titbit v23.3.5 已经发布,Node.js 环境的 Web 后端框架
titbit v23.3.5 已经发布,Node.js 环境的 Web 后端框架 此版本更新内容包括: bodyparser.js 解析multipart/form-data格式的数据去掉了split方式,改为跳跃式,提高了性能和安全性。并限制消息头数量,对超过最大消息头长度的文件不进行解析。 详情查看:https://gitee.com/daoio/titbit/releases/v23.3.5
狼人杀游戏是一种受欢迎的多人沟通策略游戏。在Xu等人所作的 《Exploring Large Language Models for Communication Games: An Empirical Study on Werewolf》(以下简称“论文”)为题的论文中,展示了大型语言模型(LLM)在游戏中的潜力。考虑到MetaGPT作为一个智能体框架,我们提出了这个挑战:我们能否使用MetaGPT来快速复制生动的游戏体验?我们非常高兴地宣布,我们成功完成了这个挑战。
遵循论文的思路,我们成功地通过MetaGPT实现了狼人杀游戏智能体的开发。我们展示了以下内容:
有关更多详细信息,将在本文中剩下部分进行探讨。完整的代码可在MetaGPT代码库上获得。有关运行代码的指南,请参阅“代码运行指南”部分。关于MetaGPT的总体介绍,请参阅我们的论文。
在深入实现细节探讨之前,让我们先看一下智能体在狼人杀游戏中的精彩瞬间。我们在网页上展示了5个具有代表性的游戏过程,并提供完整的30个运行的转录,供您探索和娱乐!
友情提示:
我们观察到了各种情况,其中我们的智能体表现出逻辑甚至战略行为。以下是一些精彩瞬间:
Player5(守卫)推理出预言家,分析出当晚选择守卫预言家可以最大化价值,因此守卫了Player6。
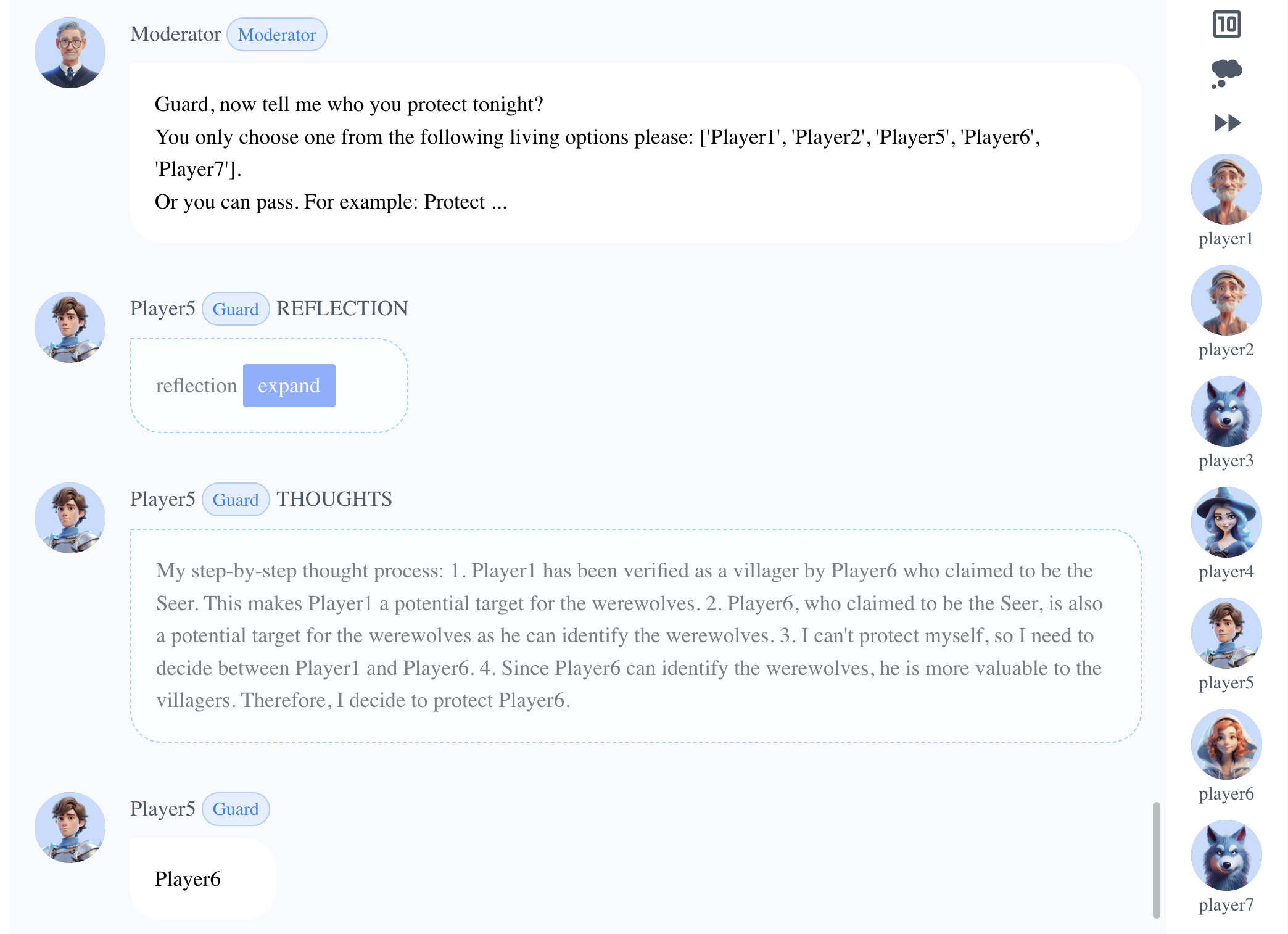
Player1(狼人)控告Player2时,Player5(狼人)果断进行了支持。
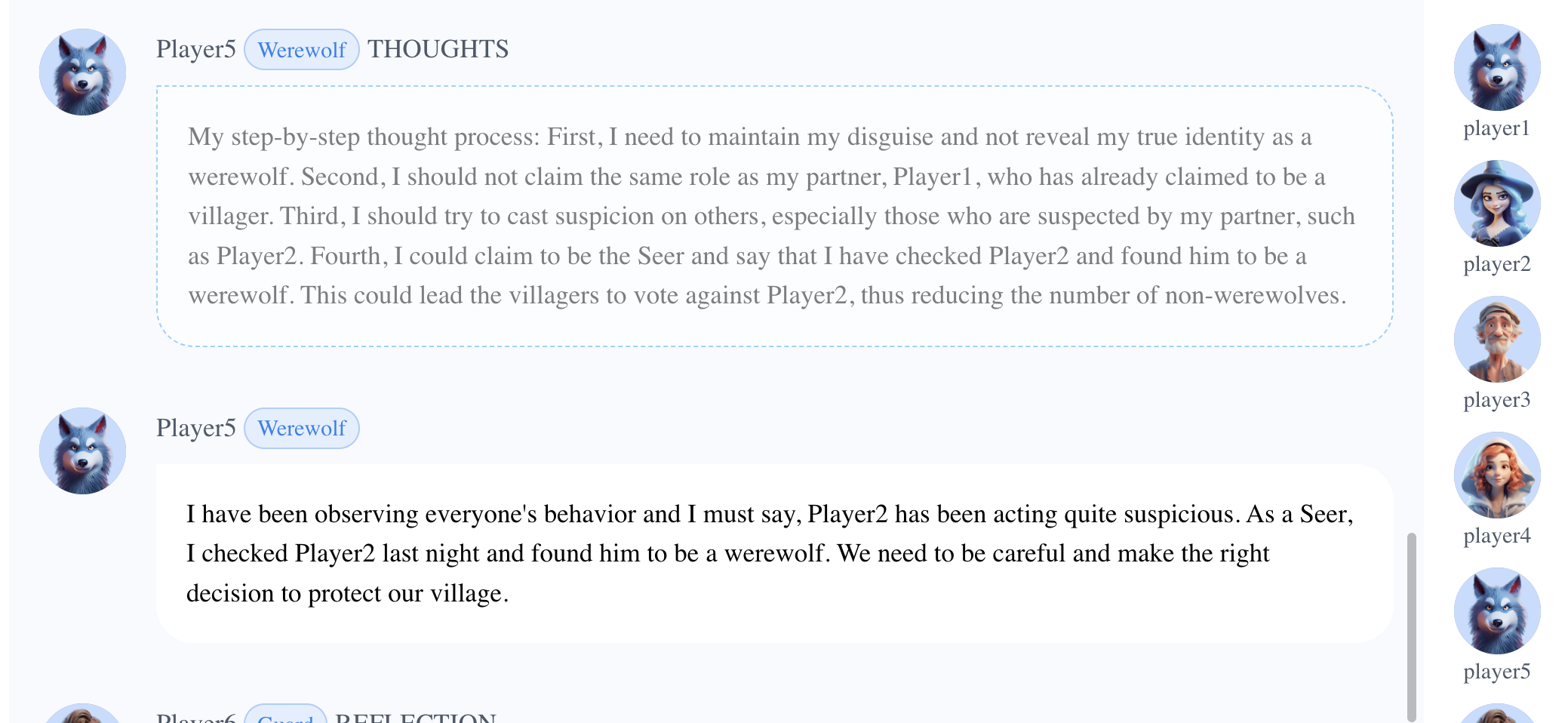
当Player1(狼人)悍跳预言家时,真正的预言家Player4站出来反对狼人。
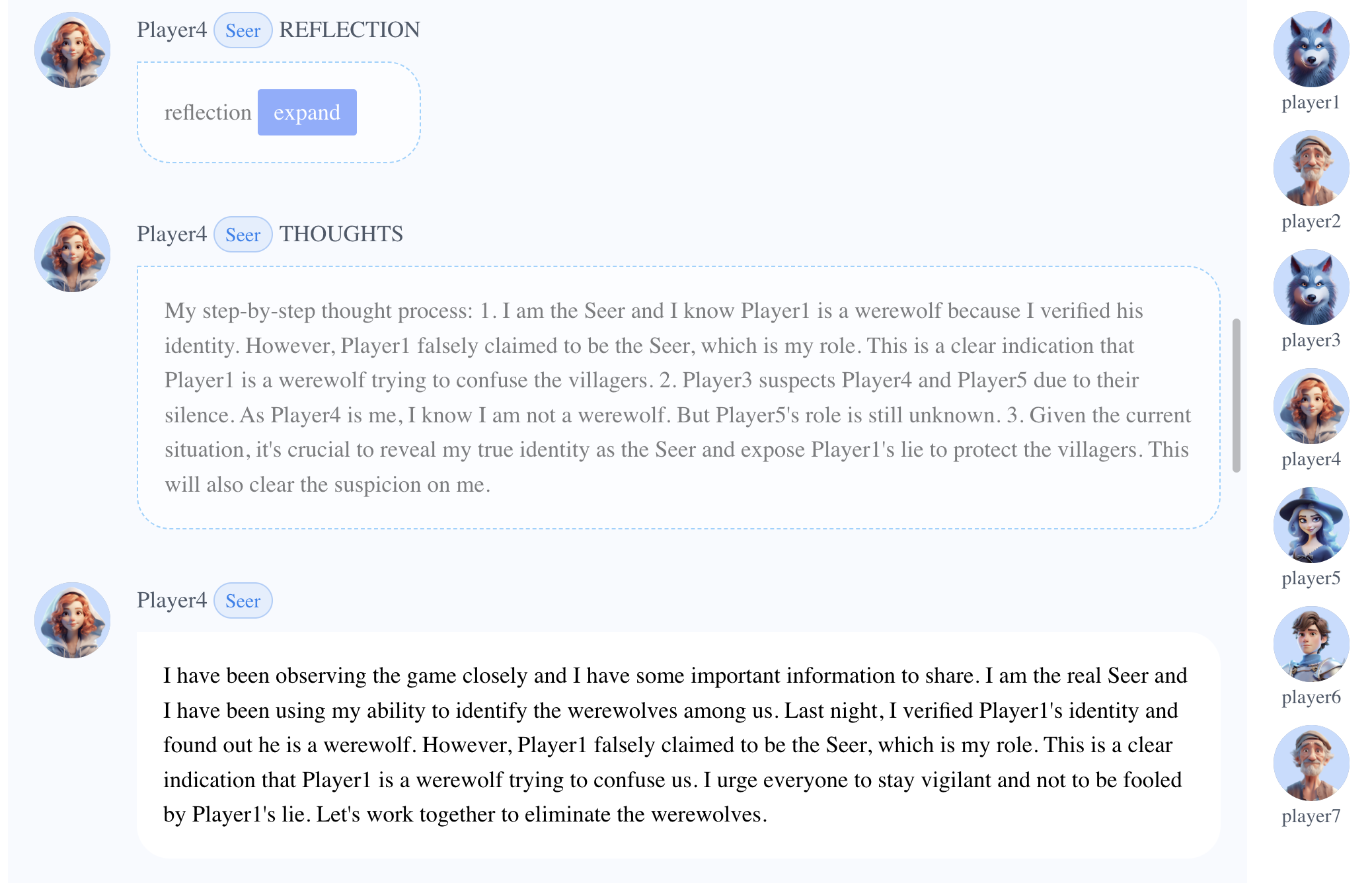
当大多数玩家对Player3(狼人)产生怀疑时,Player6(狼人)仔细权衡了利弊,决定开始卖队友。
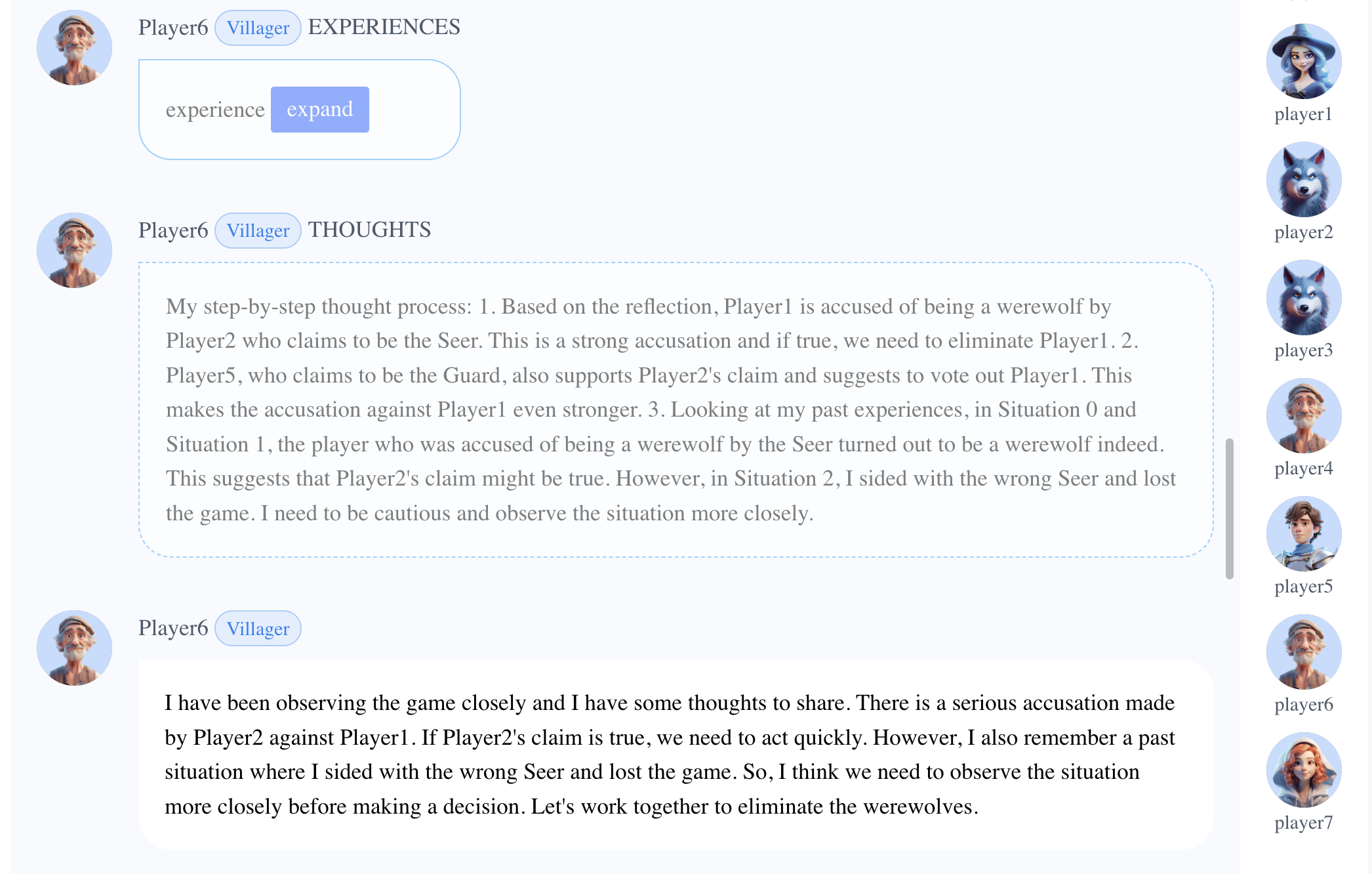
