![file]()
DolphinScheduler是一个开源的分布式任务调度系统,拥有分布式架构、多任务类型、可视化操作、分布式调度和高可用等特性,适用于大规模分布式任务调度的场景。目前DolphinScheduler支持的元数据库有Mysql、PostgreSQL、H2,如果在业务中需要更好的性能和扩展性,可以在DolphinScheduler中使用OceanBase数据库作为元数据库进行替换。节点数量和规模可以自由调整,实现无缝扩展和缩减。
一. OceanBase数据库
OceanBase数据库是阿里巴巴自主研发的分布式关系型数据库,具有以下特点:
-
分布式架构:OceanBase采用分布式架构,可水平扩展,支持PB级别的数据存储和处理。
-
高可用性:OceanBase采用分布式副本机制,实现数据的冗余备份,保证在节点故障时仍能提供可用的服务。
-
高性能:OceanBase采用多维度优化技术,包括数据存储、查询优化、分布式事务等方面,可大幅提升数据库的性能。
-
强一致性:OceanBase采用基于Paxos协议的多副本一致性算法,实现强一致性的分布式事务处理。
-
兼容SQL:OceanBase支持标准的SQL语言,包括DDL、DML和DQL等命令。
-
可扩展性:OceanBase支持在线扩容和缩容,可根据业务需求自由调整节点数量和规模。
