#ifndef _ATOM_OPT_H___
#define _ATOM_OPT_H___
#ifdef __GNUC__
#define CAS(a_ptr, a_oldVal, a_newVal) __sync_bool_compare_and_swap(a_ptr, a_oldVal, a_newVal)
#define AtomicAdd(a_ptr,a_count) __sync_fetch_and_add (a_ptr, a_count)
#define AtomicSub(a_ptr,a_count) __sync_fetch_and_sub (a_ptr, a_count)
#include <sched.h> // sched_yield()
#else
#include <Windows.h>
#ifdef _WIN64
#define CAS(a_ptr, a_oldVal, a_newVal) (a_oldVal == InterlockedCompareExchange64(a_ptr, a_newVal, a_oldVal))
#define sched_yield() SwitchToThread()
#define AtomicAdd(a_ptr, num) InterlockedIncrement64(a_ptr)
#define AtomicSub(a_ptr, num) InterlockedDecrement64(a_ptr)
#else
#define CAS(a_ptr, a_oldVal, a_newVal) (a_oldVal == InterlockedCompareExchange(a_ptr, a_newVal, a_oldVal))
#define sched_yield() SwitchToThread()
#define AtomicAdd(a_ptr, num) InterlockedIncrement(a_ptr)
#define AtomicSub(a_ptr, num) InterlockedDecrement(a_ptr)
#endif
#endif
#endif
template <typename ELEM_T, QUEUE_INT Q_SIZE>
inline QUEUE_INT ArrayLockFreeQueue<ELEM_T, Q_SIZE>::countToIndex(QUEUE_INT a_count)
{
return (a_count % Q_SIZE); // 取余的时候
}
template <typename ELEM_T, QUEUE_INT Q_SIZE>
bool ArrayLockFreeQueue<ELEM_T, Q_SIZE>::enqueue(const ELEM_T &a_data)
{
QUEUE_INT currentWriteIndex; // 获取写指针的位置
QUEUE_INT currentReadIndex;
// 1. 获取可写入的位置
do
{
currentWriteIndex = m_writeIndex;
currentReadIndex = m_readIndex;
if(countToIndex(currentWriteIndex + 1) ==
countToIndex(currentReadIndex))
{
return false; // 队列已经满了
}
// 目的是为了获取一个能写入的位置
} while(!CAS(&m_writeIndex, currentWriteIndex, (currentWriteIndex+1)));
// 获取写入位置后 currentWriteIndex 是一个临时变量,保存我们写入的位置
// We know now that this index is reserved for us. Use it to save the data
m_thequeue[countToIndex(currentWriteIndex)] = a_data; // 把数据更新到对应的位置
// 2. 更新可读的位置,按着m_maximumReadIndex+1的操作
// update the maximum read index after saving the data. It wouldn't fail if there is only one thread
// inserting in the queue. It might fail if there are more than 1 producer threads because this
// operation has to be done in the same order as the previous CAS
while(!CAS(&m_maximumReadIndex, currentWriteIndex, (currentWriteIndex + 1)))
{
// this is a good place to yield the thread in case there are more
