前言
基于现代服务的云原生十二要素理论,我们在采用容器化部署时,要保证同一个镜像可以满足不同环境的部署要求,而不是不同环境打包不同的景象。本文档主要介绍一种基于spring框架的满足不同环境配置的编译打包方案,满足同一个镜像可以在环境分组下通过启动项配置实现不同环境的部署。
现有方案及问题
我们见过最常见的配置文件管理方案,是基于Maven的profile配置来实现多环境切换的,它的弊端在于,我们将profile配置在pom.xml中,每次编译打包时,需要通过编译指令-P来标识当前环境配置。这样导致的问题是,我们打包的镜像具有了环境属性,不符合一个镜像多环境部署的要求。
还有一种配置方案,就是基于Spring profile进行配置文件管理。针对这两种方案,我接下来会进行一些分析和对比。
两种profiles配置的不同和优劣对比
a. 两种profiles方案对比
1. Maven 的 profiles:
◦ Maven 的 profiles 是在构建时根据环境或其他条件激活不同的配置集合。可以在项目的pom.xml文件中定义多个 profile,并使用 Maven 命令行参数或其他配置来激活特定的 profile。
◦ 优势:
▪ 灵活性高,可以根据不同的构建环境或条件激活不同的 profile。
▪ 可以在构建过程中使用不同的依赖、插件配置等。
◦ 劣势:
▪ 配置相对分散,需要在 Maven 的pom.xml文件中定义和管理多个 profile。
▪ 配置与代码分离,不够直观。
2. Spring 的application.properties的 profile 配置:
◦ Spring 的application.properties文件可以根据激活的 profile 来加载不同的配置。可以在application.properties文件中定义多个 profile 下的配置,并使用配置文件或环境变量来激活特定的 profile。
◦ 优势:
▪ 配置集中,可以在一个文件中定义多个 profile 下的配置,更易于管理和维护。
▪ 配置与代码相近,更直观易读。
◦ 劣势:
▪ 激活 profile 的方式相对有限,通常需要通过配置文件或环境变量来指定。
▪ 不适用于构建过程中的配置,主要用于应用程序的运行配置。
总的来说,Maven profiles 更适用于构建过程中的配置,可以根据构建环境或条件激活不同的 profile,而 Spring 的application.properties的 profile 配置更适用于应用程序的运行配置,可以根据不同的 profile 加载不同的配置。具体选择哪种方式取决于你的需求和偏好。
b. 在云原生和容器化的部署场景分析
在云原生和容器化的部署场景下,我更倾向使用 Spring 的application.properties的 profile 配置方式。
以下是在云原生和容器化部署场景下,使用application.properties的 profile 配置方式的优势:
- 环境无关性:
application.properties可以根据激活的 profile 加载不同的配置,使得应用程序在不同的环境中运行时具有一致的行为。这对于云原生和容器化的部署非常重要,因为应用程序可能需要在不同的环境(例如开发、测试、生产)中运行。
- 配置集中化:使用
application.properties的 profile 配置方式,可以在一个文件中定义多个 profile 下的配置,使得配置管理更加集中和方便。这对于云原生和容器化的部署场景非常有帮助,因为可以根据不同的 profile 加载适当的配置,而无需分散地管理多个 Maven profiles。
- 容器友好性:在容器化的部署场景中,通常使用容器编排工具(如 Kubernetes)来管理应用程序的配置和部署。使用
application.properties的 profile 配置方式,可以通过环境变量或配置文件中的属性来指定激活的 profile,从而实现与容器编排工具的集成。
综上所述,使用 Spring 的 application.properties 的 profile 配置方式更适合云原生和容器化的部署场景,因为它提供了环境无关性、配置集中化和容器友好性的优势。
基于properties的多环境配置方案实践
以下方案以springboot为例,当然springMVC方案也是可以适配,只是需要额外配置一下,介于我们新项目基本都是基于springboot搭建,此处不展开springMVC的实线方案,如有需要,我再额外提供mvc的配置方案。
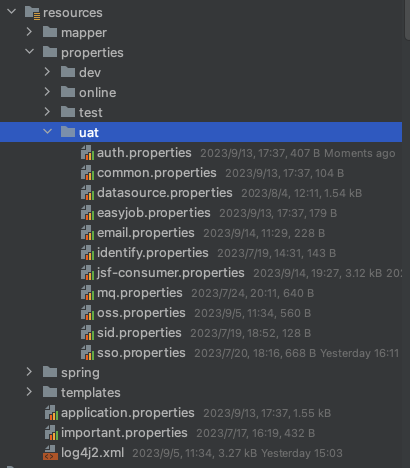
a. 配置文件树
如上图所示