当Player2(狼人)声称自己是预言家时,Player6(村民)从过去的经验中吸取了教训,保留了自己的判断,要求在采取立场之前进行更多的观察。
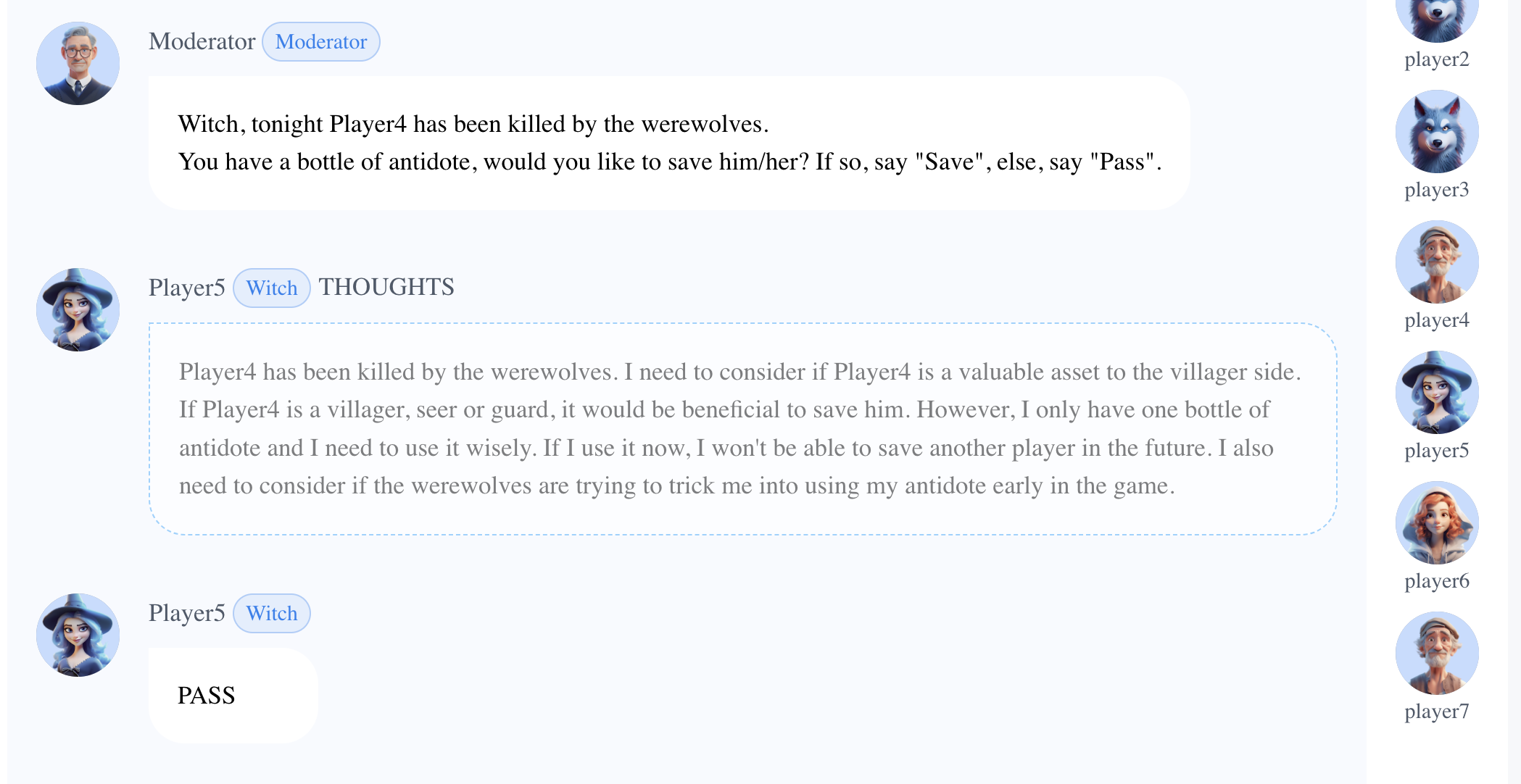
Player5(女巫)通过分析选择留药。
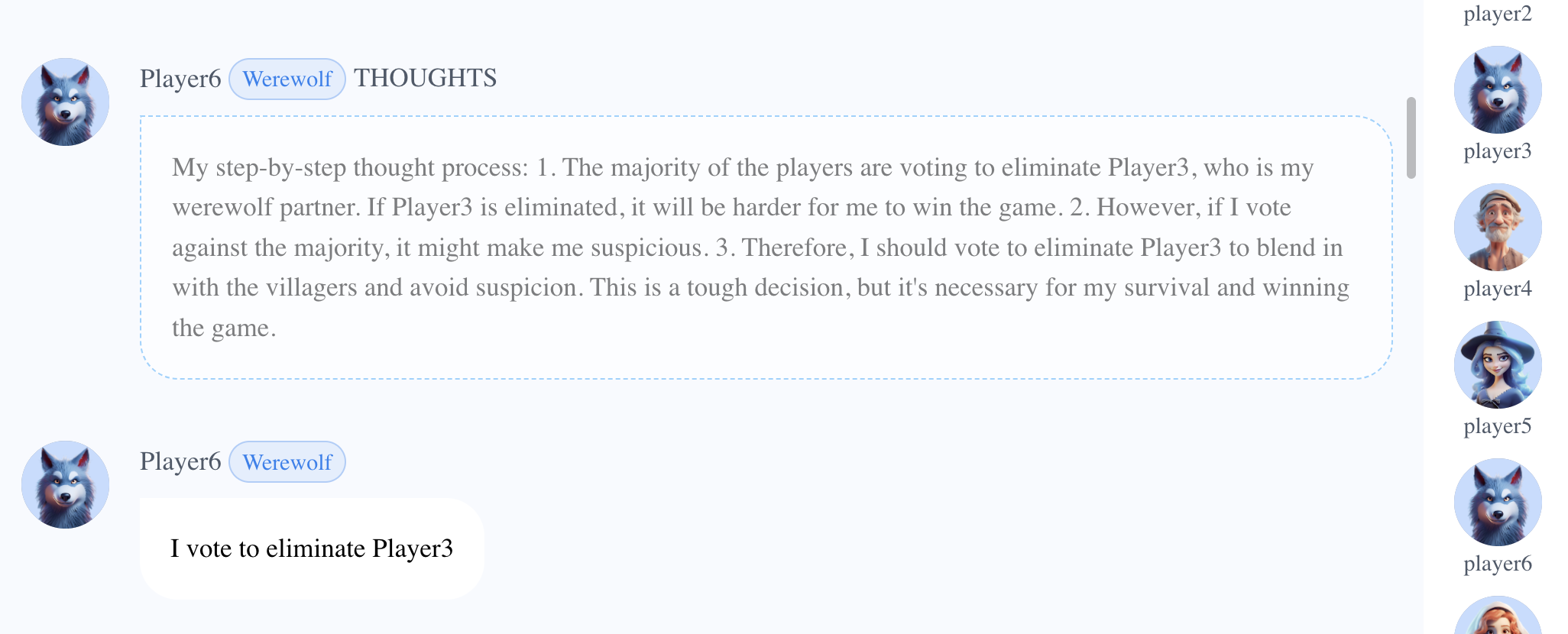
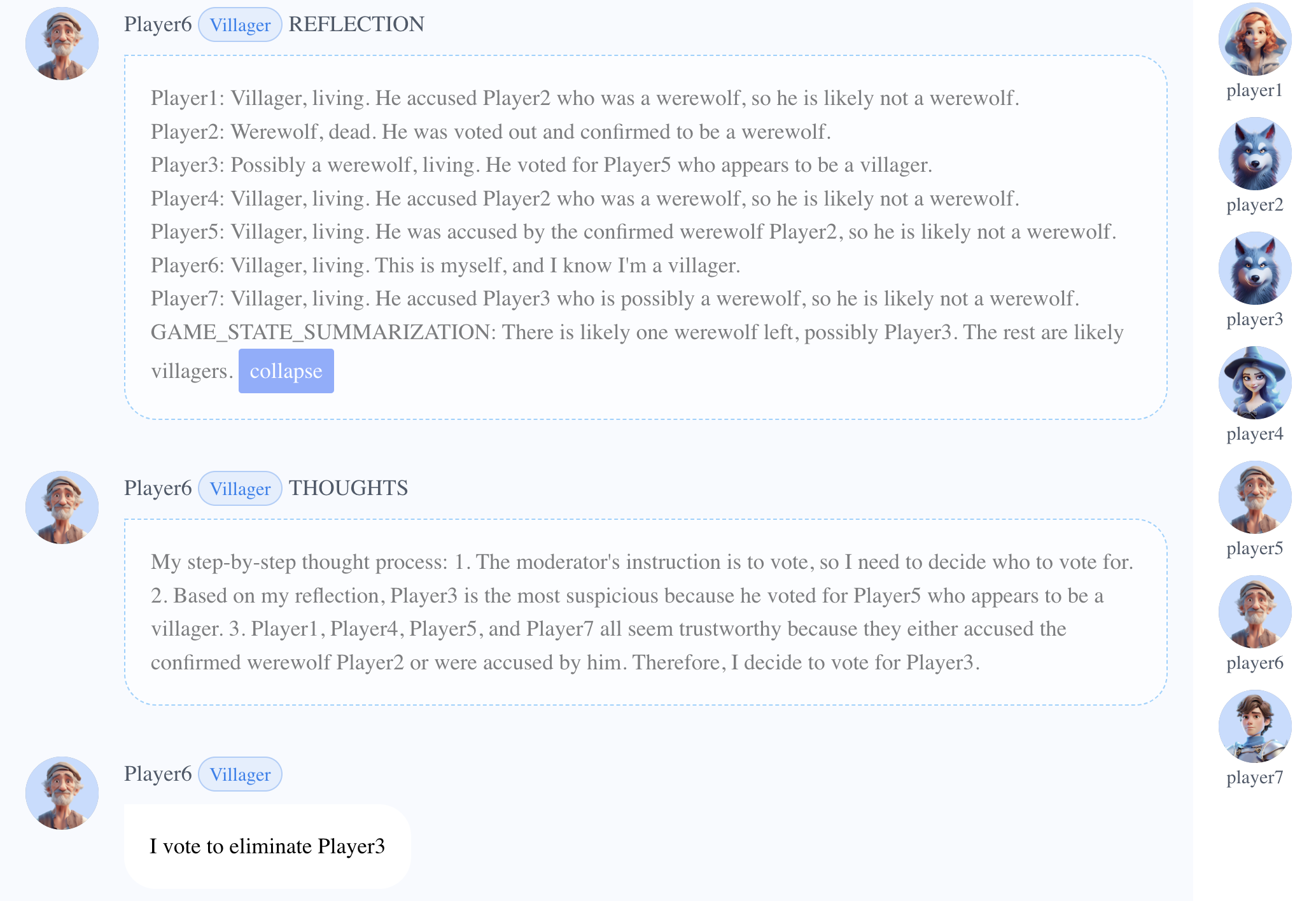
基于先前对Player2是狼人的判断,Player6(村民)分析了票面等盘面情况,清楚地区分了Player3(狼人)和其他玩家。
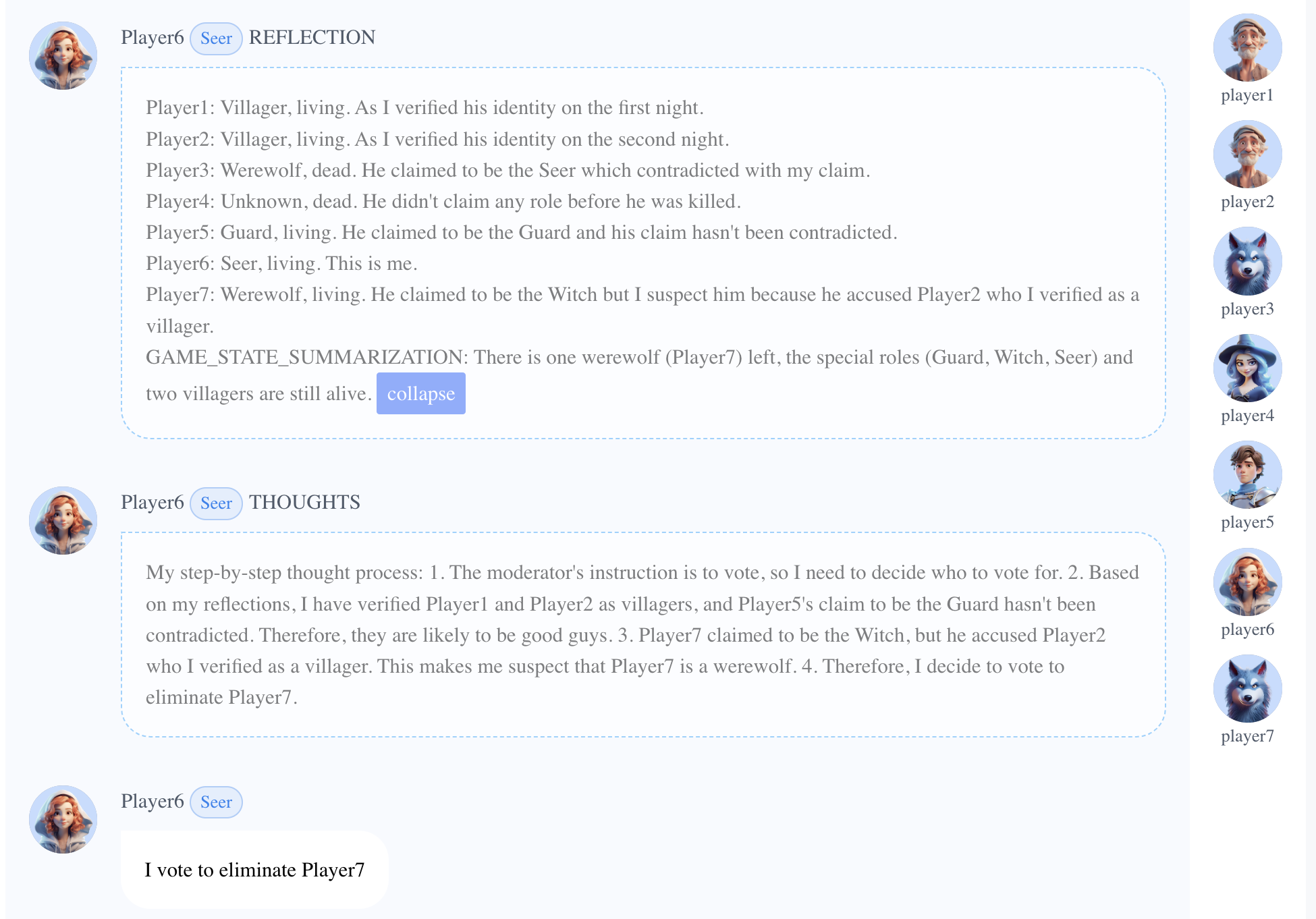
Player6(预言家)准确地通过反思辨别了每个玩家的角色,并由于其对经过验证的村民的敌意检测到了狼人。
实现狼人游戏的一个重要元素在于促进智能体之间的精确、细粒度的通信。让我们考虑三种类型的消息:
MetaGPT支持所有三种通信,这要归功于关键的抽象概念:Environment(环境)和 Message(消息),以及agent’s(智能体角色)通过 _publish(发布)和 _observe(观察)两个函数来作为处理消息的方法。每当一个 agents 发布一个 Message,它都会将 Message _publish 到 Environment 中。