![file]()
背景介绍
为什么我们考虑构建统一的调度平台? 主要原因是:我们公司的大数据中心目前拥有七个大数据集群,这些集群分布在不同的机房,例如内蒙、南京、苏州和广州。而且,这些机房之间的网络并不互通。如果每个集群都独立部署调度系统,将会有多套调度服务管理入口,这对于运维和开发者,无论维护和使用上来说都非常不便。因此,我们决定构建一个统一调度平台,集中管理多个集群的调度任务,也为我们后续深度平台集成提供契机。
构建经验
网络通讯: 之前我们的DolphinScheduler是基于单一机房的内网通讯。然而,考虑到我们的集群遍布多个省份,我们需要对其进行改造,使其支持跨机房通过公网通讯,而考虑降低网络延迟的影响,同一机房内的节点仍然希望服务之间内网通讯。为了保证数据的安全性,我们还为公网通讯配置了TLS加密。
权限管理: 由于我们需要管理多套集群,因此会遇到多集群权限的问题。我们优化DolphinScheduler的工作组功能来管理不同的集群环境,并为不同集群环境和租户进行权限隔离。
任务资源共享: DolphinScheduler本身支持对象存储。我们决定将所有集群的任务资源统一上传到同一个对象存储桶中,从而实现资源的统一管理和调度。
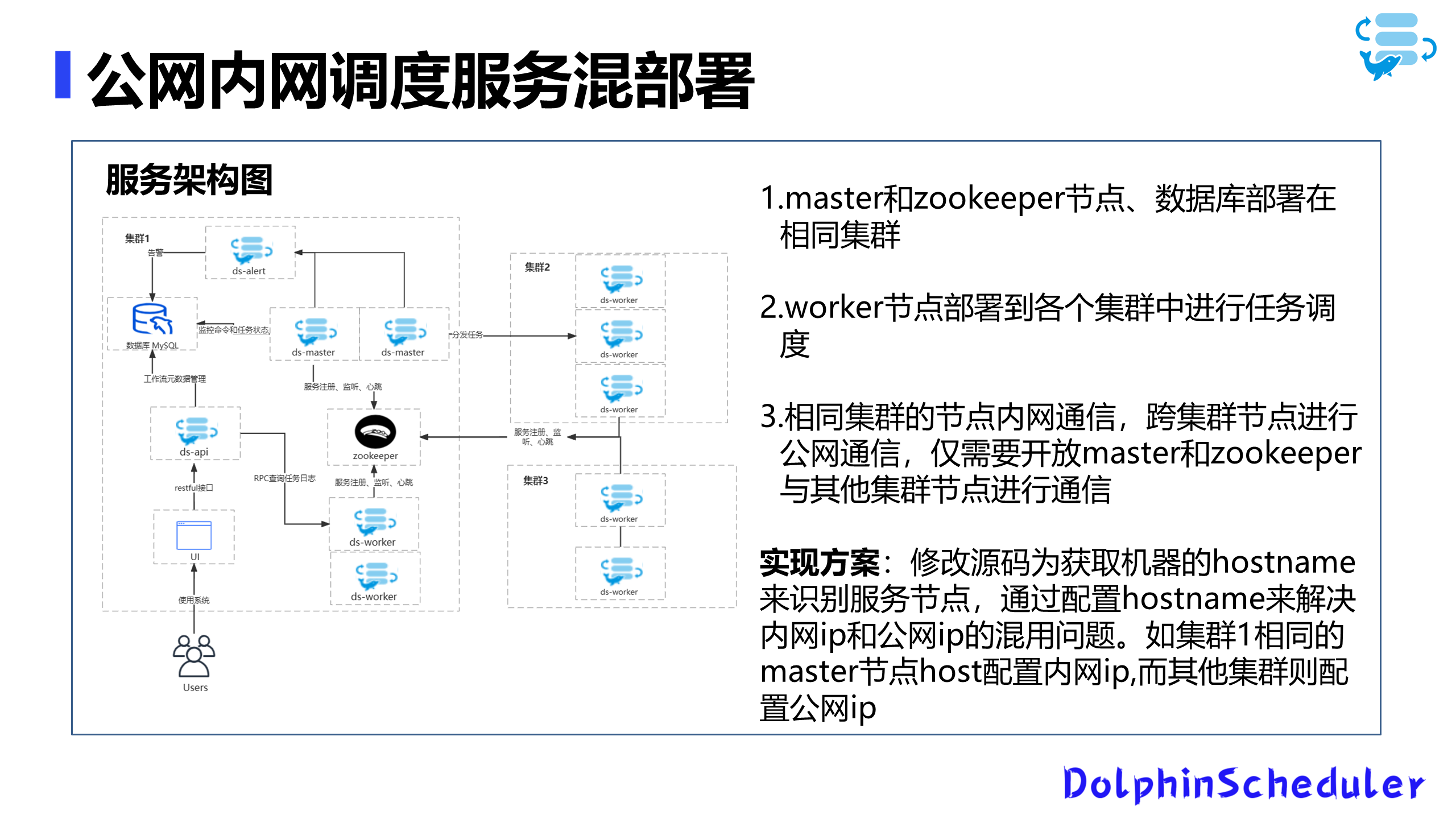
服务架构
我们的新架构基于DolphinScheduler的3.1.4版本。为了实现公网和内网通讯的混合部署,我们做了以下调整:
- 同一机房内的服务节点通过内网通讯。
- 不同机房之间的节点通过公网通讯。
- master节点和zookeeper部署在统一机房内并与其他节点进行通讯。
![file]()
