org/abs/2401.02954
自建全面Scaling Laws,为模型扩大更好奠基
-
深入探索了 超参数的Scaling Law s :为选择最佳超参数(Batch Size、 Learning Rate)提供了经验框架
-
详细论证了 数据质量 对Scaling Laws的影响 :同等数据规模下,数据质量越高,最优参数规模越大
完整的对齐实践细节,全方位的AGI能力评估
-
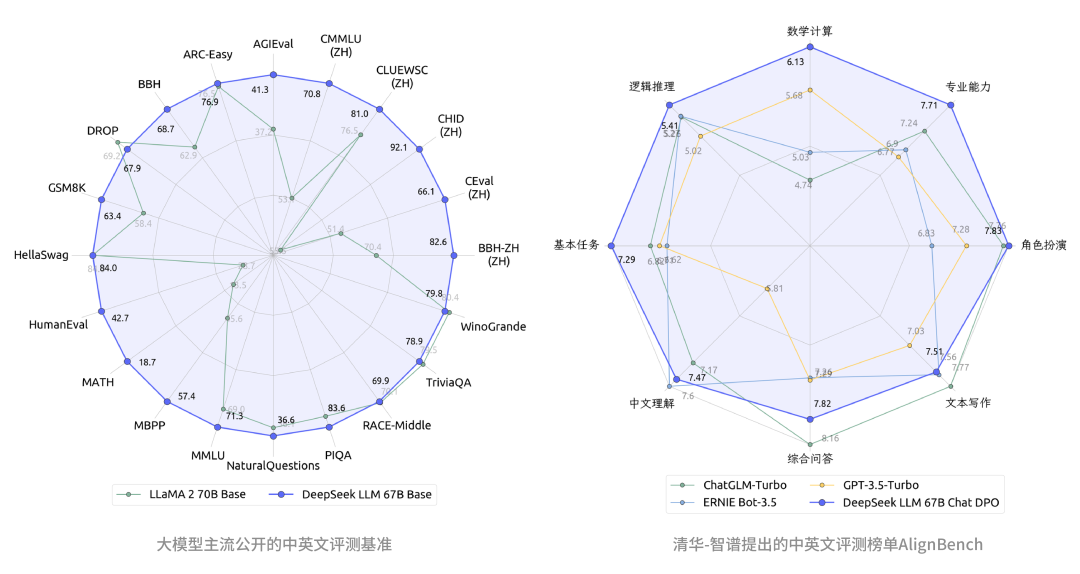
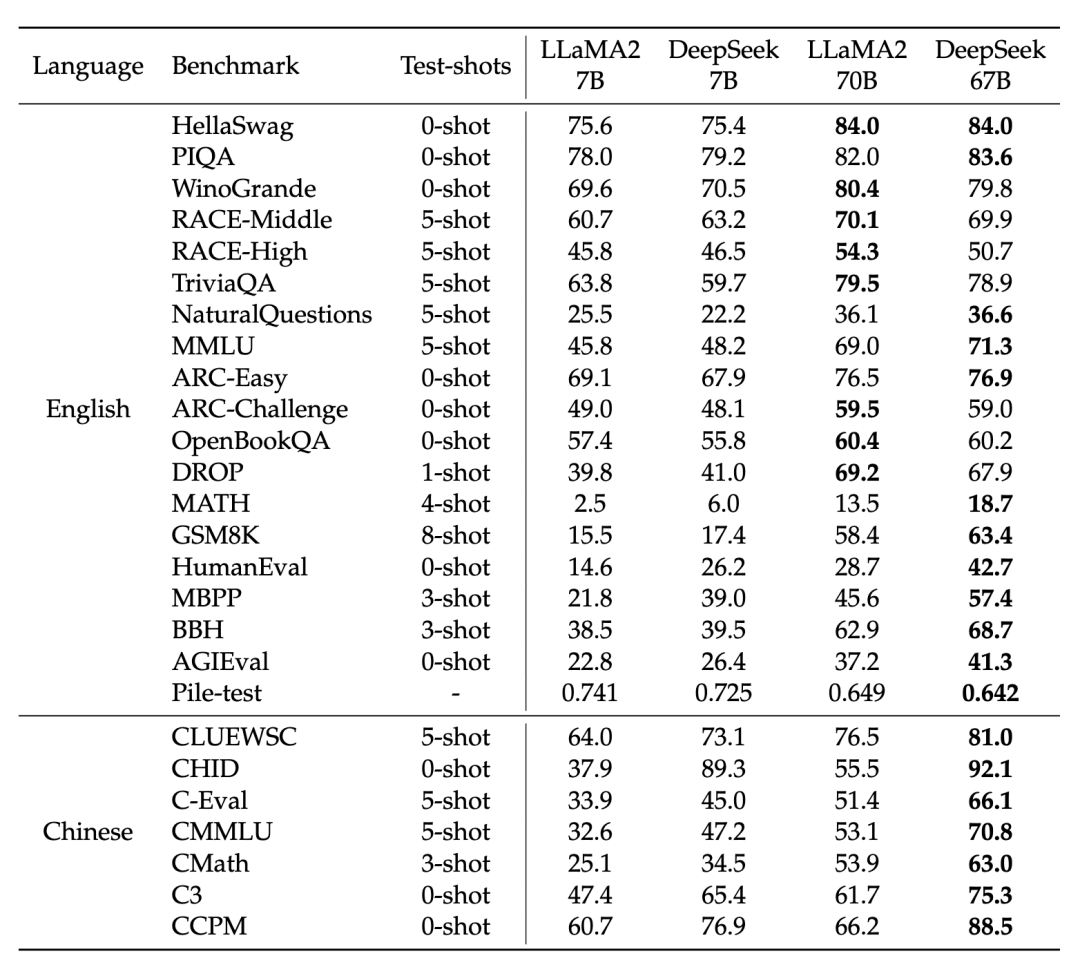
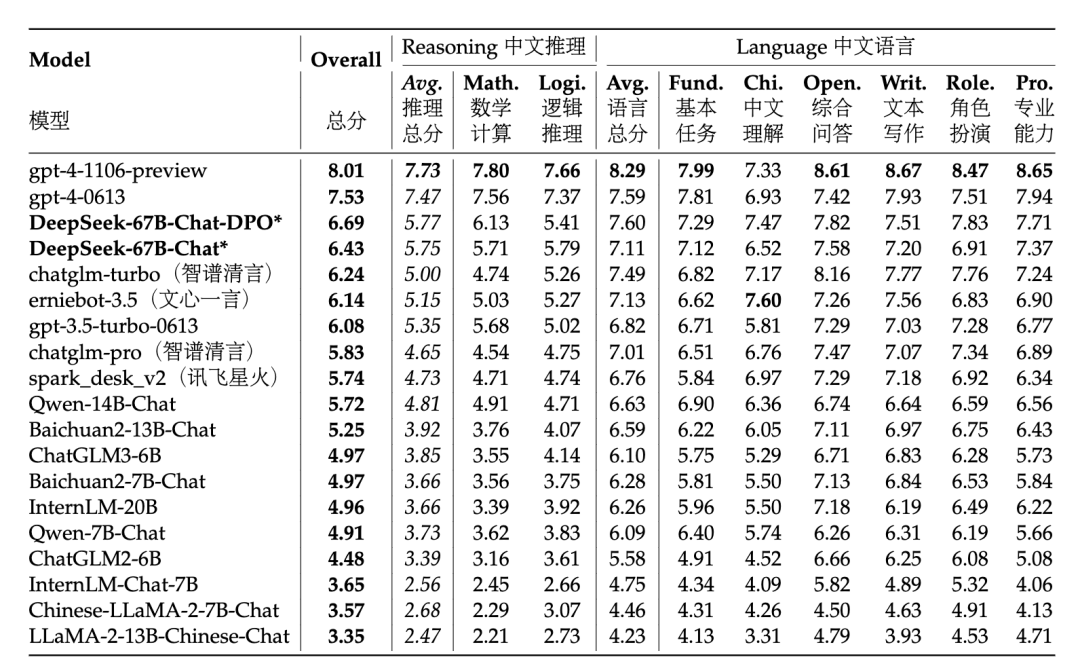
对比开源模型(左图),DeepSeek LLM 67B 的中英文能力已全面超越了开源标杆LLaMA2 70B
-
对比闭源模型(右图),免费开源商用的DeepSeek 67B Chat的中文能力已经超越了GPT-3.5-turbo,并在专业能力、数学计算、基本任务等小幅领先国内大模型
1. 数据&架构
用于预训练DeepSeek LLM的数据有2万亿个中英文词元 (2T Tokens) 。
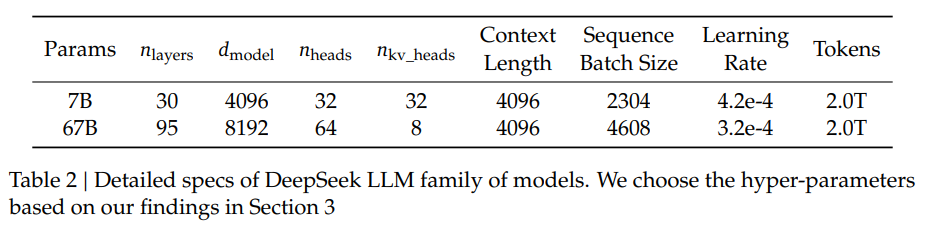
