架构简介
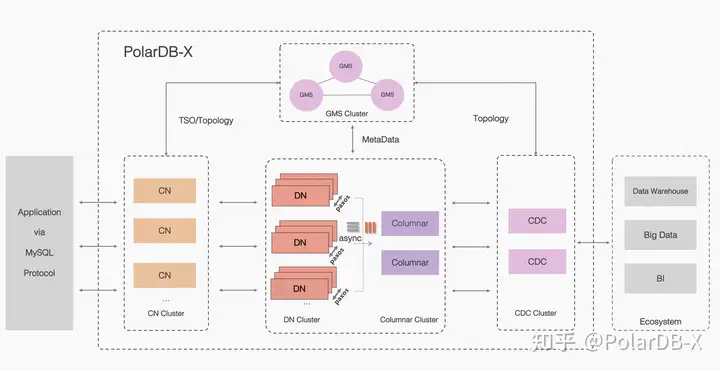
PolarDB-X 采用 Shared-nothing 与存储分离计算架构进行设计,系统由5个核心组件组成。
![]()
- 计算节点(CN, Compute Node) 计算节点是系统的入口,采用无状态设计,包括 SQL 解析器、优化器、执行器等模块。负责数据分布式路由、计算及动态调度,负责分布式事务 2PC 协调、全局二级索引维护等,同时提供 SQL 限流、三权分立等企业级特性。
- 存储节点(DN, Data Node) 存储节点负责数据的持久化,基于多数派 Paxos 协议提供数据高可靠、强一致保障,同时通过 MVCC 维护分布式事务可见性。
- 元数据服务(GMS, Global Meta Service) 元数据服务负责维护全局强一致的 Table/Schema, Statistics 等系统 Meta 信息,维护账号、权限等安全信息,同时提供全局授时服务(即 TSO)。
- 日志节点(CDC, Change Data Capture) 日志节点提供完全兼容 MySQL Binlog 格式和协议的增量订阅能力,提供兼容 MySQL Replication 协议的主从复制能力。
- 列存节点 (Columnar)
列存节点负责提供列式存储数据,基于行列混存 + 分布式计算节点构建HTAP架构,预计24年4月份会正式开源
开源地址: https://github.com/polardb/polardbx-sql
版本说明
梳理下PolarDB-X 开源脉络:
- 2021年10月,在云栖大会上,阿里云正式对外开源了云原生分布式数据库PolarDB-X,采用全内核开源的模式,开源内容包含计算引擎、存储引擎、日志引擎、Kube等。
- 2022年1月,PolarDB-X 正式发布 2.0.0 版本,继 2021 年 10 月 20 号云栖大会正式开源后的第一次版本更新,更新内容包括新增集群扩缩容、以及binlog生态兼容等特性,兼容 maxwell 和 debezium 增量日志订阅,以及新增其他众多新特性和修复若干问题。
- 2022年3月,PolarDB-X 正式发布 2.1.0 版本,包含了四大核心特性,全面提升 PolarDB-X 稳定性和生态兼容性,其中包含基于Paxos的三副本共识协议。
- 2022年5月,PolarDB-X正式发布2.1.1 版本,重点推出冷热数据新特性,可以支持业务表的数据按照数据特性分别存储在不同的存储介质上,比如将冷数据存储到Aliyun OSS对象存储上。
- 2022年10月,PolarDB-X 正式发布2.2.0版本,这是一个重要的里程碑版本,重点推出符合分布式数据库金融标准下的企业级和国产ARM适配,共包括八大核心特性,全面提升 PolarDB-X 分布式数据库在金融、通讯、政务等行业的普适性。
- 2023年3月,PolarDB-X 正式发布2.2.1版本,在分布式数据库金融标准能力基础上,重点加强了生产级关键能力,全面提升PolarDB-X面向数据库生产环境的易用性和安全性,比如:提供数据快速导入、性能测试验证、生产部署建议等。
2023年10月份,PolarDB-X 正式发布 2.3.0版本,重点推出PolarDB-X标准版(集中式形态),将PolarDB-X分布式中的DN节点提供单独服务,支持paxos协议的多副本模式、lizard分布式事务引擎,可以100%兼容MySQL。同时在性能场景上,采用生产级部署和参数(开启双1 + Paxos多副本强同步),相比于开源MySQL 8.0.34,PolarDB-X在读写混合场景上有30~40%的性能提升,可以作为开源MySQL的最佳替代选择。
01 集中式与分布式
架构形态
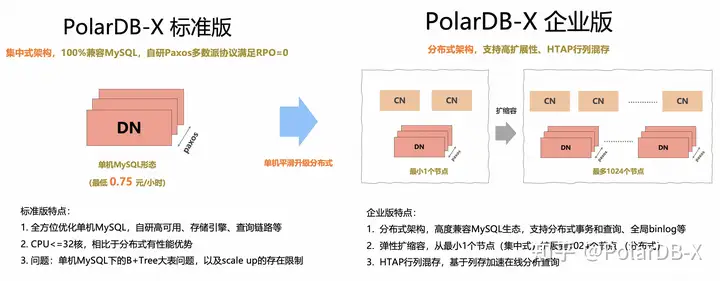
PolarDB-X V2.3.0新增了标准版(集中式形态),因此后续的PolarDB-X开源形态主要分为:
