一、前言 SQL是用于访问和处理数据库的标准计算机语言。GaussDB支持的SQL标准(默认支持SQL2、SQL3和SQL4的主要特性)。
本系列将以《云数据库GaussDB—SQL参考》为主线进行介绍。
二、GaussDB SQL 中的BOOLEAN表达式介绍 1、概念 在GaussDB数据库中,BOOLEAN表达式是一种很常见的表达式类型,它用于比较两个条件,来确定其是否为真或假。BOOLEAN表达式可以用于条件判断或在循环语句中作为终止条件。其语法非常简单,只需要使用逻辑运算符对两个条件进行比较。GaussDB SQL支持AND、OR等逻辑运算符,这些运算符可以将结果组合成更复杂的布尔表达式。
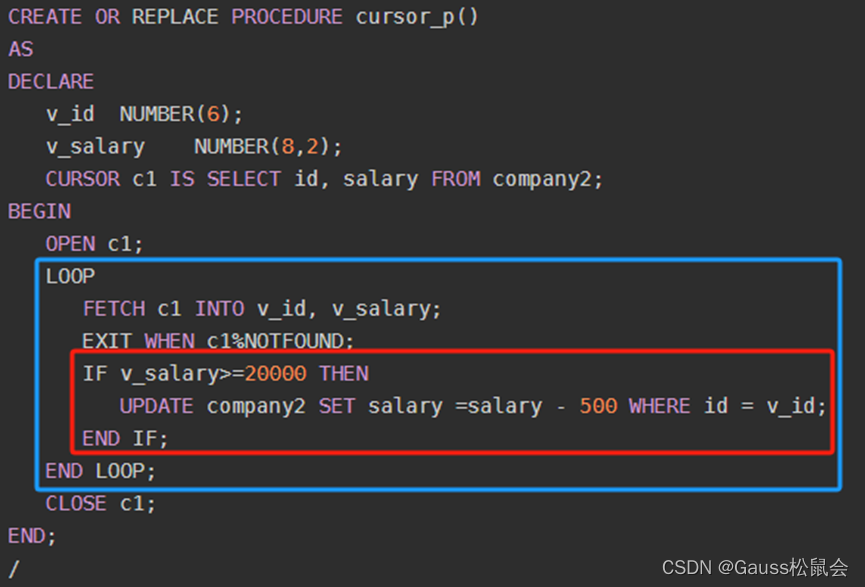
2、组成 运算符:比较运算符(如=、<>、<、>、<=、>=)和逻辑运算符(如AND、OR、NOT等)。 操作数:用于比较的字段值或常量。 3、语法示例 如下截图是游标使用中的SQL部分,SQL中涉及到BOOLEA表达式用于条件判断和循环语句部分,可参考:
![]()
1)条件判断,见红色方框
“v_salary>=20000”,在这个例子中,当v_salary >= 20000 时,则执行THEN 后面的 UPDATE语句。
2)循环语句,见蓝色方框
“%NOTFOUND”,是游标的属性之一,用于控制程序流程或者了解程序的状态。当最近的DML(数据操作语言)操作(如INSERT,UPDATE,DELETE等)没有影响任何行时,该属性为真。'EXIT WHEN c1%NOTFOUND;' 就会执行。
三、在GaussDB SQL中的基础应用 使用布尔表达式可以根据特定条件对结果进行过滤,只返回满足条件的数据。以下是一些在SELECT列表中使用布尔表达式的示例。
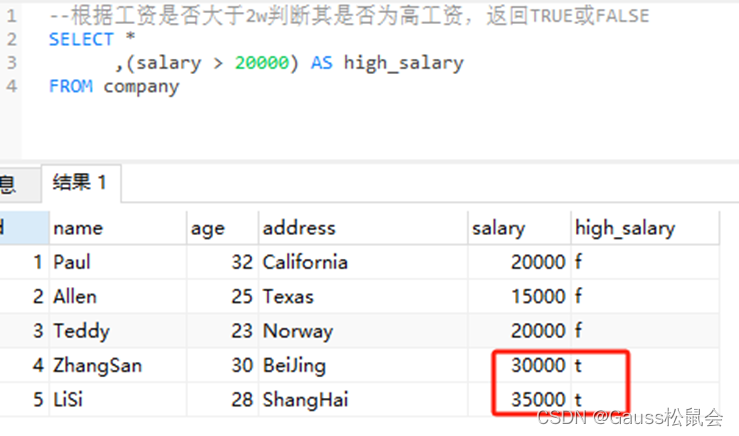
1、示例1,使用比较运算符 --根据工资是否大于2w判断其是否为高工资,返回TRUE或FALSE
`SELECT *
,(salary > 20000) AS high_salary
FROM company;`
![]()
![]()
上述SQL示例中,我们从company表中选择name、age、address、salary和一个布尔表达式(salary > 20000),该表达式用于判断员工的工资是否高收入。 结果集中的high_salary列将显示布尔值TRUE或FALSE。
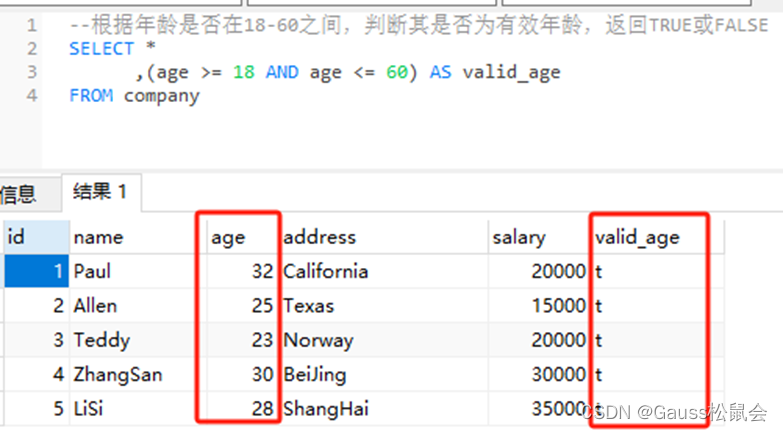
2、示例2,使用逻辑运算符 --根据年龄是否在18-60之间,判断其是否为有效年龄,返回TRUE或FALSE
SELECT *
,(age >= 18 AND age <= 60) AS valid_age
FROM company;
![]()
![]()
上述SQL示例中,我们从company表中选择name、age、address、salary和一个布尔表达式(age >= 18 AND age <= 60),该表达式用于判断员工的年龄是否有效。 结果集中的valid_age列将显示布尔值TRUE或FALSE。
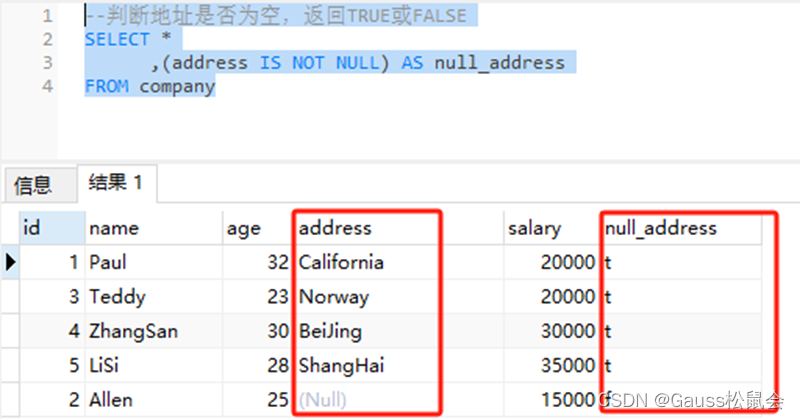
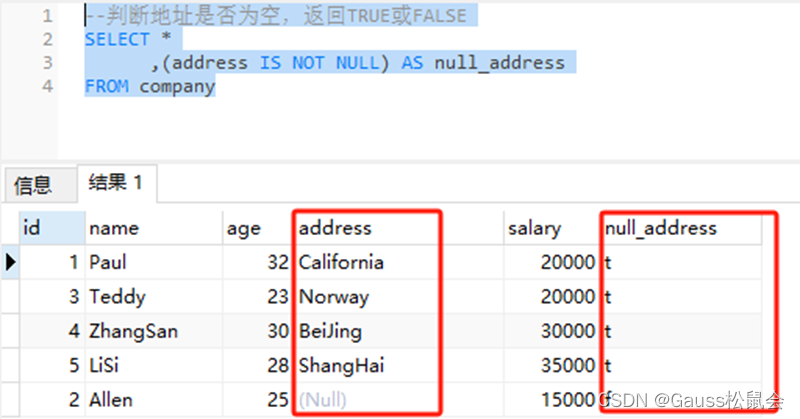
3、示例3,使用IS NOT NULL运算符 --判断地址是否为空,返回TRUE或FALSE
SELECT *
,(address IS NOT NULL) AS null_address
FROM company;
![]()
![]()
上述SQL示例中,我们从company表中选择name、age、address、salary和一个布尔表达式(address IS NOT NULL),该表达式用于判断员工的地址是否为空值。 结果集中的null_address列将显示布尔值TRUE或FALSE。
4、示例4,使用like模式匹配操作符 LIKE:判断字符串是否能匹配上LIKE后的模式字符串。如果字符串与提供的模式匹配,则LIKE表达式返回为真(NOT LIKE表达式返回假),否则返回为假(NOT LIKE表达式返回真)。
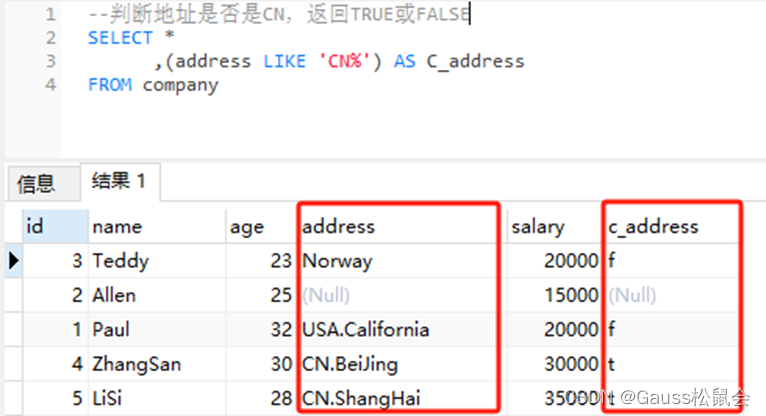
--判断地址是否是CN,返回TRUE或FALSE
SELECT *
,(address LIKE 'CN%') AS c_address
FROM company;
![]()
![]()
上述SQL示例中,我们从company表中选择name、age、address、salary和一个布尔表达式(address LIKE 'CN%'),该表达式用于判断员工的地址是否在CN。 结果集中的c_address列将显示布尔值TRUE或FALSE。
附:在GaussDB SQL中还有一个模式匹配操作符SIMILAR TO。
描述:SIMILAR TO操作符根据自己的模式是否匹配给定串而返回真或者假。他和LIKE非常类似,只不过他使用SQL标准定义的正则表达式理解模式。
四、小结 BOOLEAN表达式在SQL中非常常用,它们允许开发人员构建逻辑语句,这些语句能够对表中的数据进行复杂的过滤和选择。通过使用布尔表达式,查询结果可以缩小到满足特定条件的行,或者可以根据这些条件对数据进行聚合和分组。
总之,布尔表达式可以帮助我们进行逻辑判断和循环控制,提高代码的可读性。 熟练掌握BOOLEAN表达式的使用,在GaussDB SQL等开发过程中非常重要。
——结束