架构主要参照了LLaMA,相同点是: FFN 激活函数为SwiGLU、 归一化函数是RMSNorm、 位置编码使用了RoPE,以及 7B模型采用了MHA(Multi-Head Attention),67B模型则采用了GQA(Grouped-Query Attention)
DeepSeek LLM和LLaMA的架构区别主要是模型深度的不同,DeepSeek 7B是30层,DeepSeek 67B是95层,而LLaMA2 7B和70B则分别是32层和80层。
![]()
2. 训练&Infra
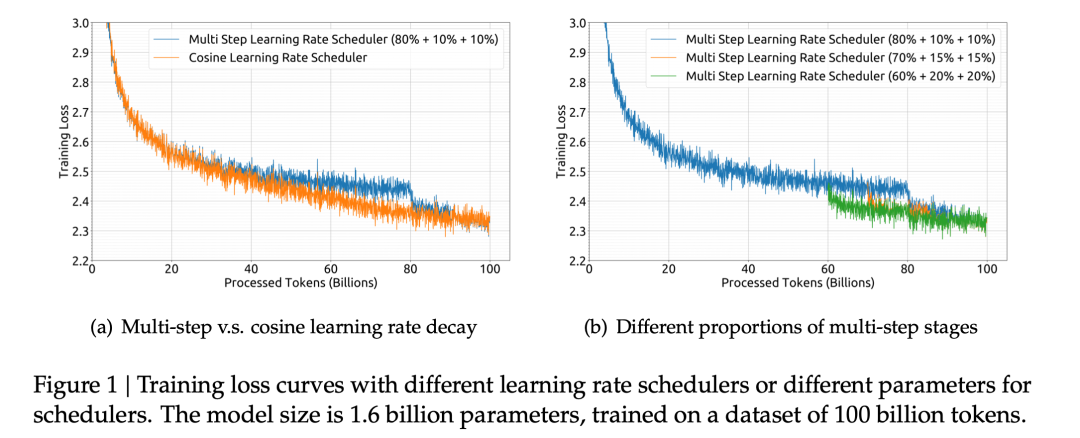
2.1 多阶段学习率调度器
相比较于广泛使用的余弦学习率调度器,我们使用了多阶段学习率调度器,可以方便我们复用第一个训练阶段,在continual training时有独特的优势。我们也通过细致的实验表明,使用多阶段学习率调度器可以获得不弱于余弦学习率调度器的性能。
2.2 Infra
我们使用了内部自研的轻量级高效训练框架HAI-LLM来支持我们训练和评估LLM。我们在训练过程中使用到了数据并行、张量并行、序列并行和1F1B流水线并行等并行策略,并采用了flash attention等加速算子来提高我们的硬件利用率。我们使用bf16来训练模型并使用fp32来累积梯度。