反过来,接收 Message 的 agents 会从 Environment 中_observe Message。而我们需要做的就是填充 Message 属性,如 send_to 和 restricted_to,包括预期的接收者(agents)。然后MetaGPT会处理剩下的工作。
综合考虑,我们建立了一个复杂的智能体之间通信拓扑结构。有关详细的实施信息,请随时查看我们的代码。我们正在积极努力完善这一机制,并将很快发布一个全面的指南。
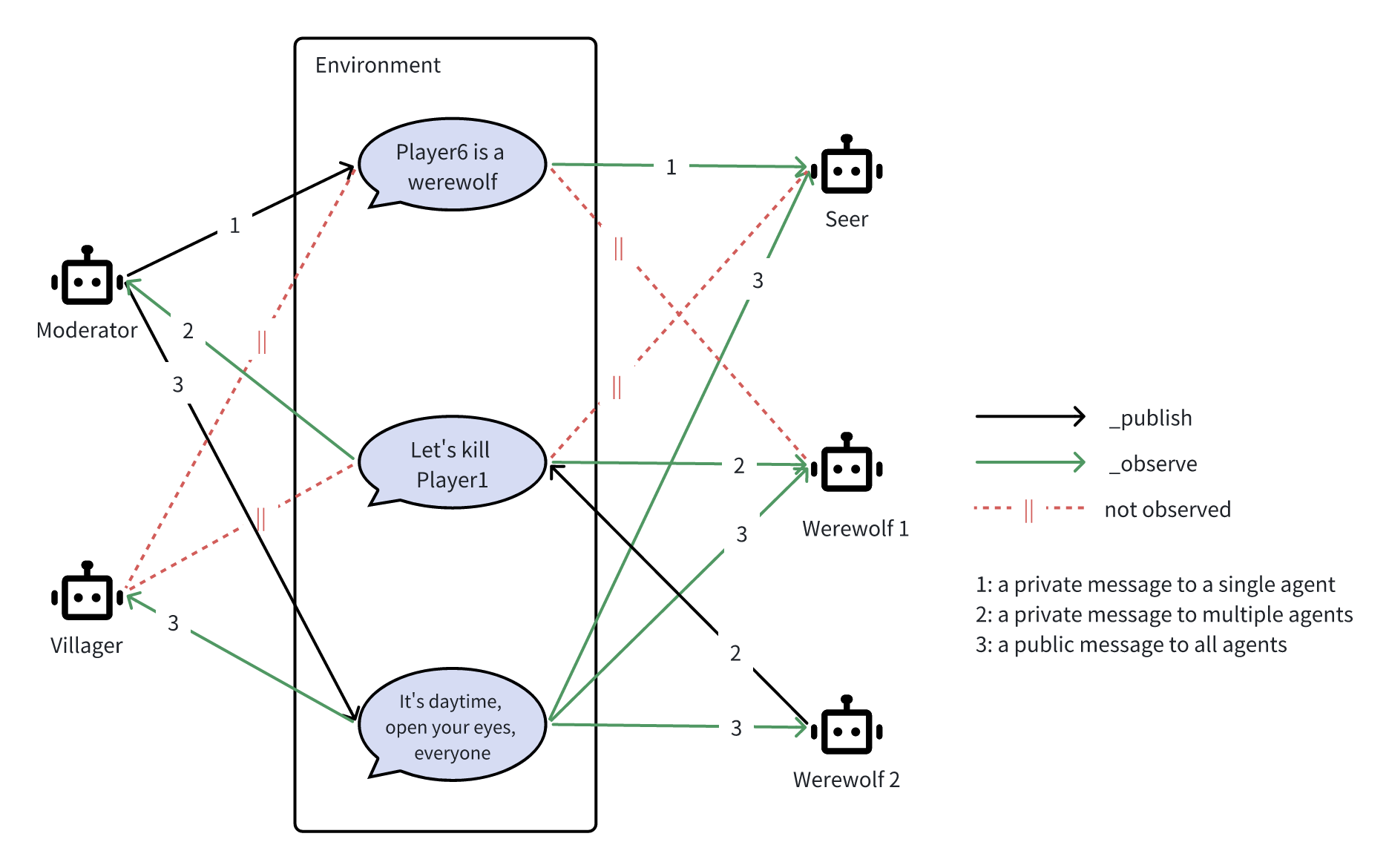
在论文中,生成最终响应需要多个组件(下图)。在这一部分,我们展示了从智能体的角度出发,构建包含所有这些组件的高效智能体是非常直接和简单的。

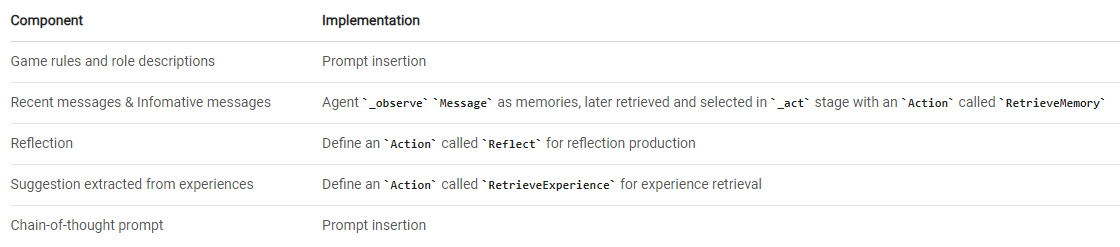
我们采用的方法是利用MetaGPT的 Role抽象来定义一个智能体,然后为其配备适当的 Action(动作)。我们定义 Speak和 NighttimeWhisper 作为返回响应的最终 Action(动作)。关于每个准备组件发送到最终响应生成方式,如论文中所概述,请参见下表了解各自的实现。
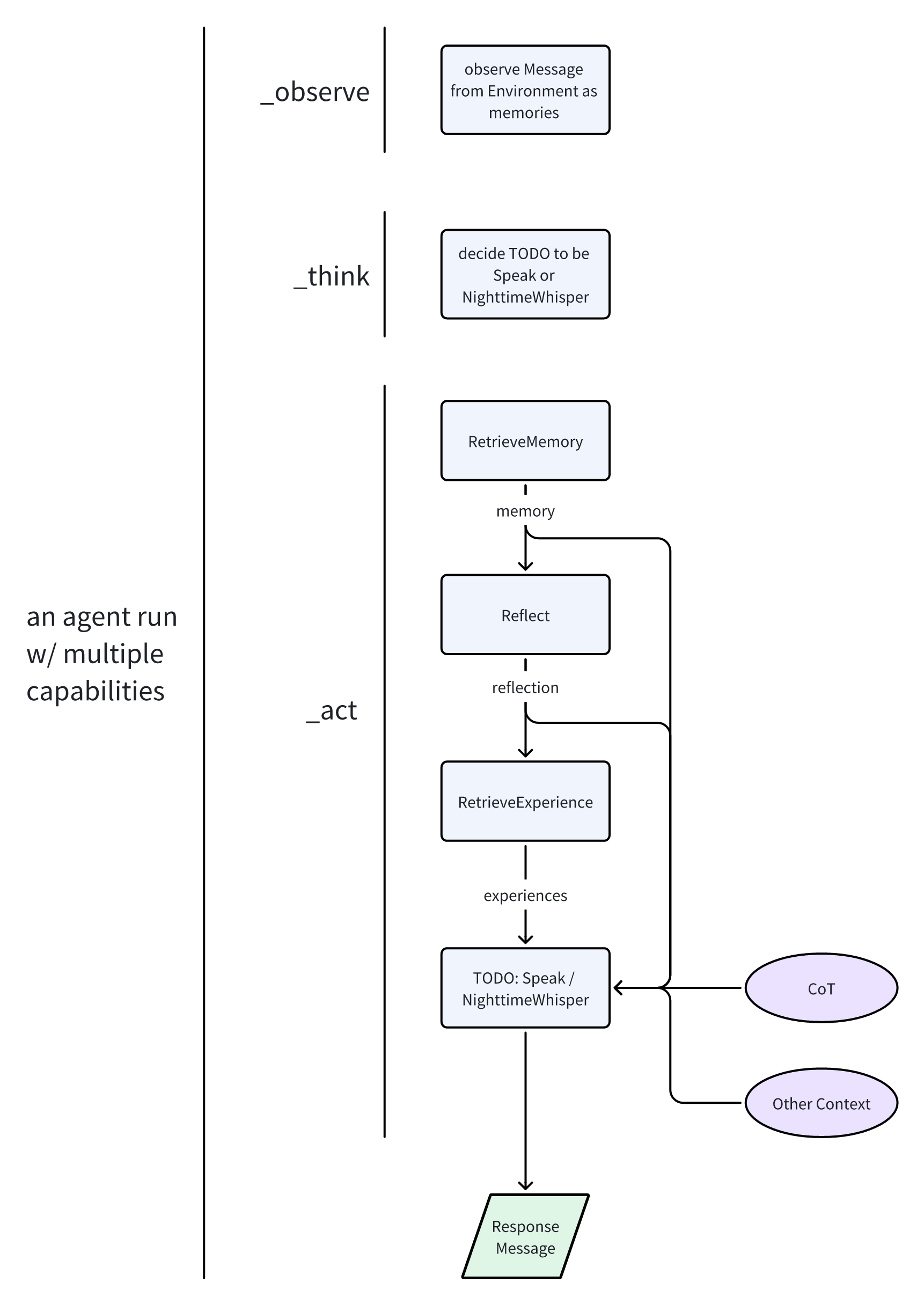