![]()
- PolarDB-X 标准版,主打集中式架构,支持单机MySQL形态(100%兼容MySQL),基于自研分布式共识算法(X-Paxos)提供RPO=0的数据库能力
- PolarDB-X 企业版,主打分布式架构,高度兼容MySQL生态,支持强一致分布式事务和分布式并行查询,支持分布式水平扩展,可以从最小1个节点(集中式)扩展到1024个节点(分布式),构建集中式和分布式一体化的架构能力,后续的开源版本会发布HTAP行列混存架构,支持一键构建列存副本,通过行列混合查询全面加速在线分析能力。
架构形态的特点和选型建议:
| 形态 |
标准版(集中式) |
企业版(分布式) |
| 优缺点 |
特点:
1. 主打MySQL 100%兼容性
2. 小规格下(比如CPU<=32核),相比于分布式有性能优势,未来大规格需求可以平滑升级分布式
缺点:
1. 单机MySQL下的B+Tree大表并发问题,单表行记录建议控制在500万~5000万
2. 单机的scale up存在上限 |
特点:
1. 主打分布式线性扩展,最大可支持1024节点,PB级别的数据规模
2. 金融级容灾,支持同城3机房、两地三中心等容灾形态
3. HTAP行列混存,内置列存副本加速在线分析能力 |
| 选型建议 |
1. 需要MySQL,支持跨机房容灾,且满足RPO=0
2. 需要低成本MySQL,且满足开源,业务可上可下 |
1. 需要分布式并发扩展,解决订单交易类高并发
2. 替代开源分库分表,解决运维问题
3. 解决MySQL大表问题,基于分布式进行数据分片
4. 需要分布式架构升级,且满足开源 |
快速部署和体验
PolarDB-X 标准版采用一主一备一日志的三节点架构,性价比高,通过多副本同步复制,确保数据的强一致性。面向具备超高并发、复杂查询及轻量分析的在线业务场景。
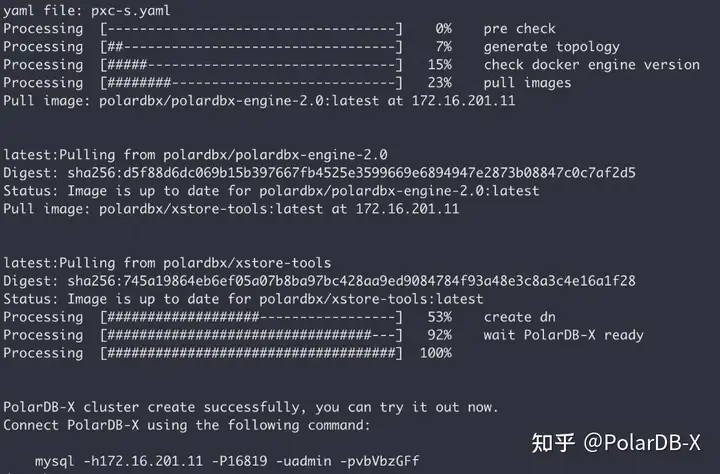
现在我们来快速部署一个 PolarDB-X 标准版集群,它仅包含 1 个由三副本组成的DN节点。执行以下命令创建一个这样的标准版集群:
基于k8s部署标准版
echo "apiVersion: polardbx.aliyun.com/v1
kind: XStore
metadata:
name: quick-start
spec:
config:
controller:
RPCProtocolVersion: 1
topology:
nodeSets:
- name: cand
replicas: 2
role: Candidate
template:
spec:
image: polardbx/polardbx-engine-2.0:latest
resources:
limits:
cpu: "2"
memory: 4Gi
- name: log
replicas: 1
role: Voter
template:
spec:
image: polardbx/polardbx-engine-2.0:latest
resources:
limits:
cpu: "1"
memory: 2Gi" | kubectl apply -f -
你将看到以下输出:
xstore.polardbx.aliyun.com/quick-start created
使用如下命令查看创建状态:
$ kubectl get xstore -w
NAME LEADER READY PHASE DISK VERSION AGE
quick-start quick-start-4dbh-cand-0 3/3 Running 3.6 GiB 8.0.18 11m
当 PHASE 显示为 Running 时,PolarDB-X 标准版集群已经部署完成!
注意:生产环境部署时建议内存>=8GB,参考: https://doc.polardbx.com/deployment/topics/environment-requirement.html