为了确保实验过程中的高效断点恢复,模型的参数和优化器状态会每隔5分钟异步存储一次,这也意味着在面对突发的硬件和网络问题时我们最多只会损失5分钟的训练时间。我们还 支持从不同并行策略中恢复训练 ,保证我们可以灵活的调整训练状态并安排训练进度。
3. Scaling Laws
早期的Scaling Laws研究中呈现出了有差异的结论,对超参数部分的叙述也略显不足 。为了更好的对计算规模进行扩展,找到最优的模型/数据规模分配比例,并对大规模模型训练结果进行预测,我们对Scaling Laws进行了充分的研究。
3.1 超参数的Scaling Laws
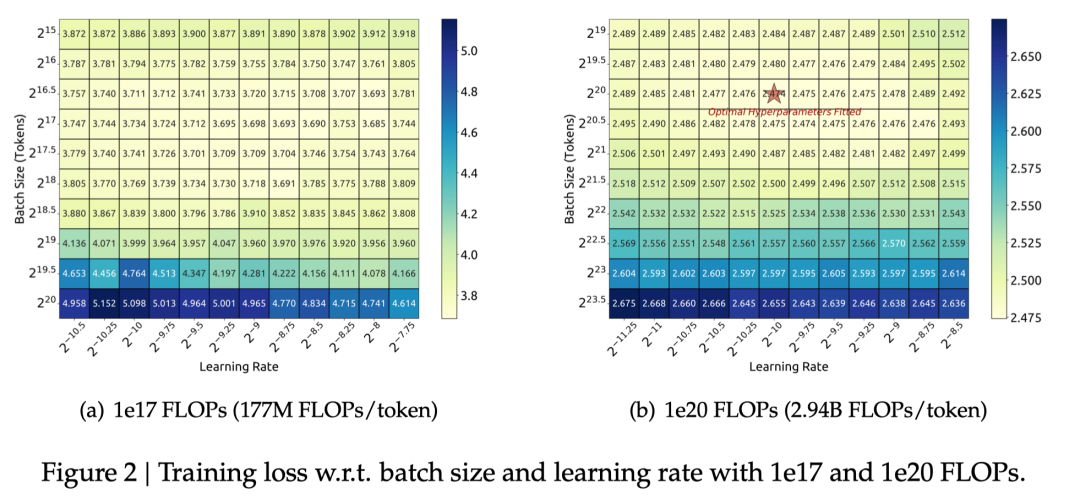
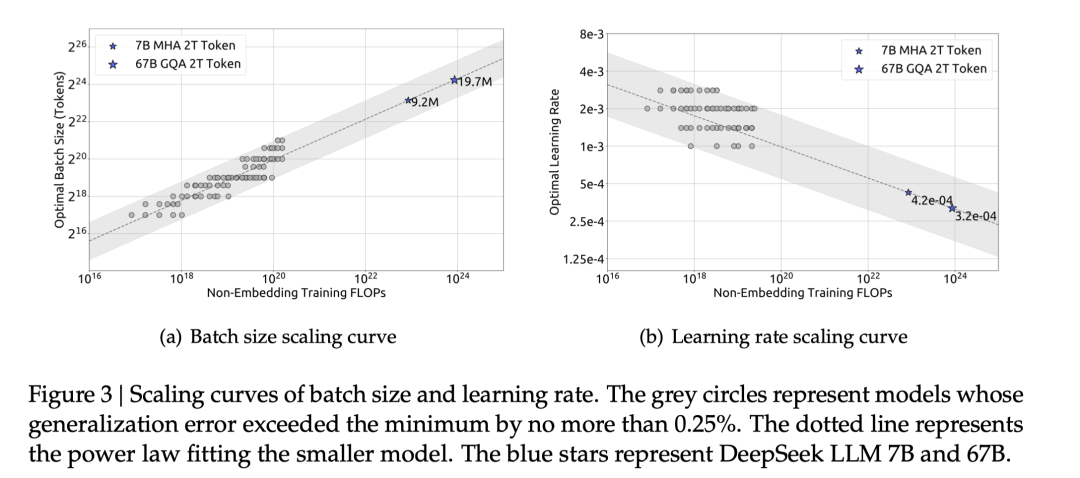
我们首先从超参数入手,尝试寻找超参数层面是否存在随计算规模变化的规律。经过大量实验,我们发现,给定模型规模和数据规模后,模型的batch size和learning rate有一个较大的接近最优参数空间,且这一参数空间随计算规模的变化明显。其余参数则在不同规模下共享同样的最优参数。因此我们将超参数的Scaling Laws限定在batch size和learning rate上进行研究。
