GaussDB性能调优过程需要综合考虑多方面因素,因此,调优人员应对系统软件架构、软硬件配置、数据库配置参数、并发控制、查询处理和数据库应用有广泛而深刻的理解。
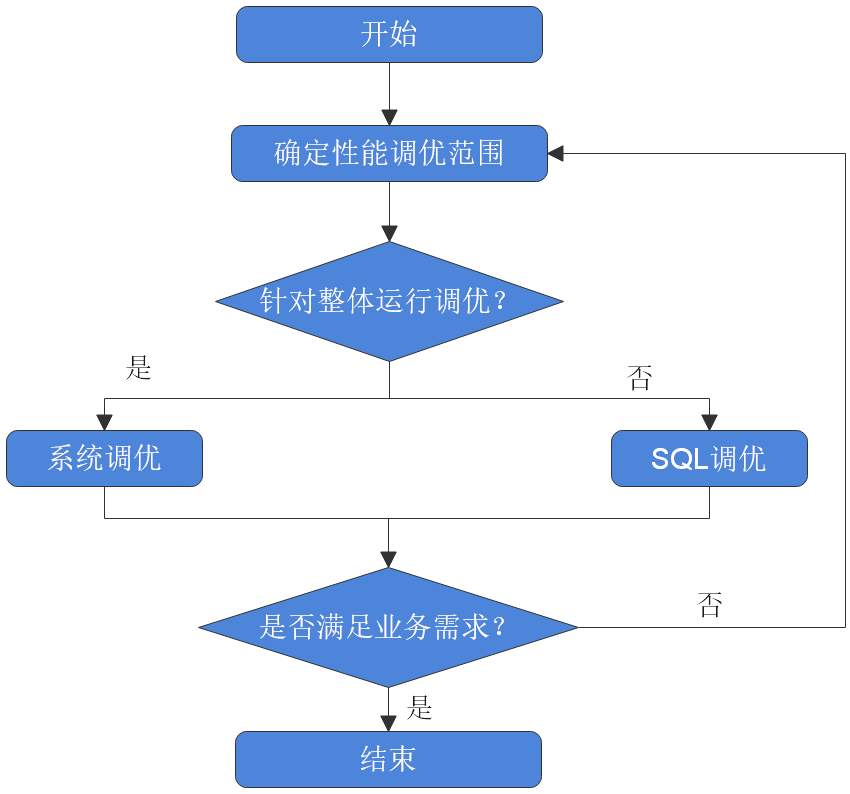
调优流程 ![]()
调优各阶段说明,如下表所示。
![]()
数据库性能调优通常发生在用户对业务的执行效率不满意,期望通过调优加快业务执行的情况下。正如“性能因素”小节所述,数据库性能受影响因素多,从而性能调优是一项复杂的工程,有些时候无法系统性地说明和解释,而是依赖于DBA的经验判断。尽管如此,此处还是期望能尽量系统性的对性能调优方法加以说明,方便应用开发人员和刚接触GaussDB的DBA参考。
性能因素 多个性能因素会影响数据库性能,了解这些因素可以帮助定位和分析性能问题。
系统资源 数据库性能在很大程度上依赖于磁盘的I/O和内存使用情况。为了准确设置性能指标,用户需要了解集群部署硬件的基本性能。CPU,硬盘,磁盘控制器,内存和网络接口等这些硬件性能将显著影响数据库的运行速度。
负载 负载等于数据库系统的需求总量,它会随着时间变化。总体负载包含用户查询,应用程序,并行作业,事务以及数据库随时传递的系统命令。比如:多用户在执行多个查询时会提高负载。负载会显著地影响数据库的性能。了解工作负载高峰期可以帮助用户更合理地利用系统资源,更有效地完成系统任务。
吞吐量 使用系统的吞吐量来定义处理数据的整体能力。数据库的吞吐量以每秒的查询次数、每秒的处理事务数量或平均响应时间来测量。数据库的处理能力与底层系统(磁盘I/O,CPU速度,存储器带宽等)有密切的关系,所以当设置数据库吞吐量目标时,需要提前了解硬件的性能。
竞争 竞争是指两组或多组负载组件尝试使用冲突的方式使用系统的情况。比如,多条查询视图同一时间更新相同的数据,或者多个大量的负载争夺系统资源。随着竞争的增加,吞吐量下降。
优化 数据库优化可以影响到整个系统的性能。在执行SQL制定、数据库配置参数、表设计、数据分布等操作时,启用数据库查询优化器打造最有效的执行计划。
调优范围确定 性能调优主要通过查看集群各节点的CPU、内存、I/O和网络这些硬件资源的使用情况,确认这些资源是否已被充分利用,是否存在瓶颈点,然后针对性调优。
如果某个资源已达瓶颈,则: 检查关键的操作系统参数和数据库参数是否合理设置。
通过查询最耗时的SQL语句、跑不出来的SQL语句,找出耗资源的SQL,进行SQL调优指南。
如果所有资源均未达瓶颈,则表明性能仍有提升潜力。可以查询最耗时的SQL语句,或者跑不出来的SQL语句,进行针对性的SQL调优指南。 GaussDB如何进行SQL调优 数据库使用过程中,SQL调优是提升数据库性能的重点。SQL调优的唯一目的是“资源利用最大化”,即CPU、内存、磁盘IO、网络IO四种资源利用最大化。所有调优手段都是围绕资源使用开展的。所谓资源利用最大化是指SQL语句尽量高效,节省资源开销,以最小的代价实现最大的效益。本章介绍典型的SQL调优的方法和案例。
调优流程 对慢SQL语句进行分析,通常包括以下步骤:
- 收集SQL中涉及到的所有表的统计信息。在数据库中,统计信息是规划器生成计划的源数据。没有收集统计信息或者统计信息陈旧往往会造成执行计划严重劣化,从而导致性能问题。从经验数据来看,10%左右性能问题是因为没有收集统计信息。具体请参见更新统计信息。