基于pxd部署标准版
version: v1
type: polardbx
cluster:
name: pxc_test
dn:
image: polardbx/polardbx-engine-2.0:latest
replica: 1
nodes:
- host_group: [172.16.201.11,172.16.201.11,172.16.201.11]
resources:
mem_limit: 2G
说明:replica数据节点数目,标准版中默认设置为 1,分布式形态可以设置为多个
执行如下命令,即可在集群内一键部署 PolarDB-X:
pxd create -file polardbx.yaml
部署完成后,pxd 会输出 PolarDB-X 集群的连接方式,通过 MySQL 命令行即可登录 PolarDB-X 数据库进行测试。
![]()
性能测试
PolarDB-X 标准版集中式实例,基于Lizard分布式事务系统优化事务并发能力,采用生产级部署和参数(开启双1 + 多副本复制),相比于开源MySQL 8.0.34,PolarDB-X在读写混合场景上有30~40%的性能提升。
详细性能测试情况如下:
| 机器用途 |
机型 |
规格 |
| 压力机 |
ecs.hfg7.6xlarge |
24c96g |
| 数据库机器 |
ecs.i4.8xlarge * 3 |
32c256g + 7TB的存储,单价:7452元/月 |
场景1:sysbench,表16张,单张表大小1千万
| 场景 |
50 |
100 |
150 |
200 |
250 |
300 |
| oltp_point_select |
317151.01 |
464316.53 |
485389.86 |
487124.91 |
489078.48 |
487684.83 |
| oltp_read_only |
291317.42 |
401566.17 |
420416.04 |
388937.68 |
382861.20 |
413884.86 |
| oltp_read_write |
156294.12 |
199195.62 |
214608.23 |
228713.64 |
254317.93 |
265322.61 |
| oltp_write_only |
38574.92 |
52876.25 |
59393.07 |
62235.96 |
65523.25 |
66866.19 |
| oltp_update_index |
38005.13 |
51803.68 |
58119.58 |
62263.46 |
63918.22 |
64203.57 |
| oltp_update_non_index |
39712.23 |
54418.94 |
64213.46 |
67319.67 |
69110.39 |
70028.34 |
场景2:TPC-C,1000仓
| 场景 |
50 |
100 |
150 |
200 |
250 |
300 |
| 1000 仓 |
173916.76 |
224736.03 |
241440.77 |
246228.18 |
247217.83 |
249902.01 |
场景3:对比开源MySQL 8.0.34(采用相同的主机硬件部署)
| 场景 |
并发数 |
MySQL 8.0.34
主备副本+异步复制 |
PolarDB-X 标准版集中式
Paxos三副本 |
性能提升 |
| sysbench oltp_read_write |
300并发 |
200930.88 |
265322.61 |
↑32% |
| TPCC 1000仓 |
300并发 |
170882.38 tpmC |
249902.01 tpmC |
↑46% |
更多性能数据可参考文档:
- Sysbench 测试报告 · PolarDB-X 产品文档