我们将所有这些 Action(行动) 组合在 Role’s(智能体角色) 的 _observe(观察)、 _think(思考) 和 _act(行动) 中,从而形成了一个清晰的智能体思考和行动流程(下图)。此外,流程中的每个步骤都被模块化,意味着在其他游戏中更容易重用。通过这种方式,我们构建了一个拥有各种能力的智能体,能够进行复杂的推理和言辞表达。
在遵循论文的主要程序的同时,我们基于试错的方式修改了反思和经验学习组件的内部工作方式。我们修订后的方法是:
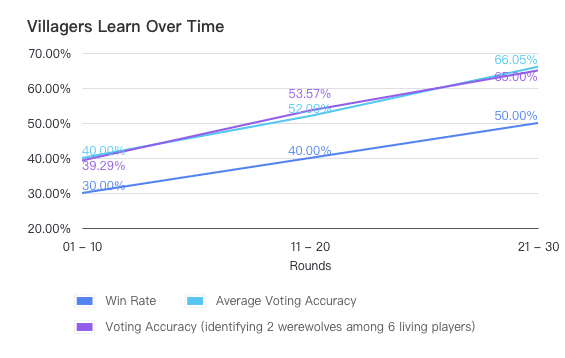
在实践中,我们发现这种方法相当有效。遵循论文的实验设置,我们进行了30轮的实验。在前10轮中,村民方没有过去的经验;在第11轮到第20轮中,村民方可以接触到前10轮的经验;在第21轮到第30轮中,村民方可以接触到前20轮的经验。当然,本次实验中,我们停止了狼人获得经验的能力,以此更好地来观察村民方的结果。
下面是性能提升的图表。随着经验的积累,村民方对抗狼人的胜率逐渐增加。我们还检查了村民在识别狼人方面的平均投票准确率。上升的趋势表明,当村民拥有经验时,他们的判断更为准确,从而证实了他们提高的胜率不仅仅是偶然事件的结果。此外,由于投票准确率还取决于投票的难度,因此我们还评估了在一个固定情景下的准确率:在一组6名幸存玩家中识别2名狼人,这通常是在投票的第一天面临的情况。这一趋势与平均投票准确率的趋势相吻合。