通过查看执行计划来查找原因。如果SQL长时间运行未结束,通过EXPLAIN命令查看执行计划,进行初步定位。如果SQL可以运行出来,则推荐使用EXPLAIN ANALYZE或EXPLAIN PERFORMANCE查看执行计划及实际运行情况,以便更精准地定位问题原因。有关执行计划的详细介绍请参见SQL执行计划介绍。
-
审视和修改表定义。
-
针对EXPLAIN或EXPLAIN PERFORMANCE信息,定位SQL慢的具体原因以及改进措施,具体参见典型SQL调优点。
-
通常情况下,有些SQL语句可以通过查询重写转换成等价的,或特定场景下等价的语句。重写后的语句比原语句更简单,且可以简化某些执行步骤达到提升性能的目的。查询重写方法在各个数据库中基本是通用的。经验总结:SQL语句改写规则介绍了几种常用的通过改写SQL进行调优的方法。
典型调优案例 选择合适的分布列 现象描述:
表定义如下: CREATE TABLE t1 (a int, b int); CREATE TABLE t2 (a int, b int);
执行如下查询:
SELECT * FROM t1, t2 WHERE t1.a = t2.b;
优化分析:
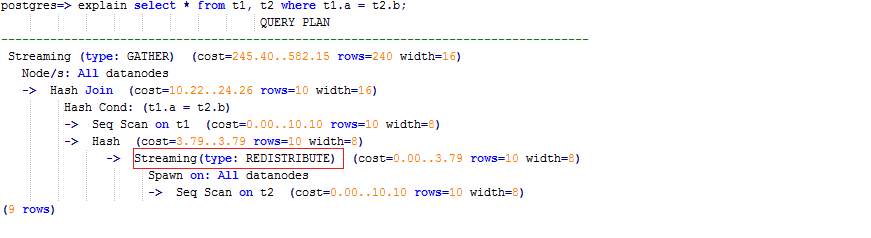
如果将a作为t1和t2的分布列:
CREATE TABLE t1 (a int, b int) DISTRIBUTE BY HASH (a); CREATE TABLE t2 (a int, b int) DISTRIBUTE BY HASH (a);
则执行计划将存在“Streaming”,导致DN之间存在较大通信数据量。
![]()
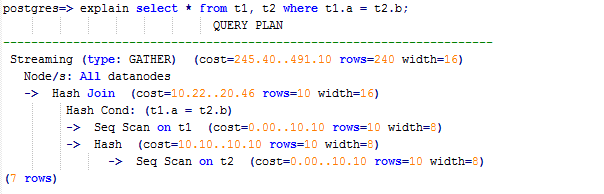
如果将a作为t1的分布列,将b作为t2的分布列:
CREATE TABLE t1 (a int, b int) DISTRIBUTE BY HASH (a); CREATE TABLE t2 (a int, b int) DISTRIBUTE BY HASH (b);
则执行计划将不包含“Streaming”,减少DN之间存在的通信数据量,从而提升查询性能。
![]()
建立合适的索引。 现象描述:
查询与销售部所有员工的信息:
SELECT staff_id,first_name,last_name,employment_id,state_name,city FROM staffs,sections,states,places WHERE sections.section_name='Sales' AND staffs.section_id = sections.section_id AND sections.place_id = places.place_id AND places.state_id = states.state_id ORDER BY staff_id;
优化分析:
建议在places.place_id和states.state_id列上建立2个索引。
今天的分享就到这里啦,欢迎小伙伴交流。