- TPC-C 测试报告 · PolarDB-X 产品文档
02 MySQL兼容性
PolarDB-X V2.3版本在分布式形态上,继续完善MySQL兼容性,降低用户从MySQL迁移的使用门槛。
分区表
MySQL的分区表功能是指将一个大表拆分成多个较小的逻辑单元,每个单元被称为分区,并将这些分区存储在不同的物理存储介质上,这种分区机制非常贴合分布式的分区理念。因此,PolarDB-X 的分区表全面兼容并扩展MySQL分区表的语法,将MySQL的多个分区扩展到了分布式节点中,基于分布式的多节点进一步提高了并发能力。 PolarDB-X 分区表支持常见的分区方式:
- 范围分区(Range、Range Columns):根据列的范围将表的数据进行分区。可以根据某个列的数值范围(如日期、价格等)将数据分布到不同的分区中。
- 列表分区(List、List Columns):根据列的值列表将表的数据进行分区。可以将特定列的值匹配到预定义的分区列表中,每个分区可以包含多个值。
- 哈希分区(Hash、Key):根据列值的哈希结果将表的数据进行分区。哈希分区将表的数据按照哈希算法将数据均匀地分布到不同的分区中。
PolarDB-X 除了可以对表进行一级分区外,还可以对分区进行二级分区。二级分区是在一级分区的基础上再次将数据进行细分,一级分区与二级分区是完全正交的关系,支持使用任意两种分区策略进行组合,组合分区的数目支持达 36 种。 同时在PolarDB-X中,二级分区可以分为模板化分区和非模板化分区两种方式。
1.模板化分区(Template-based Partitioning):模板化分区是指通过定义一个模板来创建二级分区。模板包含了一系列分区规则,用于指定每个一级分区的子分区数量和名称。使用模板化分区,可以快速创建具有相同结构的二级分区。
以下是一个示例,展示了使用模板化分区创建二级分区的语法:
CREATE TABLE partitioned_table (
...
)
PARTITION BY RANGE COLUMNS(column1)
SUBPARTITION BY HASH(column2)
SUBPARTITIONS 4
SUBPARTITION TEMPLATE (
SUBPARTITION s1,
SUBPARTITION s2,
SUBPARTITION s3,
SUBPARTITION s4
) (
PARTITION p1 VALUES LESS THAN (100),
PARTITION p2 VALUES LESS THAN (200),
...
);
在上述示例中,通过SUBPARTITION TEMPLATE关键字定义了一个二级分区模板,指定了每个一级分区的四个子分区名称。然后在每个一级分区中,通过指定SUBPARTITION TEMPLATE将使用相同的子分区模板。
2.非模板化分区(Non-template-based Partitioning):非模板化分区是指手动为每个一级分区指定子分区的数量和名称。使用非模板化分区,可以更加灵活地为每个一级分区创建不同数量和名称的子分区。
以下是一个示例,展示了使用非模板化分区创建二级分区的语法:
CREATE TABLE partitioned_table (
...
)
PARTITION BY RANGE COLUMNS(column1)
SUBPARTITION BY HASH(column2)
SUBPARTITIONS (
PARTITION p1 VALUES LESS THAN (100) (
SUBPARTITION s1,
SUBPARTITION s2,
SUBPARTITION s3,
SUBPARTITION s4
),
PARTITION p2 VALUES LESS THAN (200) (
SUBPARTITION s5,
SUBPARTITION s6,
SUBPARTITION s7,
SUBPARTITION s8
),
...