我们在1e17到2e19的计算规模上进行了广泛的实验,结果表明最优batch size会随计算规模的增加而上升,最优learning rate则会下降。并且最优参数可以被拟合为相对于计算规模C的幂律曲线上。这一结论帮助我们在给定计算规模后选取最优参数,也为训练DeepSeek LLM 7B和67B打好了基础。
3.2 估计最优模型和数据扩展
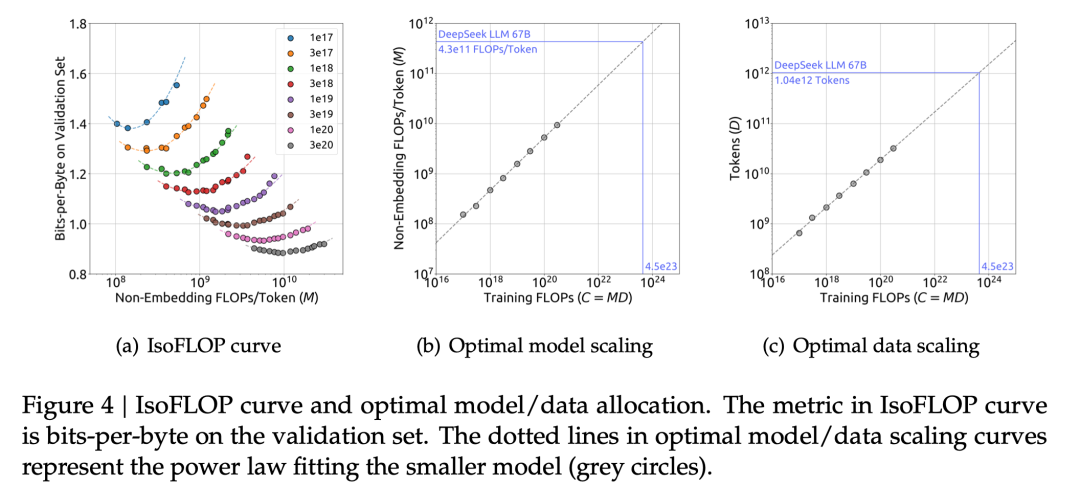
在获得最优超参的经验公式后,我们借助Chinchilla中的IsoFLOP profile方法,对模型和数据的scaling laws进行了探究。为了获得更准确的估计,我们还使用Non-embedding FLOPs/token替换之前scaling laws研究中通常使用的模型参数来表示模型的规模。在此基础上,我们成功拟合出了模型和数据的scaling curve,并得到了模型和数据的最优分配比例。
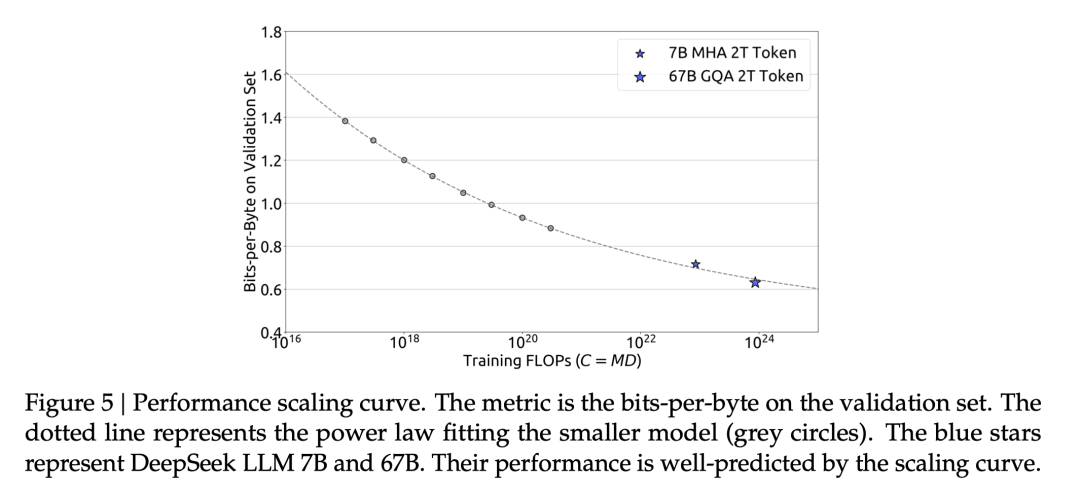
