Hello world, this is CodeFuse!
2023 年 9 月 8 日下午,在上海举行的“2023 inclusion·外滩大会--云端 Al:探索新兴技术和发展模式”论坛上,蚂蚁集团首次开源了代码大模型 CodeFuse。这是蚂蚁自研的代码生成专属大模型,根据开发者的输入,帮助开发者自动生成代码、自动增加注释、自动生成测试用例、修复和优化代码等,以提升研发效率。无论用户是初学者还是有经验的开发者,CodeFuse 都能够极大地提高编程效率和准确性。
CodeFuse 的目的是重新定义下一代AI研发,提供全生命周期AI辅助工具。蚂蚁集团期望通过开源 CodeFuse,和社区一起推进软件工程领域的范式跃迁,重塑软件研发的各个领域,加速各行各业的数字化进程。
CodeFuse 基于蚂蚁基础大模型平台研发,在近期代码补全的 HumanEval 评测中,其得分达到74.4%,超过了 GPT-4 (67%)的成绩,也超过了 WizardCoder-34B 73.2% 的得分,在开源模型中位于国际前列。本次开源内容包括代码框架、数据集和模型三大部分。
代码仓库现已上架 GitHub 平台 ,数据和模型已上架 HuggingFace 平台和国内的魔搭社区。
GitHub 地址:https://github.com/codefuse-ai
HuggingFace 地址:https://huggingface.co/codefuse-ai
魔搭社区地址:https://modelscope.cn/organization/codefuse-ai
特别的,我们开源了一套多任务微调框架 MFTCoder (https://github.com/codefuse-ai/MFTCoder),支持当前众多主流大模型并支持 Lora 与 QLora 高效微调,欢迎大家试用在私有数据上打造自己的专属代码大模型,并请给我们的项目一键三连支持 Star + Fork + Watch。
首先我们来看一下,CodeFuse 能做什么。
01 贪吃蛇游戏生成
早在 2022 年 1 月,蚂蚁集团内部开启了代码智能相关探索。随着公司整体战略的推进,在统一软硬件基础设施支持下,2023 年从 0 到 1 训练了多个代码大模型,打造了 CodeFuse。基于 CodeFuse 的应用场景有开 IDE 插件、发助手、代码分析器等,覆盖了目前研发工作的主要需求,并在蚂蚁集团内部研发流程中陆续得到验证。
接下来,给大家演示一下,基于蚂蚁开源模型 CodeFuse-CodeLlaMa34B,利用 HTML 和 JavaScript 在线制作贪吃蛇小游戏的场景。
点击查看:https://cloud.video.taobao.com/play/u/null/p/1/e/6/t/1/432865958134.mp4
02 多任务微调框架 MFTCoder
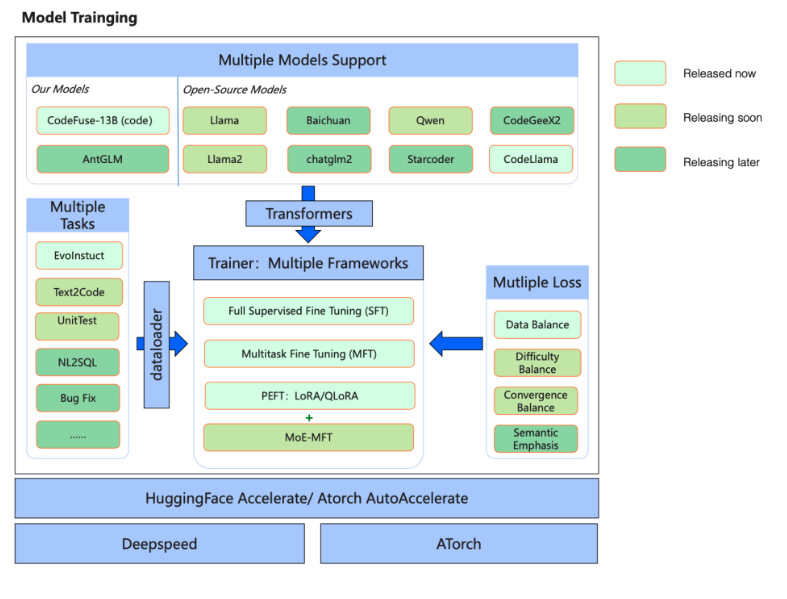
整个 CodeFuse 框架如下图所示,大致分为底层的分布式训练、中间层的指令微调框架,和顶层的多模型应用支持。
![]()
在底层,CodeFuse 支持 DeepSpeed 和蚂蚁自研的 ATorch 两种分布式训练框架。
ATorch 开源地址:https://github.com/intelligent-machine-learning/dlrover/tree/master/atorch
在中间层,CodeFuse 包含了自研的多任务微调(Multi-task fine-tuning,缩写为MFT)框架。MFT 支持代码生成、代码翻译、测试用例生成、bug 修复等数 10 个任务一起微调,它充分利用多任务之间的信息互补,通过创新的 loss 设计处理不同任务之间收敛难易不均衡的难题,最终取得比单任务微调 SFT 更好的效果。MFT 框架最大的特色是,同时支持多任务、多框架,以及多种类型的损失函数:
-
✅ 多任务:一个模型同时支持多个任务,会保证多个任务之间的平衡,甚至可以泛化到新的没有见过的任务上去;
-
✅ 多框架:同时支持 HuggingFace 和 ATorch 框架两个训练框架;