为了实现上述设计,我们修改了DolphinScheduler的源码,使其可以基于主机名(Hostname)来识别服务节点,而不仅仅是IP。然后,我们通过配置hosts文件来映射内网IP和公网IP,从而实现内外网IP的动态切换。
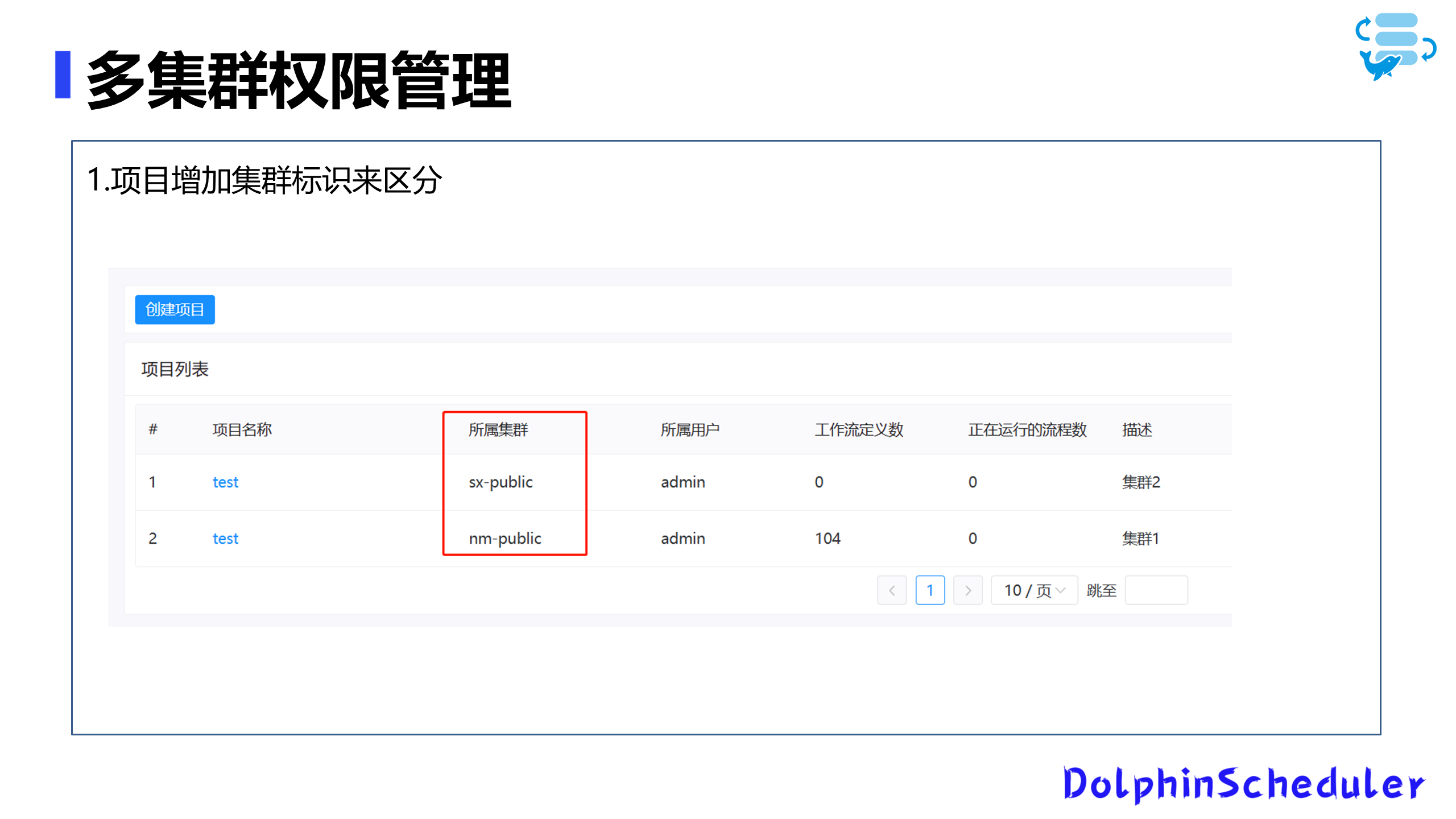
多权限集群管理的挑战与实施
面对众多的项目基于单集群架构(单机房)的实际情况,我们实施了一个独特的集群标识系统,借由在数据库表格中新增字段的方法实现。为识别各集群身份,我们采用字符标识,以便在项目中明确标明集群归属。
集群标识的引入是基于以下几点:
- 部署决策:我们将不同的账户节点部署至不同的数据中心。
- 环境获取:在用户配置过程中,我们需要确定他们如何获得环境信息。为此,我们将不同集群的环境配置集中处理,并分配至不同的组。
- 授权策略:在进行授权时,我们只需将相应集群环境授权给用户即可。用户在配置任务时,仅需选择我们授权给他们的集群环境。
在部署不同账户节点至多机房的过程中,一个值得探讨的问题是:在配置用户时,如何有效获取其运行环境?
![file]()
我们将各集群环境信息配置至平台,进一步配置至不同分组。在执行授权时,简化操作——仅需将授权的集群环境授权给相应用户,通过集群环境实现集群的隔离与任务分配。 ![file]()
调度逻辑的升级与改造
在实际使用过程中,我们从DolphinScheduler 3.0升级至3.1.4,经历了多次版本升级。经历了跨机房施工与临时停服的挑战后,我们开发了一个自动连续调度系统,解决了由于非计划性停机导致的人工数据补充问题。
优化方案
逻辑统一:我们统一了DS的调度逻辑。之前的逻辑在调度一条任务时,会在表中插入一条记录,调度完成后再删除。现在的优化方案直接预生成未来需要调度的50条记录。