此外,我们还依据IsoFLOP profile中各FLOPs的最优泛化误差拟合了loss的scaling curve,并据此对DeepSeek LLM 7B和67B的泛化误差进行了预测。结果表明,我们通过小规模实验拟合出的loss scaling curve可以较为准确的预测DeepSeek LLM 7B和67B的结果,这为我们后续训练更大规模的模型提供了信心和保障。
![]()
3.3 不同数据下的Scaling Laws
在DeepSeek LLM的开发过程中,我们的数据也经历了多次迭代,在调整数据比例的同时不断提高数据质量。这也让我们有机会探究不同数据对scaling laws的影响。
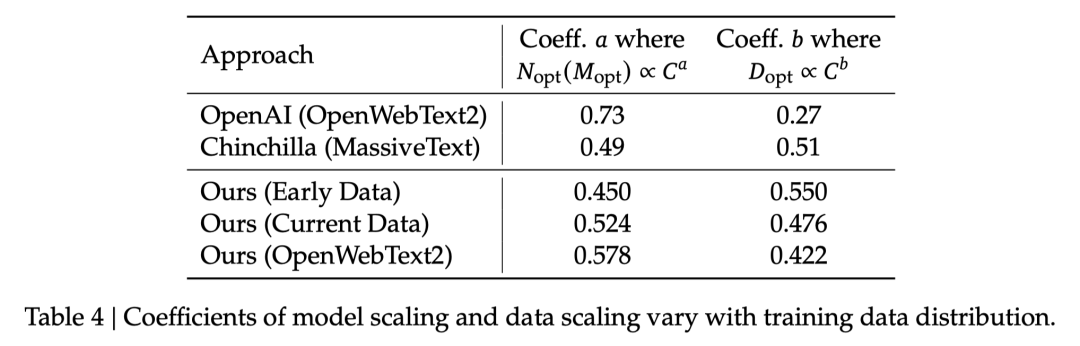
我们在内部早期数据(Early Data),内部现阶段数据(Current Data)和OpenAI scaling laws研究中使用到的OpenWebText2三份数据上分别拟合了scaling curve。
![]()
我们内部的评估表明,OpenWebText2由于规模最小,处理过程最精细,因此拥有最高的数据质量,我们的内部现阶段数据则好于内部早期数据。拟合出的结果则在模型和数据的最优分配比例上显示出了与数据质量的一致性,数据质量越高,分配越偏向模型侧。这也意味着随着数据质量提升,同等数据可以驱动的最优模型规模也会不断增大。