-
✅ 高效微调:支持 LoRA 和 QLoRA,可以用很少的资源去微调很大的模型,且训练速度能满足几乎所有微调场景;
-
✅ 多损失函数:支持数据集大小平衡,任务难度平衡,收敛速度不一平衡,和语义强调等多种不同损失函数。
在顶层,CodeFuse 支持最新的多个开源模型,包括 LlaMA,LlaMa-2,StarCoder,Baichuan,Qwen,Chatglm2,GPT-neox 等。CodeFuse 已经开源了多任务微调框架 MFTCoder。
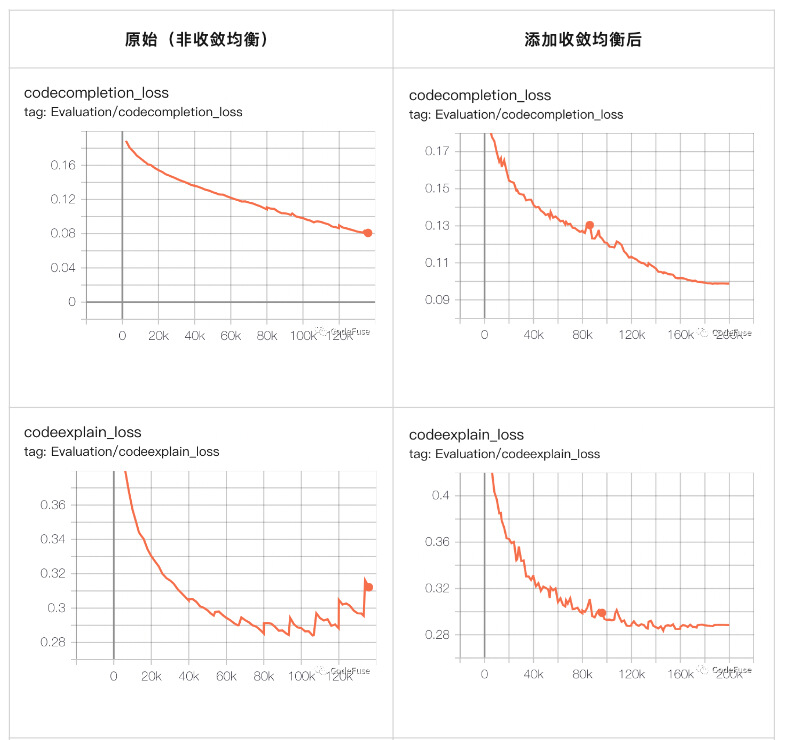
关于多任务难度或者收敛不一致问题,这里给大家展示一个对比的例子。在三个任务(code completion,code explain,text2sql)的微调训练中,添加收敛均衡和不添加收敛均衡以后,validation loss 的收敛状况:可以看到没有添加收敛均衡的时候,三个任务收敛的速度各不相同,code completion 还没有收敛,剩下两个任务已经发散了;然而在加了收敛均衡的限制以后,我们可以明确的看到三个任务的收敛速度一致。
![]()
![]()
03 优秀的多任务微调能力
下面,我们直接给出基于 MFTCoder,给多个开源模型微调代码能力,在 HumanEval 的 Python 补全上的结果。
![]()
可以看到,MFT 在各种底座上对于 Python Pass@1 就可以带来带来 10% 左右的提升。在 StarCoder 和 CodeLLama 上的增益更多。作为对比,已经公开的 HumanEval 榜单中目前排名前列的模型,我们也灰底展示在表格下方。
MFT 微调的 CodeLLaMA-34B,在 HumanEval 上取得了 74.4% 的结果(和 CodeLLaMA 一样,基于 greedy generation 模式评测),该结果超过了 GPT-4 (67%) 的成绩,也超过了 WizardCoder-34B 73.2% 的得分,在开源模型中位于国际前列。
04 4bit 量化部署
CodeFuse-CodeLLama-34B模型表现十分显著,但是34B的模型大小,在FP16和INT8精度下,至少需要一张A100或者4张A10做最小配置部署。如此高的部署资源要求,让个人/普通用户望而却步,即便大公司的大规模部署也比较吃资源。
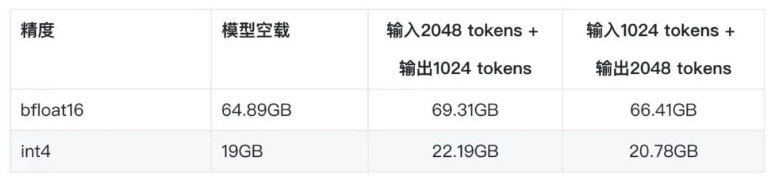
针对此,我们借助量化技术对原模型进行了INT4量化,量化后模型占用显存大小显著减小:64.9G减到19G)。**这样一张A10或者4090 (24GB显存)即可部署。速度方面,实测发现A10上的INT4优化后的推理速度,已经和A100上FP16推理速度持平。**量化部署,可以使用GPTQ或者Nvidia TensorRT-LLM early access版本。
我们评测了量化前后模型能力的差异,其中关键评测HumanEval指标上是73.8%,下降小于1%;NLP任务中文语言理解CMNLI/C-Eval评测得分下降也控制1%左右。
![]()
此外,我们测量了模型加载后占用的显存占用情况,以及输入2048/1024 tokens并输出1024/2048 tokens时的显存使用情况,如下表所示。可以看到,在A10上,4bit量化支持总长为3K长度的输入和输出是没有问题的。
![]()
我们已经在Huggingface、ModelScope、Wisemodel等源发布该量化版本,欢迎大家试用!
05 总结和展望
这里我们介绍了 CodeFuse 整体开源相关的信息,并介绍了一下其中的 MFT 框架。大家有兴趣的话可以去 ModelScope 魔搭社区注册在线体验 CodeFuse-CodeLlama-34B 的效果。
地址:https://modelscope.cn/organization/codefuse-ai
未来我们将贡献更多技术到 CodeFuse 开源社区,也期待有兴趣的同行一起参与进来,给 CodeFuse 开源增砖添瓦。
![]()