);
在上述示例中,通过直接为每个一级分区指定了不同数量和名称的子分区,而不使用模板来定义。
PolarDB-X 模板化分区和非模板化分区都有其优势和用途。模板化分区适合创建具有相同结构的分区表,可以减少创建表的工作量。非模板化分区则更加灵活,可以根据具体需求为每个一级分区创建不同的子分区数量和名称。 传统的分库分表定义方式是一个特例的模板化二级分区的定义(每个分库下有相同的分表数量),PolarDB-X新版本支持了完整的分布式分区表能力,可以结合非模板化分区更好的优化分布式热点。
结合一个实际的例子来体验下非模板分区的好处:交易订单管理系统,整个平台服务不同品牌的众多卖家,不同卖家之间订单量差异比较大,会出现比较明显的大卖家的情况,大卖家愿意成为vip付费会员期望独享资源,小卖家使用免费共享资源。参考文档:【典型场景 | PolarDB-X 如何支撑SaaS多租户】
/* 一级分区 LIST COLUMNS + 二级分区HASH分区 的非模板化组合分区 */
CREATE TABLE t_order /* 订单表 */ (
id bigint not null auto_increment,
sellerId bigint not null,
buyerId bigint not null,
primary key(id)
)
PARTITION BY LIST(sellerId/*卖家ID*/) /* */
SUBPARTITION BY HASH(sellerId)
(
PARTITION pa VALUES IN (108,109)
SUBPARTITIONS 1 /* 一级分区 pa 之下有1个哈希分区, 保存大品牌 a 所有卖家数据 */,
PARTITION pb VALUES IN (208,209)
SUBPARTITIONS 1 /* 一级分区 pb 之下有1个哈希分区, 保存大品牌 b 所有卖家数据 */,
PARTITION pc VALUES IN (308,309,310)
SUBPARTITIONS 2 /* 一级分区 pc 之下有2个哈希分区, 保存大品牌 c 所有卖家数据 */,
PARTITION pDefault VALUES IN (DEFAULT)
SUBPARTITIONS 64 /* 一级分区 pDefault 之下有64个哈希分区, 众多小品牌的卖家数据 */
);
基于上述的 LIST+HASH 非模板化二级分区,它能给应用直接带来的的效果是:
- 对于大品牌的卖家(相当一个租户),可以将数据路由到单独的一组分区;
- 对于中小品牌,可以将数据按哈希算法自动均衡到多个不同分区,从而避免访问热点,比如default默认分配64个分区,支持所有的免费用户。而付费用户结合规模量,二级分区为1或者2即可,基于非模板化分区实现精细化数据分布。
生成列
MySQL的生成列功能是指在创建表时,使用虚拟列或计算列的方式将一个或多个列添加到表中,可以在创建表时使用GENERATED ALWAYS AS关键字来定义。通过使用表达式,可以使用各种数学、逻辑和字符串函数来计算列的值。生成列可以是虚拟列(VIRTUAL)或存储列(STORED)。 PolarDB-X 新版本支持MySQL生成列的相关语法和功能,参考文档:PolarDB-X 生成列语法
col_name data_type [GENERATED ALWAYS] AS (expr)
[VIRTUAL | STORED | LOGICAL] [NOT NULL | NULL]
[UNIQUE [KEY]] [[PRIMARY] KEY]
[COMMENT 'string']
生成列有以下三种类型:
- VITRUAL:生成列的值不存储,每次读取该列时由存储节点DN计算,不占用存储空间。说明如果不指定关键字,默认创建VITRUAL类型的生成列。
- STORED:生成列的值在数据行插入或更新时由存储节点DN计算,并将结果储存下来,需要占用存储空间。
- LOGICAL:与STORED类型相似,生成列的值在数据行插入或更新时计算,区别是生成列的值在计算节点CN计算,随后以普通列的形式存储到DN中。该类型的生成列可以作为分区键使用。
生成列的例子:
CREATE TABLE `t1` (
`a` int(11) NOT NULL,
`b` int(11) GENERATED ALWAYS AS (`a` + 1),
PRIMARY KEY (`a`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 partition by hash(`a`)
插入数据:
# INSERT INTO t1(a) VALUES (1);
# SELECT * FROM t1;
+---+---+
| a | b |
+---+---+
| 1 | 2 |
+---+---+
PolarDB-X兼容MySQL的生成列+索引的相关特性,支持在生成列上进一步创建索引来加速查询能力,比如针对json类型的内部key查询。 在生成列上创建索引的例子:
> CREATE TABLE t4 (
a BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
c JSON,
g INT AS (c->"$.id") VIRTUAL
) DBPARTITION BY HASH(a);
