大家好,我是来自 BOSS直聘的赵俊南,主要负责安全方面的图存储相关工作。作为一个从 v1.x 用到 v3.x 版本的忠实用户,在见证 NebulaGraph 发展的同时,也和它一起成长。
BOSS直聘和 NebulaGraph
关于 NebulaGraph 在 BOSS直聘的应用场景,大家可以看看之前文洲老师的文章(图数据库 NebulaGraph 在 BOSS直聘的应用),从那时候文洲老师构建的行为图发展到了安全场景的业务主图、算法推理图、职位相似度图谱等业务,现在更是支持了数仓同学的数据血缘及搜索同学的实时搜索召回场景,单图的规模达到了数千亿。
在图计算方面,BOSS 直聘基于 LPA 和 Louvain 的单度团、多维团,以及基础的离线特征,在安全生产环境中广泛应用图技术。相信未来图在 BOSS直聘还会有更为宽广的舞台。
UDF 的萌生
随着 NebulaGraph 在 BOSS直聘业务上的广泛应用,相对应的对内部技术人员的要求也越来越高。如果技术人员仅仅停留在使用层面,就无法满足从功能到性能很多需求。所以,学习源码成为了必然。
而后迁移 Neo4j->NebulaGraph 过程中,发现业务对 Neo4j 的 UDF 包有所依赖,我本萌生了实现 NebulaGraph UDF 功能的念头。
UDF 设计和实现原理
![]()
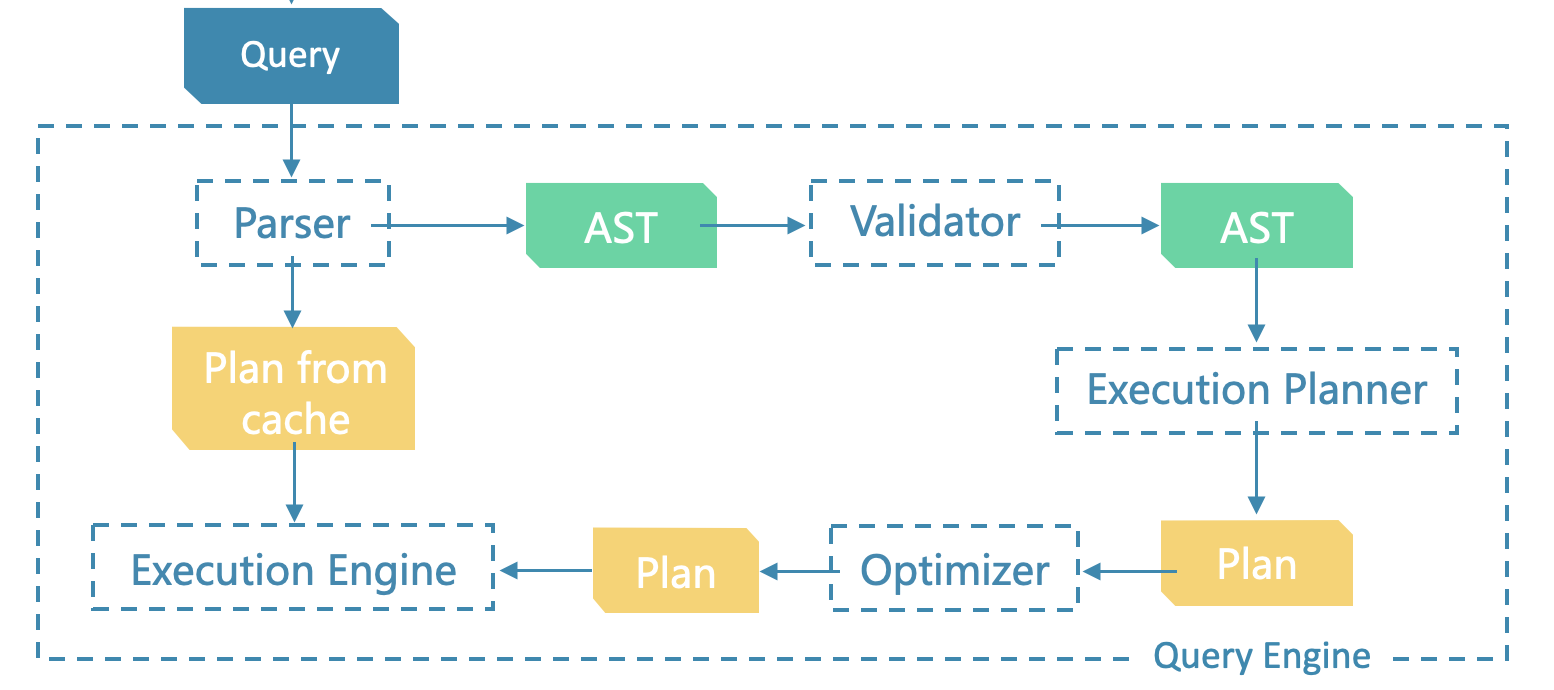
上图是一条完整 nGQL 语句的执行过程,而 UDF 实现原理同 nGQL 的执行流程相关,大致如下:
graphd 接收到语句 -> Bison 词法解析(切词) -> Flex 语法解析创建 Sentence -> Validator 校验并生成AstContext(抽象语法树) -> toPlan 生成执行计划 Planner -> Optimizer 优化器优化 -> Executor 执行器执行。
在词法语法解析阶段,Function 会被单独解析出来。FunctionManager 作为原生的内置函数管理者,负责函数的定义、加载、调用等操作,从而管理函数的整个生命周期。调用语句通过 FunctionManager 查找到的函数最终会被执行器调用执行。
NebulaGraph 的 UDF 实现基于函数的调用执行流程,增加了 FunctionUdfManager:
static std::unordered_map<std::string, Value::Type> udfFunReturnType_;
static std::unordered_map<std::string, std::vector<std::vector<nebula::Value::Type>>>
udfFunInputType_;
std::unordered_map<std::string, FunctionManager::FunctionAttributes> udfFunctions_;
class FunctionUdfManager {
public:
typedef GraphFunction *(create_f)();
typedef void(destroy_f)(GraphFunction *);
static StatusOr<Value::Type> getUdfReturnType(const std::string functionName,
const std::vector<Value::Type> &argsType);
static StatusOr<const FunctionManager::FunctionAttributes> loadUdfFunction(
std::string functionName, size_t arity);
static FunctionUdfManager &instance();
FunctionUdfManager();
private:
static create_f *getGraphFunctionClass(void *func_handle);
static destroy_f *deleteGraphFunctionClass(void *func_handle);
void addSoUdfFunction(char *funName, const char *soPath, size_t i, size_t i1, bool b);
void initAndLoadSoFunction();
};
它主要做以下几件事:
- 和 FunctionManager 一起初始化,initAndLoadSoFunction 开启定时扫描,扫描
--udf_path 路径下文件;
- loadUdfFunction加载
.so 文件,实例化函数方法,以函数名为 key 保存在 Map 中;
- 在启用 UDF 功能的情况下,FunctionManager 未查找函数时,查找并调用 FunctionUdfManager Map 中的函数。
实现比较简单,可以说是取巧了,有需要的话 UDAF 也可用类似方式实现。
UDF 使用方法