4. 对齐&评估
4.1 方法
在此版DeepSeek的对齐中,方法没有秘密,使用了标准的SFT和DPO进行helpfulness和safety方面的对齐。其中,SFT使用了约一百五十万数据,数据分布比例约为safety数据30万条,helpfulness 120万条。其中,helpfulness的细分占比为46.6%的数学,22.2%的代码,其余为普通文本类对齐数据。
4.2 Helpful评估
我们对模型做了全面的有用性评估,包括一系列的公开评测基准、开放性语言生成、以及一系列从未见过的考试题,客观公平地展现模型语言理解、编程、数学、知识、指令跟随等一系列能力。
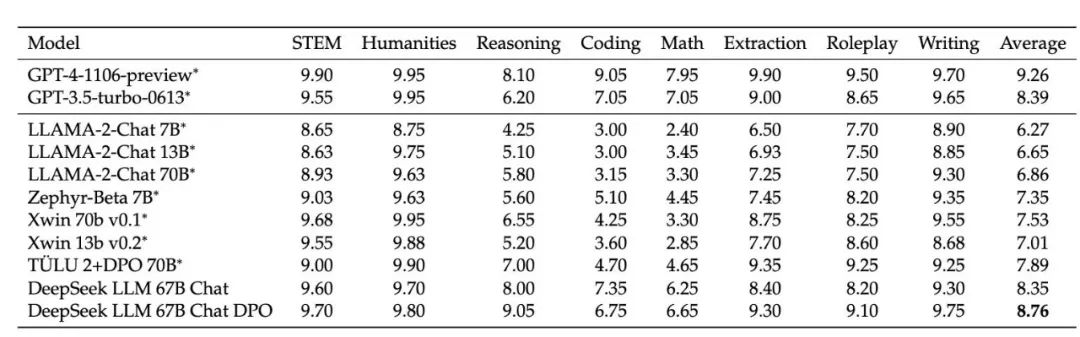
· 公开评测基准:我们采用一系列权威的中英能力评估测试集,对模型能力进行综合评估,DeepSeek 7B与DeepSeek 67B模型均取得了亮眼的成绩。
· 开放性语言生成:在清华-智谱提出的中文AlignBench开放语言生成能力评测集上,DeepSeek模型表现仅次于GPT-4,在中文能力上超过了GPT-4-0613。
在MT-Bench英文评测集上,DeepSeek模型超过了GPT-3.5-turbo,仅次于GPT-4。