// software threads than hardware processors and you have more
// than 1 producer thread
// have a look at sched_yield (POSIX.1b)
sched_yield(); // 当线程超过cpu核数的时候如果不让出cpu导致一直循环在此。
}
AtomicAdd(&m_count, 1);
return true;
}
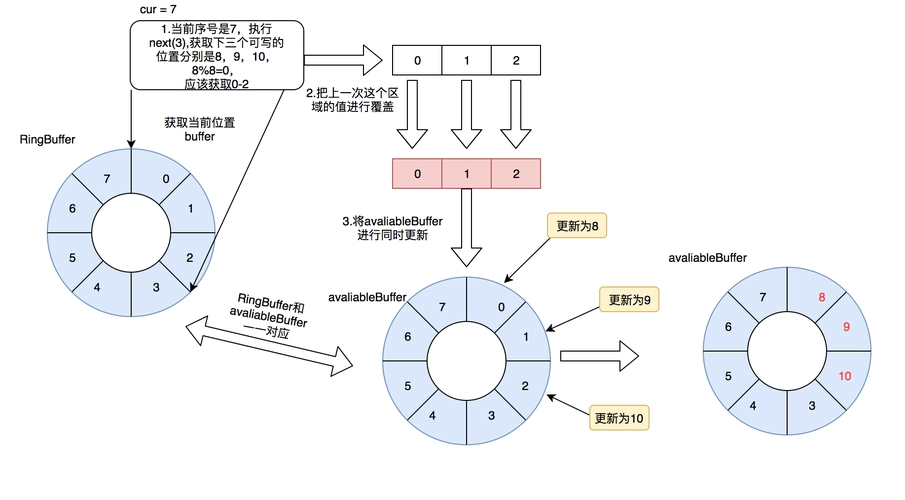
分析:
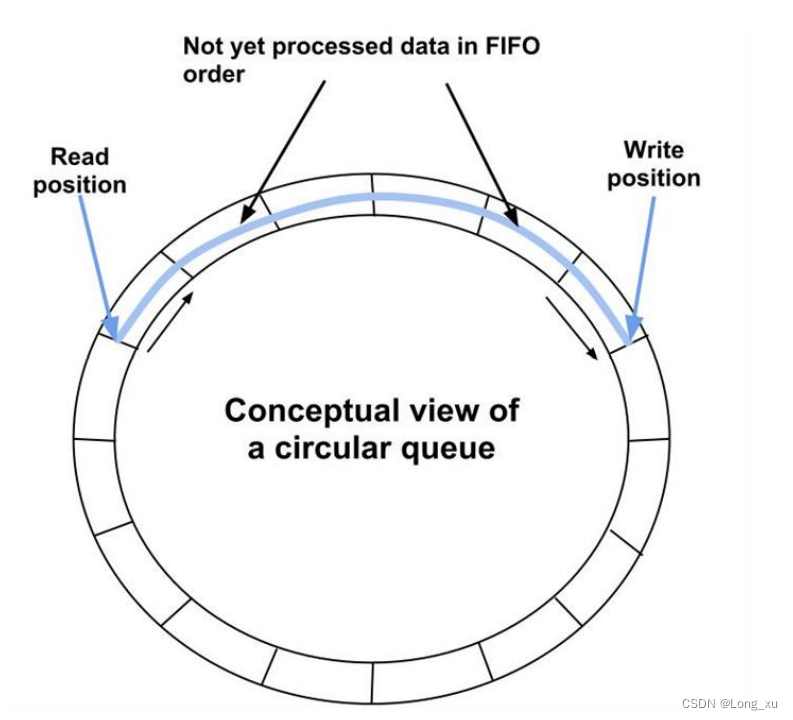
(1)对于下图,队列中存放了两个元素。WriteIndex指示的位置是新元素将会被插入的位置。ReadIndex指向的位置中的元素将会在下一次pop操作中被弹出。
![]()
(2)当生产者准备将数据插入到队列中,它首先通过增加WriteIndex的值来申请空间。MaximumReadIndex指向最后一个存放有效数据的位置(也就是实际的队列尾)。
![]()
(3)一旦空间的申请完成,生产者就可以将数据拷贝到刚刚申请到的位置中。完成之后增加MaximumReadIndex使得它与WriteIndex的一致。
![]()
(4)现在队列中有3个元素,接着又有一个生产者尝试向队列中插入元素。
![]()
(5)在第一个生产者完成数据拷贝之前,又有另外一个生产者申请了一个新的空间准备拷贝数据。现在有两个生产者同时向队列插入数据。
![]()
(6)现在生产者开始拷贝数据,在完成拷贝之后,对MaximumReadIndex的递增操作必须严格遵循一个顺序:**第一个生产者线程首先递增MaximumReadIndex,接着才轮到第二个生产者。** 这个顺序必须被严格遵守的原因是,我们必须**保证数据被完全拷贝到队列之后才允许消费者线程将其出列**。
第一个生产者完成了数据拷贝,并对MaximumReadIndex完成了递增。
![]()
(7)现在第二个生产者可以递增MaximumReadIndex了;第二个生产者完成了对MaximumReadIndex的递增,现在队列中有5个元素。
![]()
4.2、dequeue出队列
template <typename ELEM_T, QUEUE_INT Q_SIZE>
bool ArrayLockFreeQueue<ELEM_T, Q_SIZE>::dequeue(ELEM_T &a_data)
{
QUEUE_INT currentMaximumReadIndex;
QUEUE_INT currentReadIndex;
do
{
// to ensure thread-safety when there is more than 1 producer thread
// a second index is defined (m_maximumReadIndex)
currentReadIndex = m_readIndex;
currentMaximumReadIndex = m_maximumReadIndex;
if(countToIndex(currentReadIndex) ==
countToIndex(currentMaximumReadIndex)) // 如果不为空,获取到读索引的位置
{
// the queue is empty or
// a producer thread has allocate space in the queue but is
// waiting to commit the data into it
return false;
}
// retrieve the data from the queue
a_data = m_thequeue[countToIndex(currentReadIndex)]; // 从临时位置读取的
// try to perfrom now the CAS operation on the read index. If we succeed
// a_data already contains what m_readIndex pointed to before we
// increased it
if(CAS(&m_readIndex, currentReadIndex, (currentReadIndex + 1)))
{
AtomicSub(&m_count, 1); // 真正读取到了数据,元素-1
return true;
}
} while(true);
assert(0);
// Add this return statement to avoid compiler warnings
return false;
}
分析:
(1)以下插图展示了元素出列的时候各种下标是如何变化的,队列中初始有2个元素。WriteIndex指示的位置是新元素将会被插入的位置。ReadIndex指向的位置中的元素将会在下一次pop操作中被弹出。