下面来讲讲 NebulaGraph UDF 的具体使用,如果你是用 NebulaGraph v3.5.0+ 版本的话,就可以按照以下方式使用 UDF 功能了。如果你是 v3.4.x 及以下版本,UDF 功能是暂不支持的,你也可以 cherry-pick 这个 pr 自行编译使用 UDF 功能。
第一步,在 graphd 配置文件中开启 UDF 功能并指定包目录
# enable udf, c++ only
--enable_udf=true
# set the directory where the .so of udf are stored
--udf_path=/home/foobar/dev/nebula/udf/
第二步,编写自定义函数代码,继承 GraphFunction。GraphFunction 的结构如下:
class GraphFunction;
extern "C" GraphFunction *create();
extern "C" void destroy(GraphFunction *function);
class GraphFunction {
public:
virtual ~GraphFunction() = default;
virtual char *name() = 0;
virtual std::vector<std::vector<nebula::Value::Type>> inputType() = 0;
virtual nebula::Value::Type returnType() = 0;
virtual size_t minArity() = 0;
virtual size_t maxArity() = 0;
virtual bool isPure() = 0;
virtual nebula::Value body(
const std::vector<std::reference_wrapper<const nebula::Value>> &args) = 0;
};
- create、destroy 是函数的创建销毁方法;
- name 调用时的函数名;
- inputType、returnType 输入输出类型;
- minArity、maxArity 参数数量;
- isPure 函数是否有状态;
- body 函数的实现。
第三步,编写好的函数打包成(.so)文件,放到配置文件 --udf_path 配置的对应目录下,graphd 服务会定时(5 分钟)扫描该路径下的包,加载到函数库中。之后,就可以在自己的语句中调用对应的函数了。
⚠️ 注意:由于 graphd 只扫描本地路径下的函数包,想让多个 graphd 都生效,必须都在本地路径下有相应的包。
这里要 cue 下思为老师,感谢他补充的完整使用文档和编译环境:https://github.com/vesoft-inc/nebula/pull/4804 。
UDF 尚未解决的问题
虽然目前 UDF 是能用,但是它还存在部分优化问题。比如:
- so 包位置只支持扫描本地;
- 函数只在 graphd 层,无法下推到存储;
- 使用麻烦,需要用户编码。
当然这些问题和一开始的设计息息相关:开发 UDF 之初,其实是想兼容 C++ 的 so 包和 Java 的 jar 包,但测试了 C++ Jni 调用 Java 的性能,发现基本上无法用于大规模的生产。
下图便是当时的性能测试:
![]()
因为实现实在是性能堪忧,于是就放弃了一开始的设计。
当然还有一些未来规划上的事情,主要是希望 NebulaGraph 开发团队一起合作完成:
- 个别的大查询语句和深度查询,容易把 storaged 的内存打满影响集群整体性能。是否可以考虑通过查询时间超时或内存监控自动 kill 对应的查询,释放掉内存。其实对于类似的语句,基本上已经很难拿到结果了,更多的可能是想降低语句带来的影响
- 集群的容错性,多副本情况下某个节点的非正常下线会影响整体集群,由于环境的复杂性具体定位分析也比较困难,盼望尽可能增强集群健壮性。
开发 UDF 的意外收获
前面说过,UDF 其实是阅读 NebulaGraph 源码的产物。这里我想谈谈我对源码阅读感受:整体的 NebulaGraph 源码给我最直观的感受就是层次、结构清晰,代码优雅。在配合官方博客提供的内核讲解系列文章,对我这种跨语言学习的选手难度都大大降低了。
希望 UDF 能帮你解决一些问题,以及我的分享能给你带来一丝启发。
谢谢你读完本文 (///▽///)
如果你想尝鲜图数据库 NebulaGraph,记得去 GitHub 下载、使用、(^з^)-☆ star 它 -> GitHub;和其他的 NebulaGraph 用户一起交流图数据库技术和应用技能,留下「你的名片」一起玩耍呀~
2023 年 NebulaGraph 技术社区年度征文活动正在进行中,来这里领取华为 Meta 60 Pro、Switch 游戏机、小米扫地机器人等等礼品哟~ 活动链接:https://discuss.nebula-graph.com.cn/t/topic/13970
![]()