> CREATE INDEX `i` ON `t4`(`g`);
> INSERT INTO t4 (c) VALUES
('{"id": "1", "name": "Fred"}'),
('{"id": "2", "name": "Wilma"}'),
('{"id": "3", "name": "Barney"}'),
('{"id": "4", "name": "Betty"}');
// 可以使用虚拟列g的索引进行裁剪
> EXPLAIN EXECUTE SELECT c->>"$.name" AS name FROM t4 WHERE g > 2;
+------+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+------+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t4 | NULL | range | i | i | 5 | NULL | 1 | 100 | Using where |
+------+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+
MySQL 8.0版本开始提供了表达式索引的功能,引入了函数索引(Functional Indexes)的概念,允许在索引中使用表达式。通过在CREATE INDEX语句中指定表达式,可以创建索引以优化特定的查询,底层内部的实现原始是采用了虚拟列。 PolarDB-X 在v2.3版本中兼容了MySQL 8.0的函数索引,支持创建索引时如果PolarDB-X发现某个索引项不是表中的一个列,而是一个表达式,此时PolarDB-X会自动将该表达式转换为VIRTUAL类型的生成列并添加到表中。所有索引项处理完成后,PolarDB-X会按照用户定义继续创建索引,索引定义中的表达式索引项将被替换成对应的生成列。 此函数索引功能为实验特性,需要打开实验室参数开关后才能使用。
SET GLOBAL ENABLE_CREATE_EXPRESSION_INDEX=TRUE;
使用例子:
1. 创建表t7
> CREATE TABLE t7 (
a BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
c varchar(32)
) DBPARTITION BY HASH(a);
2. 创建表达式索引i
> CREATE INDEX `i` ON `t7`(substr(`c`, 2));
3. 完成表达式索引创建之后的表结构如下:
> SHOW FULL CREATE TABLE `t7`
# 返回结果
CREATE TABLE `t7` (
`a` bigint(20) NOT NULL AUTO_INCREMENT BY GROUP,
`c` varchar(32) DEFAULT NULL,
`i$0` varchar(32) GENERATED ALWAYS AS (substr(`c`, 2)) VIRTUAL,
PRIMARY KEY (`a`),
KEY `i` (`i$0`)
) ENGINE = InnoDB dbpartition by hash(`a`)
# 由于索引i的索引项是表达式,因此在表中添加了一个生成列i$0,这个生成列的表达式就索引项的表达式。最后创建索引i,其中索引项被替换成为对应的生成列。
# 创建完表达式索引之后,以下SQL就可以利用表达式索引加快查询速度:
> EXPLAIN EXECUTE SELECT * FROM t7 WHERE substr(`c`, 2) = '11';
+------+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+------+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| 1 | SIMPLE | t7 | NULL | ref | i | i | 131 | const | 1 | 100 | NULL |
+------+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
外键
MySQL中的外键(Foreign Key)是一种关系型数据库的特性,用于建立表与表之间的关联关系。外键定义了一个表中的列与另一个表中的列之间的引用关系。通过外键,可以实现数据完整性和一致性的约束,以及数据之间的参照关系。 PolarDB-X 在v2.3版本中兼容了MySQL外键的常见使用,让你可以在分布式数据库中,通过外键对跨(库)表的数据建立连接,实现等同于单机数据库外键的数据一致性保证。 同时,由于在分布式分区表上检查和维护外键约束的实现比单机数据库更为复杂,不合理的外键使用可能会导致较大的性能开销,导致系统吞吐显著下降。 因此,外键功能会作为一项长期的实验性功能,建议你在对数据进行充分验证后谨慎使用。
SET GLOBAL ENABLE_FOREIGN_KEY = TRUE;
外键相关语法:
-- 创建外键
[CONSTRAINT [symbol]] FOREIGN KEY
[index_name] (col_name, ...)
REFERENCES tbl_name (col_name,...)