![]()
(2)消费者线程拷贝数组ReadIndex位置的元素,然后尝试用CAS操作将ReadIndex加1。如果操作成功消费者成功的将数据出列。因为CAS操作是原子的,所以只有唯一的线程可以在同一时刻更新ReadIndex的值。如果操作失败,读取新的ReadIndex值,以重复以上操作(copy数据,CAS)。
![]()
(3)现在又有一个消费者将元素出列,队列变成空。
![]()
(4)现在有一个生产者正在向队列中添加元素。它已经成功的申请了空间,但尚未完成数据拷贝。任何其它企图从队列中移除元素的消费者都会发现队列非空(因为writeIndex不等于readIndex)。但它不能读取readIndex所指向位置中的数据,因为readIndex与MaximumReadIndex相等。消费者将会在do循环中不断的反复尝试,直到生产者完成数据拷贝增加MaximumReadIndex的值,或者队列变成空(这在多个消费者的场景下会发生)。
![]()
(5)当生产者完成数据拷贝,队列的大小是1,消费者线程可以读取这个数据了。
![]()
4.3、在多于一个生产者线程的情况下“让出”CPU的必要性
enqueue函数中使用了sched_yiedld()来主动的让出CPU,对于一个无锁的算法而言,这个调用看起来有点奇怪。
多线程环境下影响性能的其中一个因素就是Cache损坏。而产生Cache损坏的一种情况就是一个线程被抢占,操作系统需要保存被抢占线程的上下文,然后将被选中作为下一个调度线程的上下文载入。此时Cache中缓存的数据都会失效,因为它是被抢占线程的数据而不是新线程的数据。
所以,当此算法调用sched_yield()意味着告诉操作系统:“我要把处理器时间让给其它线程,因为我要等待某件事情的发生”。无锁算法和通过阻塞机制同步的算法的一个主要区别在于无锁算法不会阻塞在线程同步上。
那么为什么在这里我们要主动请求操作系统抢占自己呢? 它与有多少个生产者线程在并发的往队列中存放数据有关:每个生产者线程所执行的CAS操作都必须严格遵循FIFO次序,一个用于申请空间,另一个用于通知消费者数据已经写入完成可以被读取了。
如果应用程序只有唯一的生产者操作这个队列,sche_yield()将永远没有机会被调用,第2个CAS操作永远不会失败。因为在一个生产者的情况下没有人能破坏生产者执行这两个CAS操作的FIFO顺序。
而当多于一个生产者线程往队列中存放数据的时候,问题就出现了。概括来说,一个生产者通过第1个
CAS操作申请空间,然后将数据写入到申请到的空间中,然后执行第2个CAS操作通知消费者数据准备完毕可供读取了。这第2个CAS操作必须遵循FIFO顺序,也就是说,如果A线程第首先执行完第一个CAS操作,那么它也要第1个执行完第2个CAS操作,如果A线程在执行完第一个CAS操作之后停止,然后B线程执行完第1个CAS操作,那么B线程将无法完成第2个CAS操作,因为它要等待A先完成第2个CAS操作。而这就是问题产生的根源。
五、完整源码
#ifndef _ARRAYLOCKFREEQUEUEIMP_H___
#define _ARRAYLOCKFREEQUEUEIMP_H___
#include "ArrayLockFreeQueue.h"
#include <assert.h>
#include "atom_opt.h"
template <typename ELEM_T, QUEUE_INT Q_SIZE>
ArrayLockFreeQueue<ELEM_T, Q_SIZE>::ArrayLockFreeQueue() :
m_writeIndex(0),
m_readIndex(0),
m_maximumReadIndex(0)
{
m_count = 0;
}
template <typename ELEM_T, QUEUE_INT Q_SIZE>
ArrayLockFreeQueue<ELEM_T, Q_SIZE>::~ArrayLockFreeQueue()
{
}
template <typename ELEM_T, QUEUE_INT Q_SIZE>
inline QUEUE_INT ArrayLockFreeQueue<ELEM_T, Q_SIZE>::countToIndex(QUEUE_INT a_count)
{
return (a_count % Q_SIZE); // 取余的时候
}
template <typename ELEM_T, QUEUE_INT Q_SIZE>
QUEUE_INT ArrayLockFreeQueue<ELEM_T, Q_SIZE>::size()
{
QUEUE_INT currentWriteIndex = m_writeIndex;
QUEUE_INT currentReadIndex = m_readIndex;
if(currentWriteIndex>=currentReadIndex)
return currentWriteIndex - currentReadIndex;
else
