![]()
引言
我们很高兴地宣布由 Technology Innovation Institute (TII) 训练的开源大模型 Falcon 180B 登陆 Hugging Face! Falcon 180B 为开源大模型树立了全新的标杆。作为当前最大的开源大模型,有180B 参数并且是在在 3.5 万亿 token 的 TII RefinedWeb 数据集上进行训练,这也是目前开源模型里最长的单波段预训练。
你可以在 Hugging Face Hub 中查阅模型以及其 Space 应用。
模型:
https://hf.co/tiiuae/falcon-180B
https://hf.co/tiiuae/falcon-180B-chat
Space 应用地址:
https://hf.co/spaces/tiiuae/falcon-180b-demo
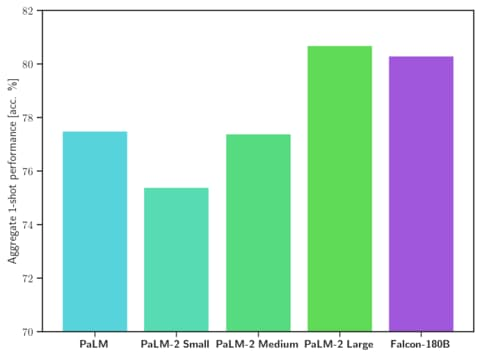
从表现能力上来看,Falcon 180B 在自然语言任务上的表现十分优秀。它在开源模型排行榜 (预训练) 上名列前茅,并可与 PaLM-2 等专有模型相差无几。虽然目前还很难给出明确的排名,但它被认为与 PaLM-2 Large 不相上下,这也使得它成为目前公开的能力最强的 LLM 之一。
我们将在本篇博客中通过评测结果来探讨 Falcon 180B 的优势所在,并展示如何使用该模型。
Falcon 180B 是什么?
从架构维度来看,Falcon 180B 是 Falcon 40B 的升级版本,并在其基础上进行了创新,比如利用 Multi-Query Attention 等来提高模型的可扩展性。可以通过回顾 Falcon 40B 的博客 Falcon 40B 来了解其架构。Falcon 180B 是使用 Amazon SageMaker 在多达 4096 个 GPU 上同时对 3.5 万亿个 token 进行训练,总共花费了约 7,000,000 个 GPU 计算时,这意味着 Falcon 180B 的规模是 Llama 2 的 2.5 倍,而训练所需的计算量是 Llama 2 的 4 倍。
其训练数据主要来自 RefinedWeb 数据集 (大约占 85%),此外,它还在对话、技术论文和一小部分代码 (约占 3%) 等经过整理的混合数据的基础上进行了训练。这个预训练数据集足够大,即使是 3.5 万亿个标记也只占不到一个时期 (epoch)。
已发布的 聊天模型 在对话和指令数据集上进行了微调,混合了 Open-Platypus、UltraChat 和 Airoboros 数据集。
‼️ 商业用途: Falcon 180b 可用于商业用途,但条件非常严格,不包括任何“托管用途”。如果您有兴趣将其用于商业用途,我们建议您查看 许可证 并咨询您的法律团队。
Falcon 180B 的优势是什么?
Falcon 180B 是当前最好的开源大模型。在 MMLU上 的表现超过了 Llama 2 70B 和 OpenAI 的 GPT-3.5。在 HellaSwag、LAMBADA、WebQuestions、Winogrande、PIQA、ARC、BoolQ、CB、COPA、RTE、WiC、WSC 及 ReCoRD 上与谷歌的 PaLM 2-Large 不相上下。
![]()
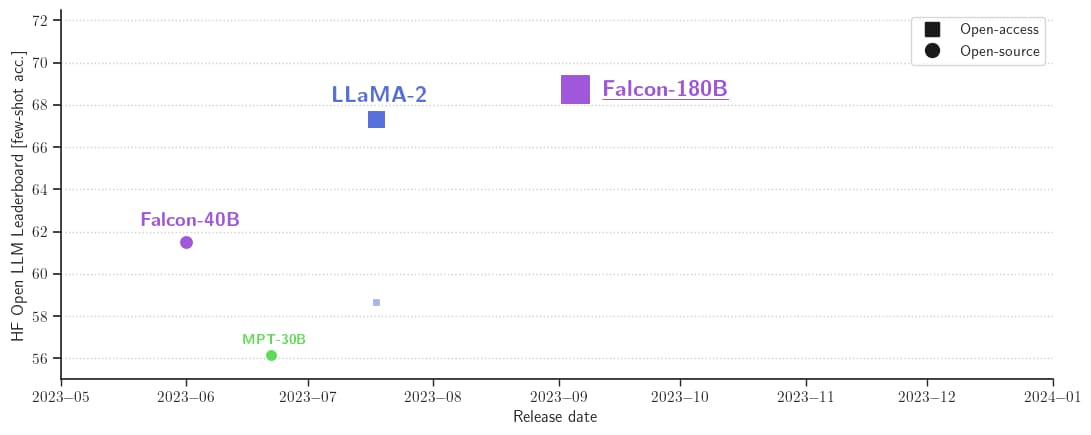
它在 Hugging Face 开源大模型榜单上以 68.74 的成绩被认为是当前评分最高的开放式大模型,评分超过了 Meta 的 LlaMA 2 (67.35)。
| Model |
Size |
Leaderboard score |
Commercial use or license |
Pretraining length |
| Falcon |
180B |
68.74 |
🟠 |
3,500B |
| Llama 2 |
70B |
67.35 |
🟠 |
2,000B |
| LLaMA |
65B |
64.23 |
🔴 |
1,400B |
| Falcon |
40B |
61.48 |
🟢 |
1,000B |
| MPT |
30B |
56.15 |
🟢 |
1,000B |
![]()
如何使用 Falcon 180B?