4.3 安全评估
除了模型的有用性,我们也高度重视模型的安全性。我们在模型的全训练过程中(包括预训练、SFT和DPO阶段)都进行严格的数据安全性筛选,来保证训练得到的模型是足够符合人类价值观的,并且具有足够的社会亲和性。
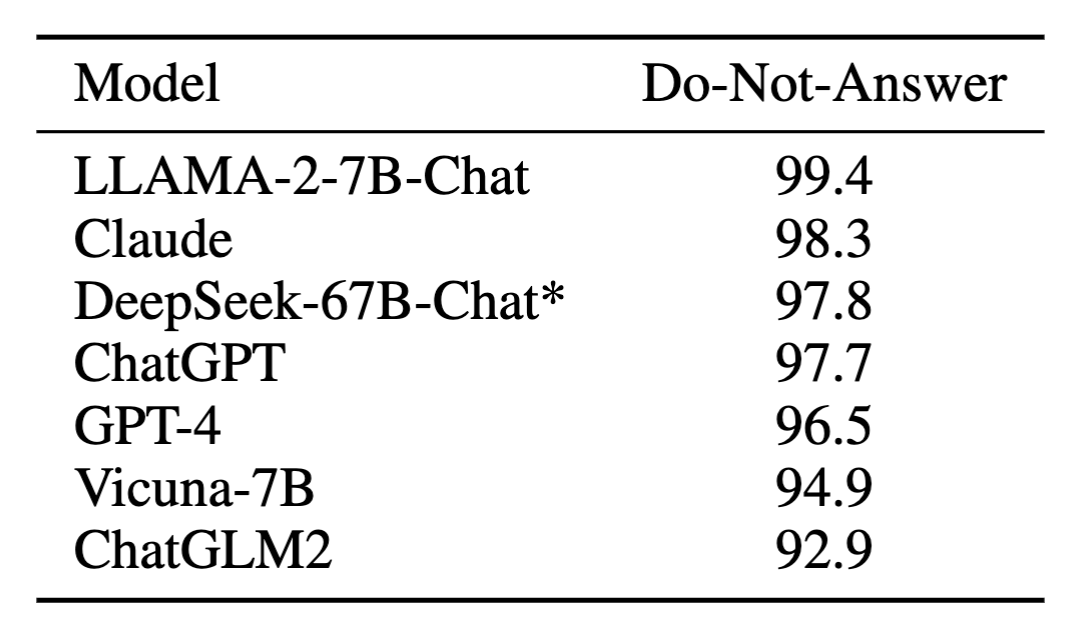
从下方的表格中我们可以看出,DeepSeek-67B-Chat模型的安全性总得分高于ChatGPT和GPT-4,处在最安全的模型队列当中。
4.4 讨论
· 选择题数据对于大模型的影响:加入选择题可以提升模型在一些特定benchmark指标可以说是业界“公开的秘密”。我们在SFT阶段对加入大量选择题进行了尝试,获得了选择题相关测试集(C-Eval,MMLU等)极大的提升,但其他测试集提升微乎其微。所以,加入选择题更像一种“Benchmark Decoration”,为了不过拟合选择题测试集,我们避免在预训练及SFT中加入大量选择题。
· 在预训练阶段加入指令数据:已有工作曾提出,在预训练阶段加入指令数据可以提升模型能力。然而,通过我们的初步试验分析,同样的指令数据在SFT阶段加入也会有相同的效果。所以,这种方法只能让base模型获得更好的看的性能指标,但也限制了SFT阶段微调对于模型的性能的增幅空间。我们在训练中选择只让预训练只见到自然状态下的网页文本,不加入人工指令数据。