return Q_SIZE + currentWriteIndex - currentReadIndex;
}
template <typename ELEM_T, QUEUE_INT Q_SIZE>
bool ArrayLockFreeQueue<ELEM_T, Q_SIZE>::enqueue(const ELEM_T &a_data)
{
QUEUE_INT currentWriteIndex; // 获取写指针的位置
QUEUE_INT currentReadIndex;
// 1. 获取可写入的位置
do
{
currentWriteIndex = m_writeIndex;
currentReadIndex = m_readIndex;
if(countToIndex(currentWriteIndex + 1) ==
countToIndex(currentReadIndex))
{
return false; // 队列已经满了
}
// 目的是为了获取一个能写入的位置
} while(!CAS(&m_writeIndex, currentWriteIndex, (currentWriteIndex+1)));
// 获取写入位置后 currentWriteIndex 是一个临时变量,保存我们写入的位置
// We know now that this index is reserved for us. Use it to save the data
m_thequeue[countToIndex(currentWriteIndex)] = a_data; // 把数据更新到对应的位置
// 2. 更新可读的位置,按着m_maximumReadIndex+1的操作
// update the maximum read index after saving the data. It wouldn't fail if there is only one thread
// inserting in the queue. It might fail if there are more than 1 producer threads because this
// operation has to be done in the same order as the previous CAS
while(!CAS(&m_maximumReadIndex, currentWriteIndex, (currentWriteIndex + 1)))
{
// this is a good place to yield the thread in case there are more
// software threads than hardware processors and you have more
// than 1 producer thread
// have a look at sched_yield (POSIX.1b)
sched_yield(); // 当线程超过cpu核数的时候如果不让出cpu导致一直循环在此。
}
AtomicAdd(&m_count, 1);
return true;
}
template <typename ELEM_T, QUEUE_INT Q_SIZE>
bool ArrayLockFreeQueue<ELEM_T, Q_SIZE>::try_dequeue(ELEM_T &a_data)
{
return dequeue(a_data);
}
template <typename ELEM_T, QUEUE_INT Q_SIZE>
bool ArrayLockFreeQueue<ELEM_T, Q_SIZE>::dequeue(ELEM_T &a_data)
{
QUEUE_INT currentMaximumReadIndex;
QUEUE_INT currentReadIndex;
do
{
// to ensure thread-safety when there is more than 1 producer thread
// a second index is defined (m_maximumReadIndex)
currentReadIndex = m_readIndex;
currentMaximumReadIndex = m_maximumReadIndex;
if(countToIndex(currentReadIndex) ==
countToIndex(currentMaximumReadIndex)) // 如果不为空,获取到读索引的位置
{
// the queue is empty or
// a producer thread has allocate space in the queue but is
// waiting to commit the data into it
return false;
}
// retrieve the data from the queue