- properties文件夹:我们在properties文件夹下,基于不同的环境,简历单独文件夹,比如dev,online, test, uat等,每个文件夹下存放当前环境的配置信息。
- spring文件夹: 下存放xml配置信息,比如常见的JSF配置(jsf.xml),以及其他需要通过xml配置注入的业务场景。当然基于springboot官网建议,大家尽量用注解代码方式实现bean注入,尽量减少xml的方式。
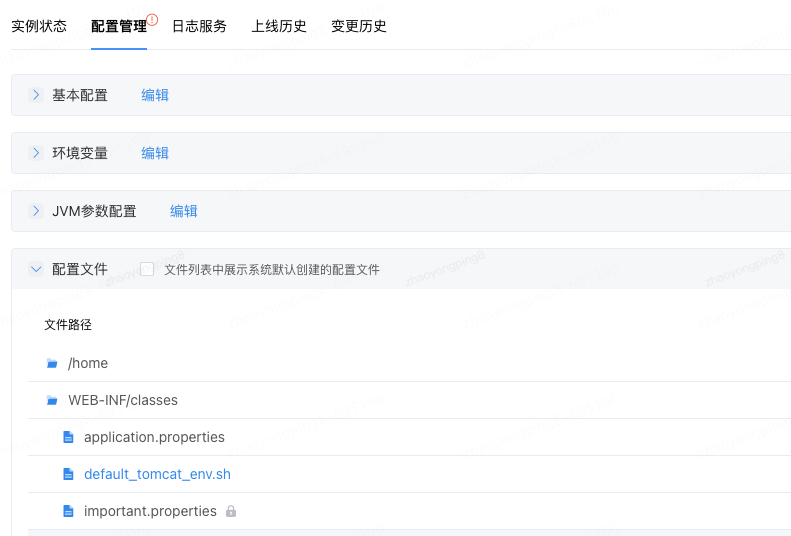
- application.properties文件: 该文件里通过核心的配置spring.profiles.active=**来标识当前是哪个profile环境。当然一些其他全局类配置也可以放在此处。需要注意application.properties文件需要配置在行云部署中分组配置里,因为此文件需要基于不同的部署分组进行文件覆盖,以改变spring.profiles.active的值,如下图所示。当然,也可以通过运行时启动指令,进行不同的profile选择。
- important.properties文件: 该文件为京东行云部署规约,把秘钥等安全性高的文件以加密存储的方式存放在该文件中,并部署到行云部署分组的远程配置里。
具体行云部署里的配置如下:
b. properties文件加载
正常情况下,properties/**/*.properties下的配置文件是不会自动加载到启动项里的。所以需要通过额外的方式动态加载,具体方法是通过spring框架下的PropertySourcesPlaceholderConfigurer的类属性,结合环境变量,动态批量加载配置文件。(额外说明,如果是springMVC框架,也可以通过xml配置context:property-placeholder属性来实现。)
具体代码如下:
/**
* 配置文件环境配置
*
* @Author zhaoyongping
* @date 2023/7/10 15:13
* @ClassName EnvPropertiesConfig
* @Descripiton 配置文件环境配置
**/
@Configuration
public class EnvPropertiesConfig {
/**
* 加载属性配置
*
* @param environment 环境属性
* @return PropertySourcesPlaceholderConfigurer
* @author zhaoyongping
* @date 2023/7/10 15:13
* @description 加载属性配置
*/
@Bean
public static PropertySourcesPlaceholderConfigurer propertySourcesPlaceholderConfig(Environment environment) throws IOException {
PropertySourcesPlaceholderConfigurer config = new PropertySourcesPlaceholderConfigurer();
String[] activeProfiles = environment.getActiveProfiles();
if (activeProfiles.length > 0) {
String resourceUrl = "classpath:properties/"
+ environment.getActiveProfiles()[0] + "/*.properties";
config.setLocations(
new PathMatchingResourcePatternResolver().getResources(resourceUrl));
} else {
//兜底策略
config.setLocations(
new PathMatchingResourcePatternResolver()
.getResources("classpath:properties/dev/*.properties"));
}
return config;
}
}
总结
通过以上步骤,我们可以实现编译打包镜像不需要跟环境变量绑定,而只需要在启动运行时基于不同的分组动态配置的applicaiton.properties文件,来实现不同环境的适配。这种可以在运行时变更配置文件的机制,更适合在云原生时代下的容器化部署方案,也利于我们的服务的可移植性。当然,以上只是笔者个人的一个实践经验,并不能代表它是最优实践方案。
作者:京东物流 赵勇萍
来源:京东云开发者社区 自猿其说Tech 转载请注明来源