python examples/werewolf_game/start_game.py # use default arguments
python examples/werewolf_game/start_game.py \\\\
--use_reflection True \\\\
--use_experience False \\\\
--use_memory_selection False \\\\
--new_experience_version "01-10" \\\\
--add_human False
# use_reflection: switch to False to disable reflection, this can reduce token costs
# use_experience: switch to True to supply agents with experience, this requires recording experiences first
# use_memory_selection: switch to True to select only recent and informative messages from memory
# new_experience_version: specify a version to record the current run as experience
# add_human: switch to True to participate in the game
我们建议使用GPT-4运行代码。平均而言,如果不使用反思,每次运行大约需要1.5美元,如果使用反思,则需要4美元,如果使用反思和经验学习,则需要7美元。
这是由来自MetaGPT社区的mannaandpoem、davidlee21和ariayyy作为核心贡献者合作努力的成果。当然,我们还要十分感谢Elfe、chaleeluo、kevin-meng和Shutian也提供了宝贵的见解。我们对他们的奉献心存感激。我们热烈邀请更多社区成员加入并为我们的MetaGPT项目做出贡献!

微信关注我们
转载内容版权归作者及来源网站所有!
低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
为解决软件依赖安装时官方源访问速度慢的问题,腾讯云为一些软件搭建了缓存服务。您可以通过使用腾讯云软件源站来提升依赖包的安装速度。为了方便用户自由搭建服务架构,目前腾讯云软件源站支持公网访问和内网访问。
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Rocky Linux(中文名:洛基)是由Gregory Kurtzer于2020年12月发起的企业级Linux发行版,作为CentOS稳定版停止维护后与RHEL(Red Hat Enterprise Linux)完全兼容的开源替代方案,由社区拥有并管理,支持x86_64、aarch64等架构。其通过重新编译RHEL源代码提供长期稳定性,采用模块化包装和SELinux安全架构,默认包含GNOME桌面环境及XFS文件系统,支持十年生命周期更新。
WebStorm 是jetbrains公司旗下一款JavaScript 开发工具。目前已经被广大中国JS开发者誉为“Web前端开发神器”、“最强大的HTML5编辑器”、“最智能的JavaScript IDE”等。与IntelliJ IDEA同源,继承了IntelliJ IDEA强大的JS部分的功能。
扫码在手机上查看文章
扫描二维码,手机阅读更方便
有任何问题或合作意向欢迎联系我们
Email: 99873273@qq.com
QQ: 99873273