a_data = m_thequeue[countToIndex(currentReadIndex)]; // 从临时位置读取的
// try to perfrom now the CAS operation on the read index. If we succeed
// a_data already contains what m_readIndex pointed to before we
// increased it
if(CAS(&m_readIndex, currentReadIndex, (currentReadIndex + 1)))
{
AtomicSub(&m_count, 1); // 真正读取到了数据,元素-1
return true;
}
} while(true);
assert(0);
// Add this return statement to avoid compiler warnings
return false;
}
#endif
源码测试
#include "ArrayLockFreeQueue.h"
ArrayLockFreeQueue<int> arraylockfreequeue;
void *arraylockfreequeue_producer_thread(void *argv)
{
PRINT_THREAD_INTO();
int count = 0;
int write_failed_count = 0;
for (int i = 0; i < s_queue_item_num;)
{
if (arraylockfreequeue.enqueue(count)) // enqueue的顺序是无法保证的,我们只能计算enqueue的个数
{
count = lxx_atomic_add(&s_count_push, 1);
i++;
}
else
{
write_failed_count++;
// printf("%s %lu enqueue failed, q:%d\n", __FUNCTION__, pthread_self(), arraylockfreequeue.size());
sched_yield();
// usleep(10000);
}
}
// printf("%s %lu write_failed_count:%d\n", __FUNCTION__, pthread_self(), write_failed_count)
PRINT_THREAD_LEAVE();
return NULL;
}
void *arraylockfreequeue_consumer_thread(void *argv)
{
int last_value = 0;
PRINT_THREAD_INTO();
int value = 0;
int read_failed_count = 0;
while (true)
{
if (arraylockfreequeue.dequeue(value))
{
if (s_consumer_thread_num == 1 && s_producer_thread_num == 1 && (last_value + 1) != value) // 只有一入一出的情况下才有对比意义
{
// printf("pid:%lu, -> value:%d, expected:%d\n", pthread_self(), value, last_value);
}
lxx_atomic_add(&s_count_pop, 1);
last_value = value;
}
else
{
read_failed_count++;
// printf("%s %lu no data, s_count_pop:%d, value:%d\n", __FUNCTION__, pthread_self(), s_count_pop, value);
// usleep(100);
sched_yield();
}
if (s_count_pop >= s_queue_item_num * s_producer_thread_num)
{
// printf("%s dequeue:%d, s_count_pop:%d, %d, %d\n", __FUNCTION__, last_value, s_count_pop, s_queue_item_num, s_consumer_thread_num);
break;
}
}
// printf("%s %lu read_failed_count:%d\n", __FUNCTION__, pthread_self(), read_failed_count)
PRINT_THREAD_LEAVE();
return NULL;
}
总结
- 基于循环数组的无锁队列ArrayLockFreeQueue相实现对简单。
- 无锁消息队列适用于10w+每秒的数据吞吐以及数据操作耗时较少场景。
- currentMaximumReadIndex表示其之前的数据可以读取,本身所在的位置不可读取。