从 Transfomers 4.33 开始,Falcon 180B 可以在 Hugging Face 生态中使用和下载。
Demo
你可以在 这个 Hugging Face Space 或以下场景中体验 Falcon 180B 的 demo。
![]()
硬件要求
|
类型 |
种类 |
最低要求 |
配置示例 |
| Falcon 180B |
Training |
Full fine-tuning |
5120GB |
8x 8x A100 80GB |
| Falcon 180B |
Training |
LoRA with ZeRO-3 |
1280GB |
2x 8x A100 80GB |
| Falcon 180B |
Training |
QLoRA |
160GB |
2x A100 80GB |
| Falcon 180B |
Inference |
BF16/FP16 |
640GB |
8x A100 80GB |
| Falcon 180B |
Inference |
GPTQ/int4 |
320GB |
8x A100 40GB |
Prompt 格式
其基础模型没有 Prompt 格式,因为它并不是一个对话型大模型也不是通过指令进行的训练,所以它并不会以对话形式回应。预训练模型是微调的绝佳平台,但或许你不该直接使用。其对话模型则设有一个简单的对话模式。
System: Add an optional system prompt here
User: This is the user input
Falcon: This is what the model generates
User: This might be a second turn input
Falcon: and so on
Transformers
随着 Transfomers 4.33 发布,你可以在 Hugging Face 上使用 Falcon 180B 并且借助 HF 生态里的所有工具,比如: 训练和推理脚本及示例 安全文件格式 (safetensor) 与 bitsandbytes (4 位量化)、PEFT (参数高效微调) 和 GPTQ 等工具集成 辅助生成 (也称为“推测解码”) RoPE 扩展支持更大的上下文长度 丰富而强大的生成参数 在使用这个模型之前,你需要接受它的许可证和使用条款。请确保你已经登录了自己的 Hugging Face 账号,并安装了最新版本的 transformers:
pip install --upgrade transformers
huggingface-cli login
bfloat16
以下是如何在 bfloat16 中使用基础模型的方法。Falcon 180B 是一个大型模型,所以请注意它的硬件要求。
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "tiiuae/falcon-180B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
prompt = "My name is Pedro, I live in"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
do_sample=True,
temperature=0.6,
top_p=0.9,
max_new_tokens=50,
)
output = output[0].to("cpu")
print(tokenizer.decode(output)
这可能会产生如下输出结果:
My name is Pedro, I live in Portugal and I am 25 years old. I am a graphic designer, but I am also passionate about photography and video.
I love to travel and I am always looking for new adventures. I love to meet new people and explore new places.
使用 8 位和 4 位的 bitsandbytes
Falcon 180B 的 8 位和 4 位量化版本在评估方面与 bfloat16 几乎没有差别!这对推理来说是个好消息,因为你可以放心地使用量化版本来降低硬件要求。请记住,在 8 位版本进行推理要比 4 位版本快得多。 要使用量化,你需要安装“bitsandbytes”库,并在加载模型时启用相应的标志:
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
**load_in_8bit=True,**
device_map="auto",
)
对话模型
如上所述,为跟踪对话而微调的模型版本使用了非常直接的训练模板。我们必须遵循同样的模式才能运行聊天式推理。作为参考,你可以看看聊天演示中的 format_prompt 函数:
def format_prompt(message, history, system_prompt):
prompt = ""
if system_prompt:
prompt += f"System: {system_prompt}\n"
for user_prompt, bot_response in history:
prompt += f"User: {user_prompt}\n"
prompt += f"Falcon: {bot_response}\n"
prompt += f"User: {message}\nFalcon:"
return prompt
如你所见,用户的交互和模型的回应前面都有 User: 和 Falcon: 分隔符。我们将它们连接在一起,形成一个包含整个对话历史的提示。我们可以提供一个系统提示来调整生成风格。
其他资源
鸣谢
在我们的生态中发布并持续支持与评估这样一个模型离不开众多社区成员的贡献,这其中包括 Clémentine 和 Eleuther Evaluation Harness 对 LLM 的评估; Loubna 与 BigCode 对代码的评估; Nicolas 对推理方面的支持; Lysandre、Matt、Daniel、Amy、Joao 和 Arthur 将 Falcon 集成到 transformers 中。感谢 Baptiste 和 Patrick 编写开源示例。感谢 Thom、Lewis、TheBloke、Nouamane 和 Tim Dettmers 鼎力贡献让这些能发布。最后,感谢 HF Cluster 为运行 LLM 推理和一个开源免费的模型 demo 提供的大力支持。