[ON DELETE reference_option]
[ON UPDATE reference_option]
reference_option:
RESTRICT | CASCADE | SET NULL | NO ACTION | SET DEFAULT
-- 删除外键
ALTER TABLE tbl_name DROP FOREIGN KEY CONSTRAINT_symbol;
外键例子:
> CREATE TABLE a (
id INT PRIMARY KEY
);
> INSERT INTO a VALUES (1);
> CREATE TABLE b (
id INT PRIMARY KEY,
a_id INT,
FOREIGN KEY fk(`a_id`) REFERENCES a(`id`) ON DELETE CASCADE
);
> INSERT INTO b VALUES (1,1);
> CREATE TABLE c (
b_id INT,
FOREIGN KEY fk(`b_id`) REFERENCES b(`id`) ON DELETE RESTRICT
);
> INSERT INTO c VALUES (1);
# 删除表A的记录,会级联检查A/B/C表的外键约束
> DELETE FROM a WHERE id = 1;
> ERROR 1451 (23000): Cannot delete or update a parent row: a foreign key constraint fails (`test`.`c`, CONSTRAINT `c_ibfk_1` FOREIGN KEY (`b_id`) REFERENCES `b` (`id`) ON DELETE RESTRICT)
03 frodo流量回放工具
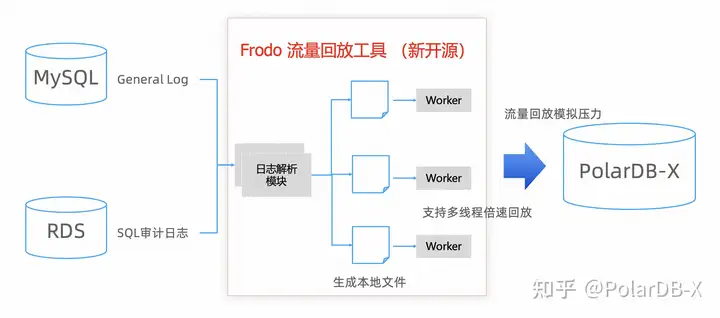
frodo是阿里云数据库团队开源的PolarDB-X配套工具,主打数据库流量回放,主要用于解决数据库交付过程中的业务兼容性和性能评估的工作。
开源地址:https://github.com/polardb/polardbx-tools/tree/frodo-v1.0.0/frodo
大致工作原理:
![]()
主要包含两部分功能:
- SQL日志采集,目前支持开源MySQL、以及aliyun RDS的SQL审计,支持将这部分sql日志解析为frodo内部的数据格式并持久化。
- SQL流量回放,基于真实的业务SQL在PolarDB-X中进行流量回放,通过引入多线程技术可以实现倍数回放来模拟峰值流量的压测
操作示例: 步骤一:从自建mysql采集general日志
java -jar mysqlsniffer.jar --capture-method=general_log --replay-to=file --port=3306 --username=root --password=xxx --concurrency=32 --time=60 --out=logs/out.json
步骤二:将流量回放到polardb-x
java -Xms=2G -Xmx=4G -jar frodo.jar --file=/root/out.json --source-db=mysql --replay-to=polarx --port=3306 --host=172.25.132.163 --username=root --password=123456 --concurrency=64 --time=1000 --task=task1 --schema-map=test:test1,test2 --log-level=info --rate-factor=1 --database=test
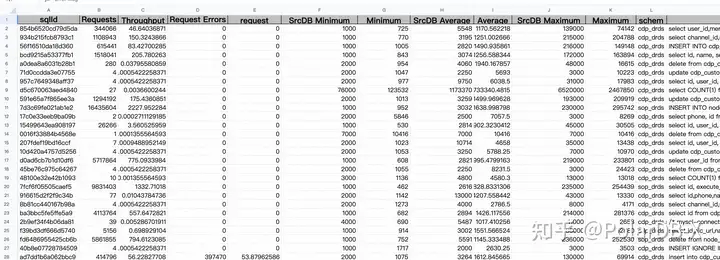
流量回放完成后会生成一份数据报告,记录SQL运行报告吗,比如:SQL模版、成功率、RT等。
![]()
04 开源生态完善
canal 开源适配
Canal是一款阿里云数据库团队开源的一款用于MySQL binlog实时数据同步和订阅的中间件。它基于数据库的日志解析技术,可以捕获数据库的增量变更,并将变更数据同步到其他系统,实现数据的实时同步和订阅。
![]()
Canal近期发布v1.1.7版本,支持PolarDB-X全局单流binlog、以及多流binlog的解析 #4657
![]()
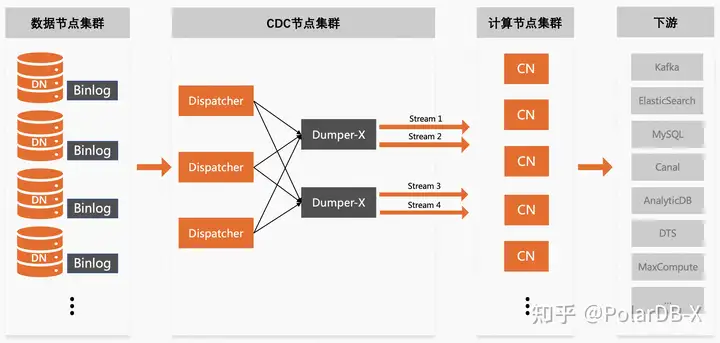
如上图所示,PolarDB-X提供了两种形态的binlog日志消费订阅能力,且两种形态可同时共存。
- 单流形态:即单流binlog日志(也称为Global binlog),将所有DN的binlog归并到同一个全局队列,提供了保证事务完整性和有序性的日志流,可以提供更高强度的数据一致性保证。例如在转账场景下,基于Global binlog接入PolarDB-X的下游MySQL,可以在任何时刻查询到一致的余额。
- 多流形态:即多流binlog日志(也称为Binlog-X),并不是将所有DN的binlog归并到一个全局队列,而是将数据进行Hash打散并分发到不同的日志流,在一定程度上牺牲了事务的完整性,但大大提升了扩展性,可以解决大规模集群下单流binlog存在的单点瓶颈问题。
canal 开源地址:https://github.com/alibaba/canal
kubeblocks 开源适配
KubeBlocks 是⼀个基于 Kubernetes 打造的、可⽀持多引擎统⼀接⼊和运维的开源项目,它可以帮助用户以 BYOC(Bring-your-own-cloud)的方式轻松构建容器化和声明式的关系型、NoSQL、流计算以及向量型数据库服务。 KubeBlocks 专为生产目的而设计,为大多数场景提供可靠、高性能、可观察和经济高效的数据基础设施。 KubeBlocks 名字灵感来自乐高积木,寓意在 Kubernetes 上可以像搭积木一样愉快地构建自己的数据基础设施。 KubeBlocks在即将发布的0.7版本里,会原生支持PolarDB-X:
![]()
基于kubeblocks快速安装polardb-x,只需要3步:
1.创建集群模板
helm install polardbx ./deploy/polardbx
2.创建polardb-x实例
方法一:
kbcli cluster create pxc --cluster-definition polardbx
方法二:
helm install polardbx-cluster ./deploy/polardbx-cluster
3.端口转发 & 登录数据库
kubectl port-forward svc/pxc-cn 3306:3306
mysql -h127.0.0.1 -upolardbx_root
CloudCanal 数据迁移同步适配
CloudCanal 是一款 数据同步、迁移 工具,帮助企业构建高质量数据管道,具备实时高效、精确互联、稳定可拓展、一站式、混合部署、复杂数据转换等优点。 通过CloudCanal,用户可以快速、可靠地实现云原生环境下的数据库数据同步。 同时,CloudCanal相比于Canal开源支持了更多的数据源接入、以及全量+结构迁移的能力,更好的满足用户一站式数据同步和迁移的功能。 CloudCanal近期发布的版本,完整支持PolarDB-X作为源端和目标端的场景,参考文档: https://www.clougence.com/cc-doc/releaseNote/rn-cloudcanal-2-7-0-0
![]()
原文链接
本文为阿里云原创内容,未经允许不得转载。