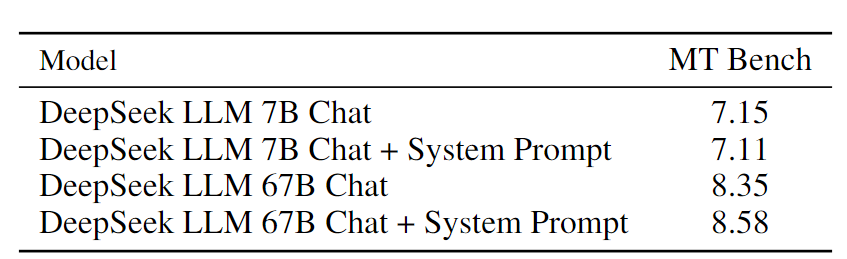
· System Prompt对于模型的影响:一个设计精巧的System Prompt可以让模型更好的和用户进行对话。我们测试了System Prompt对于DeepSeek Chat 模型的影响。我们发现,67B的模型比7B的模型可以更好的理解System Prompt,即使训练中没有见到,实际应用中加入System Prompt可以在MT bench的GPT-4主观测评中获得更高的分数,模型在回复中更加认真了。
欢迎访问: https://hf.co/deepseek-ai
本文由 Hugging Face 中文社区内容共建项目提供,稿件由社区成员投稿,经授权发布于 Hugging Face 公众号。文章内容不代表官方立场,文中介绍的产品和服务等均不构成投资建议。了解更多请关注微信公众号:
如果你有与开源 AI、 Hugging Face 相关的技术和实践分享内容,以及最新的开源 AI 项目发布,希望通过我们分享给更多 AI 从业者和开发者们,请通过下面的链接投稿与我们取得联系: