Milvus 已支持 Upsert、 Kafka Connector、Airbyte!
在上周的文章中《登陆 Azure、发布新版本……Zilliz 昨夜今晨发生了什么?》,我们已经透露过 Milvus(Zilliz Cloud)为提高数据流处理效率, 先后支持了 Upsert、 Kafka Connector、Airbyte,而这些功能的作用都是简化数据处理和集成流程,为开发人员提供更高效的工具来管理复杂的数据,今天我们将向大家一一介绍。
01.Upsert:简化数据更新流程
Upsert 功能上线以前,在 Milvus 中的更新数据需要两个步骤:删除数据,然后再插入新数据。虽然这种方法也可行,但无法确保数据原子性,且操作过于繁琐。Milvus 2.3 版本发布了全新的 Upsert 功能。(Zilliz Cloud 海外版也已上线 Upsert 功能 Beta版)。
可以说,Upsert 功能重新定义了数据更新和管理方式。使用 Upsert 时,Milvus 会判断数据是否已经存在。如果数据不存在则插入数据,如果已存在则更新数据。这种具有原子性的方法对 Milvus 这样单独管理插入和删除数据的系统中尤为重要。
Upsert 具体的顺序为:先插入数据,然后删除重复数据。这样可以确保了操作期间的数据仍然可见。
此外,Upsert 功能还特别考虑了修改主键的场景。在数据更新过程中无法更改主键列。这与 Milvus 根据主键哈希跨分片(shard)管理数据的原则一致。这种限制避免了跨 Shard 操作带来的复杂性和潜在的数据不一致性。
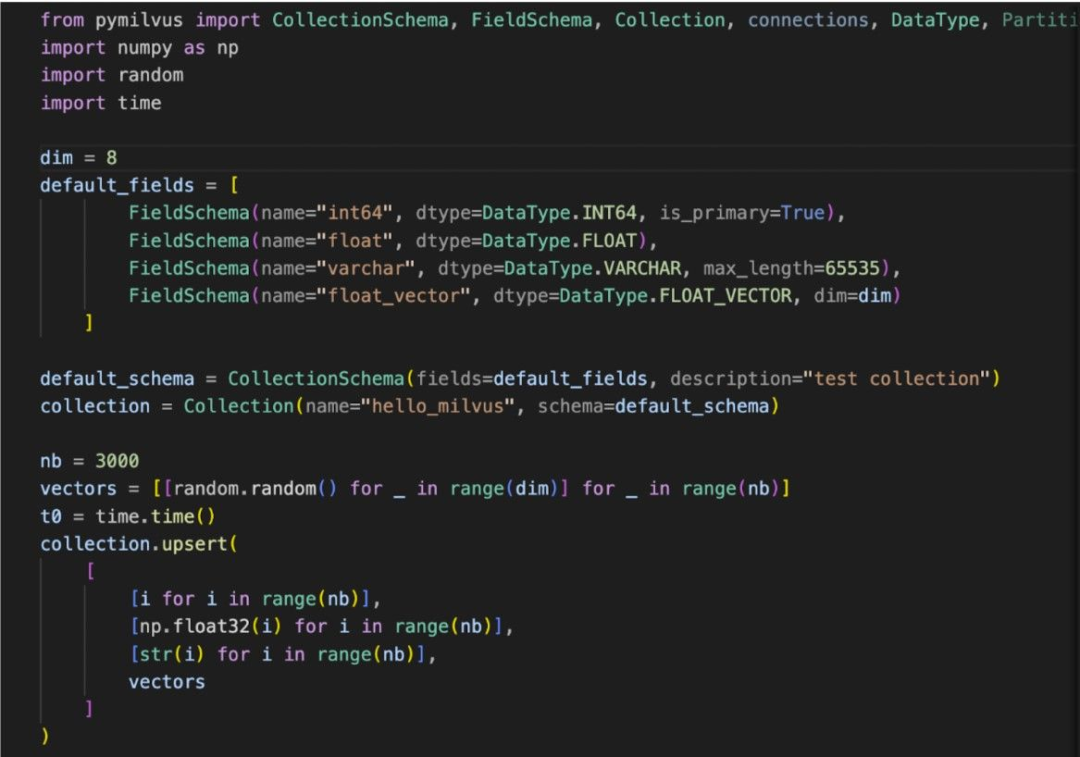
Upsert 使用方法简单,类似于插入操作。用户可以轻松将 Upsert 集成到现有的工作流程中,无需对原有流程进行大改。在 Pymilvus 等 SDK 中,Upsert 命令调用和插入命令完全一致。熟悉 Milvus 的用户使用起来没有任何难度,可以获得一致和丝滑的用户体验。
![]()
执行命令时,Upsert 会提供关于操作成功与否以及受影响的数据的反馈,进一步增加了开发者的使用便利性。这种易于使用且稳定的功能能够助力数据管理。更多详情,请查看 Upsert 文档。
但是使用 Upsert 功能时还需要考虑以下两点:
-
AutoID 限制:使用 Upsert 功能的前提条件是将 AutoID 设置为 false。如果 Collection Schema 中将 AutoID 设置为 true,则无法执行 Upsert 操作。我们设置了这个限制的主要考量是,Upsert 也包含数据更新操作,更新的数据需要有新的主键值。如果用户提供的主键值与 AutoID 自动生成的主键值发生冲突,那可能会导致数据被覆盖。所以,已经开启了 AutoID 的 Collection 不可使用 Upsert 功能。后续新版本中我们可能会取消这一限制。
-
性能开销:Upsert 可能会导致性能成本。Milvus 使用 WAL 架构,过多删除操作可能会导致性能下滑。Milvus 中的删除操作不会立即清除数据,而是为数据打上删除标记。随后在数据压缩过程中才会根据这些标记真正清除数据。因此,频繁的删除操作可能会导致数据膨胀,影响性能。我们建议不要太过于频繁地使用 Upsert 功能,以确保最佳性能。
02.Kafka Connector:赋能实时数据处理
近期,Milvus 和 Zilliz Cloud 接入了 Kafka Sink Connector,向量数据可以无缝丝滑地通过 Confluent/Kafka 实时导入 Milvus 或 Zilliz Cloud 向量数据库中。本次集成能够进一步释放向量数据库潜能,助力实时生成式 AI 应用,尤其是使用 OpenAI GPT-4 这种大模型的场景。
如今,我们所获取的信息中,非结构化数据已占据 80% 以上,且这类数据还在呈爆炸式增长。Zilliz 与 Confluent 的合作标志着非结构化数据管理和分析的重大进步,我们能够更高效存储、处理实时向量数据流,将其转化为易于搜索的数据。
Kafka Connector + Milvus / Zilliz Cloud 的常见用例包括:
增强生成式 AI:为 GenAI 应用提供最新的向量数据,从而确保生成的准确性和及时性。这两点对于金融和媒体等领域尤为重要,因为都需要实时处理各种来源的流式数据。
优化电商推荐系统:电商平台需要实时根据库存和客户行为动态调整其推荐商品或内容以提升用户体验。
在 Zilliz Cloud 中使用 Kafka Connector 的步骤也十分简单:
-
从 GitHub 或 Confluent Hub 下载 Kafka Sink Connector。
-
配置 Confluent 和 Zilliz Cloud 账号。
-
阅读在 GitHub 仓库中提供的指南并配置 Kafka Connector。
-
运行 Kafka Connector,将实时流数据导入 Zilliz Cloud。
如需更深入了解如何设置 Kafka Connector 和相关用例,请前往 GitHub 仓库或访问此网页。
03.集成 Airbyte:数据处理更高效
近期,Milvus 与 Airbyte 团队合作,在 Milvus 中集成 Airbyte,增强了大语言模型(LLM)和向量数据库中的数据获取和使用流程。本次集成能增强开发者存储、索引和搜索高维向量数据的能力,大大简化生成式聊天机器人和产品推荐等应用搭建流程。
本次集成的主要亮点包括:
-
数据传输更高效:Airbyte 能够无缝将数据从各种来源传输到 Milvus 或 Zilliz Cloud,即时将数据转化为 Embedding 向量,简化了数据处理流程。
-
搜索功能更强大:此次集成增强了向量数据库的语义搜索能力。基于 Embedding 向量,系统可以自动识别并搜索出语义相似性高的相关内容,能够为需要高效检索非结构化数据的应用赋能。
-
设置过程更简单:设置 Milvus 集群和配置 Airbyte 同步数据的步骤十分简单。如果需要使用 Streamlit 和 OpenAI Embedding API 构建应用也是同样的设置步骤。
此次集成简化了数据传输和处理,释放实时 AI 应用的无限可能性。例如,在客户支持系统中,使用 Milvus 或 Zilliz Cloud 集成 Airbyte 可以创建基于语义搜索的智能技术支持工单系统,从而为用户提供即时、有用的信息,减少人工干预,提升用户体验。
Zilliz 始终致力于提升非结构化数据管理和处理能力和技术,本次推出的 Upsert、Kafka Connector、Airbyte 等工具的集成都展现了这一点。后续,我们将进一步优化数据获取和数据 Pipeline 功能,敬请期待!