资源文件的缓存处理
我们面临一个挑战——在跨机房调度任务的过程中,资源文件需从S3下载,受到机房带宽的限制,这一过程变得异常缓慢。因此,我们实施了一个资源文件缓存机制,当从S3下载资源后,通过本地缓存与时间戳判断来避免不必要的重复下载,并通过软链接的方式快速引导执行目录。
缓存优化的必要性源于以下几点:
- 跨网调度:我们跨网络调度任务时需从S3下载资源。
- 带宽限制:由于数据中心的带宽限制(千兆带宽,而业界通常为万兆),下载速度较慢。
实施细节
- 缓存逻辑:简要来说,每次从S3下载的资源会被缓存至本地。通过检查资源的时间戳来判断其是否被更新,未更新的资源将直接链接至本地文件。
调度连续性的直观展示
通过具体图表的展示,我们详细说明了调度自动连续的效果和相关的恢复容错机制。例如,一项工作流作业每20秒执行一次,在DS不可用的近三分钟后,我们恢复了服务。调度能继续执行停服期间未调度的实例,并避免了发布或服务重启时需要数据开发团队进行手动补数。 ![file]()
未来计划:开发作业调度分析页面
我们注意到,当前的海豚调度器尚不具备一个集中分析多项目作业的页面。我们计划开发一个作业调度分析页面,从而简化多集群项目的作业故障日志分析和作业调度跟进处理。
![file]()
这个页面将基于任务维度展示相关作业,允许查看日志、重运作业,并提供一定的筛选功能。这将辅助开发和运维团队更快速地定位和分析问题,并高效地处理例如作业重运等操作。
通过上述的一系列策略和改进,我们在多集群管理、调度逻辑和资源缓存等多个方面实现了技术的优化和提升。我们会继续深入研究和开发,希望为社区提供更多的便利和支持。
我的演讲到此结束,非常感谢大家的聆听!
本文由 白鲸开源科技 提供发布支持!