-
安全性:OceanBase采用多层安全策略,包括密码加密、数据加密、访问控制等,保障数据库的安全性。
总之,OceanBase数据库具有高可用、高性能、强一致性等特性,适用于大规模、高并发的业务场景。
二. DolphinScheduler支持OceanBase数据源
在DolphinScheduler中使用OceanBase做数据源在调度业务上的优势:
-
高性能:OceanBase可以处理大规模数据,而且在数据存储和处理方面都采用了多维度优化技术,所以相对于其他数据库,其有更高的性能表现,可以快速地处理数据。
-
高可靠性:OceanBase是一个分布式数据库,通过多节点的数据冗余备份,当某个节点发生故障时能够自动切换,保证服务的高可靠性。
-
事务处理:如果业务需要原子性的操作,OceanBase可以提供强一致性的分布式事务处理,从而保证数据不会出现不一致的情况。
-
分布式调度:DolphinScheduler自身是分布式任务调度系统,和OceanBase分布式架构相互匹配,可以充分利用Oceanbase的分布式特性,提供更高效率的调度服务。
-
可扩展性:DolphinScheduler和OceanBase都支持在线扩容和缩容,可以根据业务需求自由调整节点数量和规模,实现无缝扩展和缩减。
使用OceanBase作为数据源可以带来高性能、高可靠性、高安全性和强大的扩展性,和DolphinScheduler结合使用,将会为调度业务的稳定性、可靠性、可扩展性带来更优秀的表现。
三. OceanBase具体兼容Mysql的哪些特性
-
数据类型:OceanBase支持MySQL的常见数据类型,如整数、浮点数、日期和时间、字符串等。
-
SQL语法:OceanBase支持MySQL的常见SQL语句,如SELECT、INSERT、UPDATE、DELETE等命令。
-
存储引擎:OceanBase支持InnoDB存储引擎,从而可以兼容MySQL的事务和锁定特性。
-
存储过程:OceanBase支持MySQL的存储过程特性,包括存储过程、存储函数和存储触发器等。
-
工具和驱动:OceanBase支持MySQL的常见工具和驱动,如MySQL Workbench、Navicat和JDBC等。
四. DolphinScheduler更换为OceanBase元数据库的步骤
- 创建OceanBase数据源,包括主机地址、端口号、用户名、密码等信息;
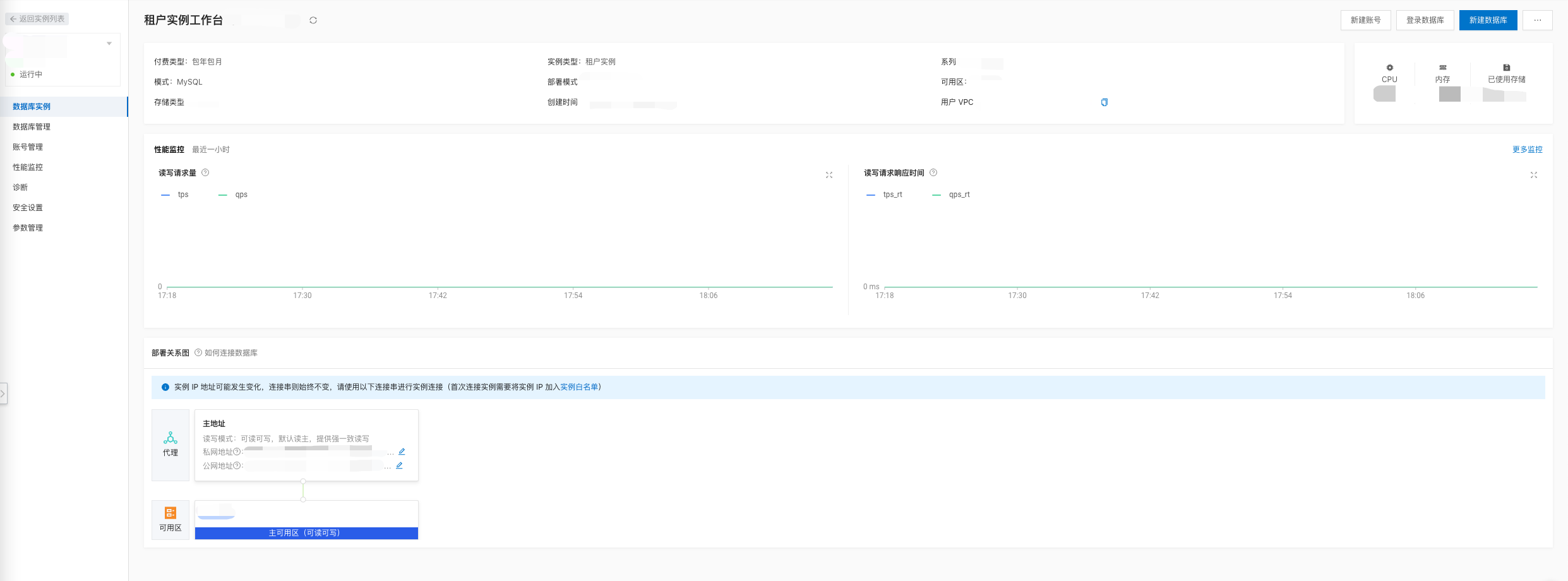
阿里公有云:在阿里云官网申请公有云的OceanBase实例,申请成功后可在控制台-云数据库OceanBase版-实例列表页面看到状态为运行中的实例:
![file]()
进入实例可以看到数据库实例和下方的代理私网、公网地址;右上角可以新建数据库和新建账号,非超级账号需要在账号管理页面修改权限才可访问数据库,此账号和密码会作为服务内连接OceanBase数据库的数据库账号密码: ![file]()
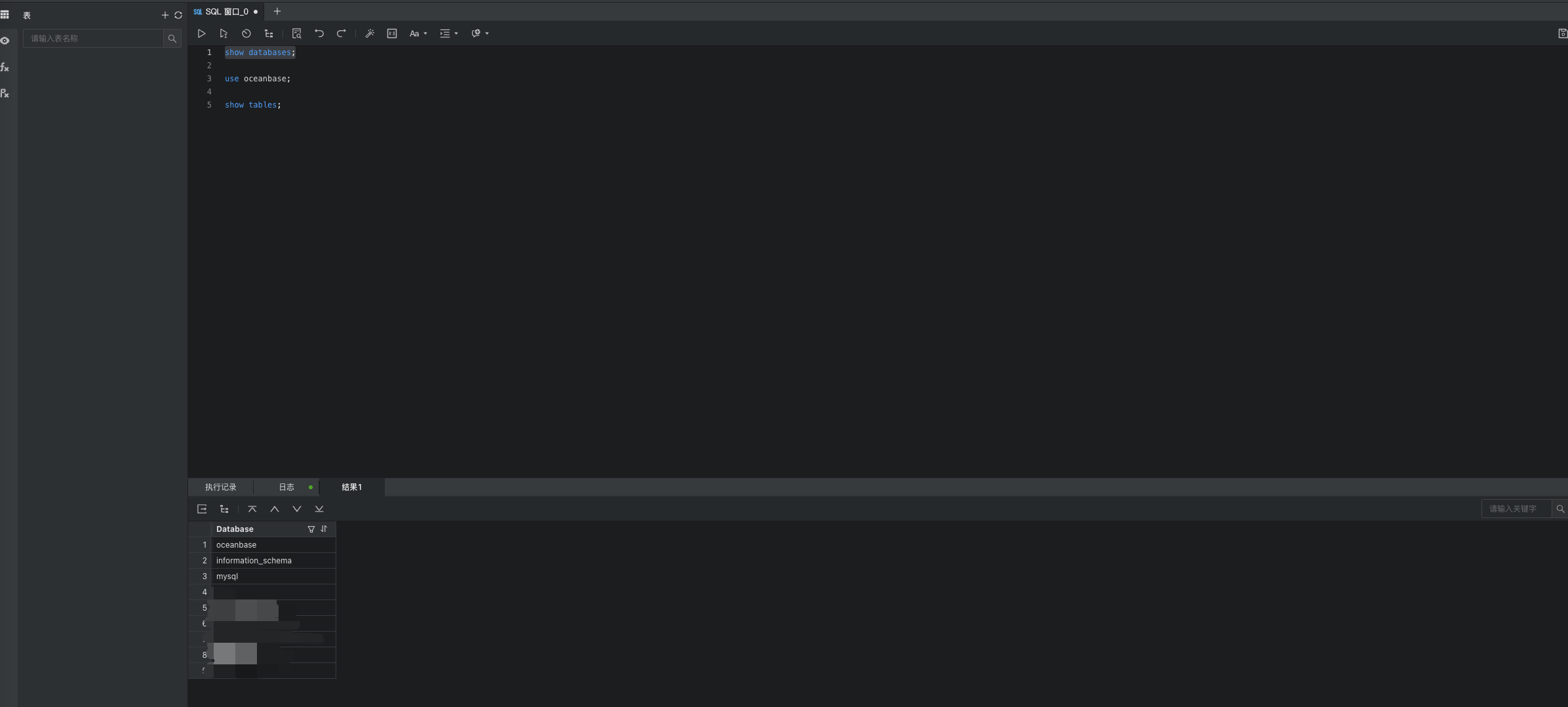
创建成功后在面板登陆数据库或使用其他数据源连接工具或使用命令行登陆数据库并执行SQL验证是否可用: ![file]()
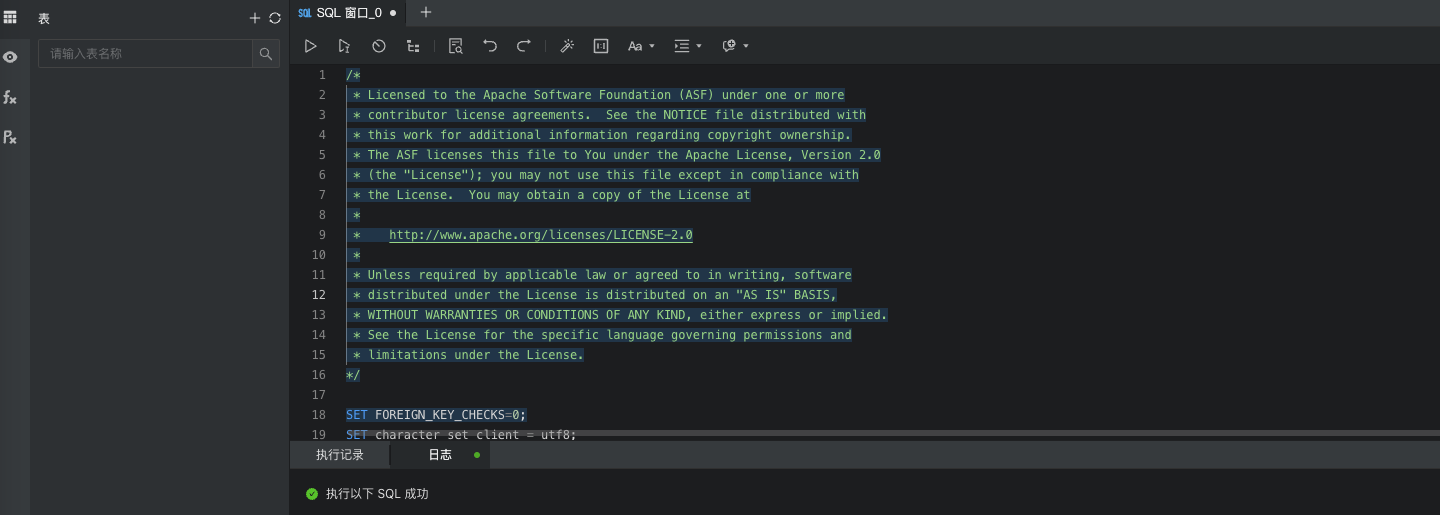
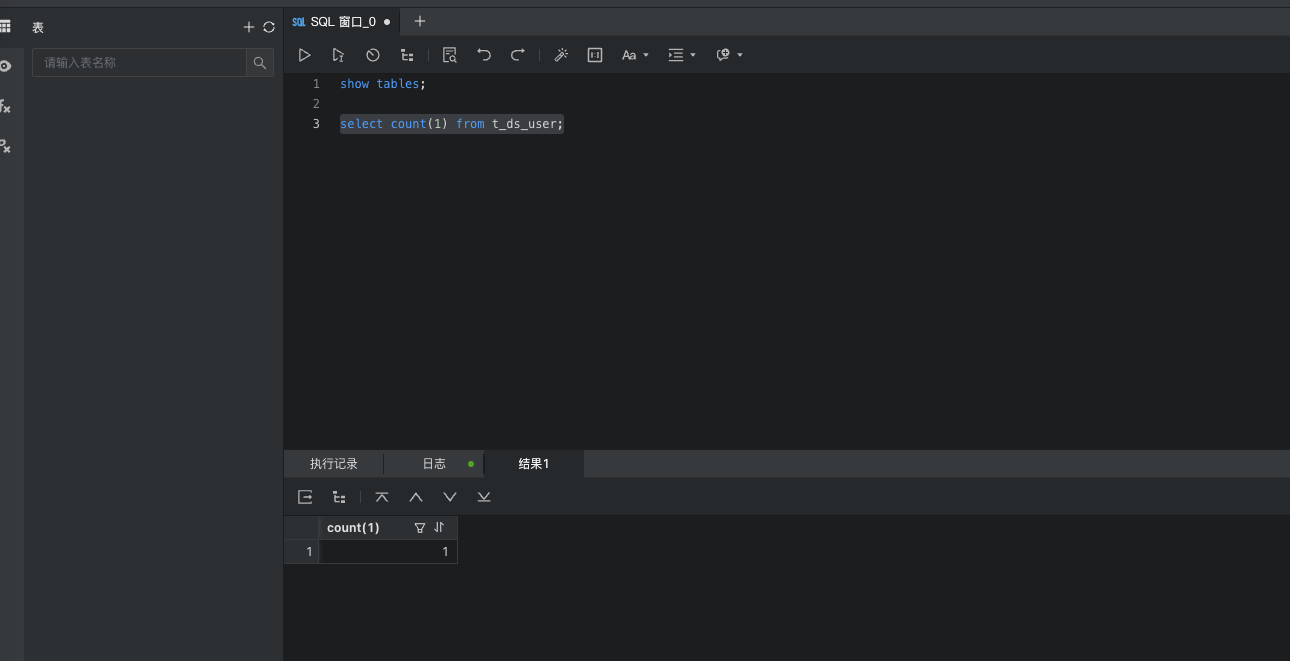
- 进入OceanBase后创建DolphinScheduler数据库,执行表初始化SQL文件:
dolphinscheduler/dolphinscheduler-dao/src/main/resources/sql/dolphinscheduler_mysql.sql;
![file]()
![file]()
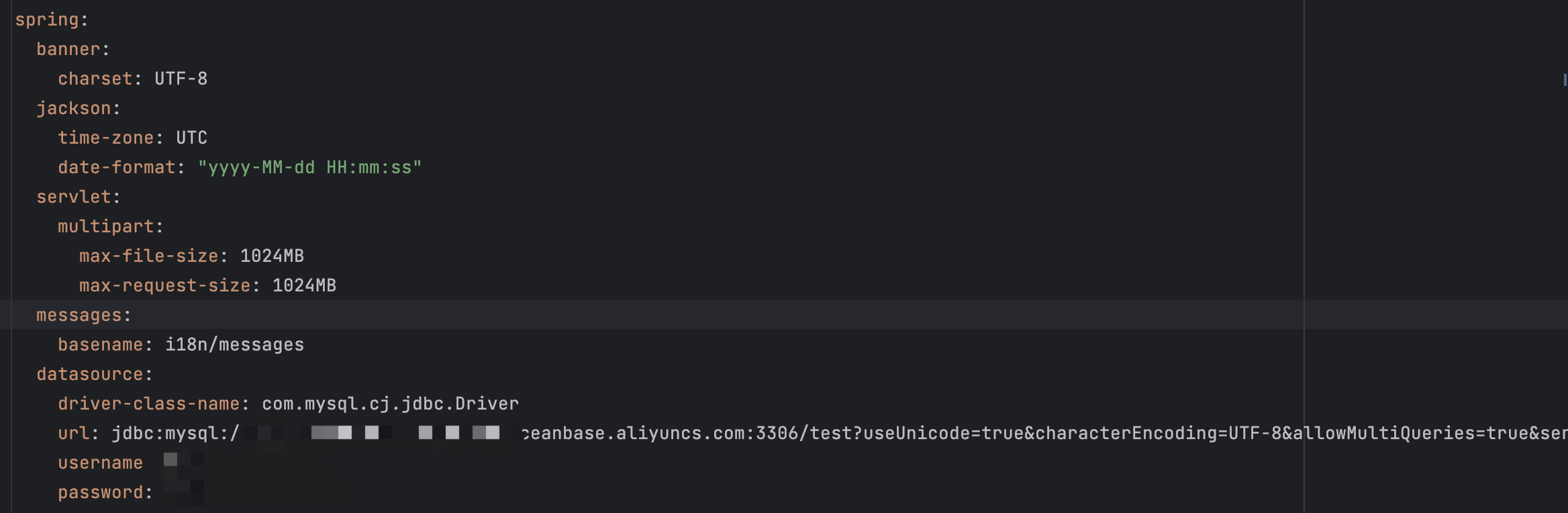
- 修改DolphinScheduler的配置文件,将原有的MySQL数据源替换成新的OceanBase数据源;
本地启动Api服务:修改dolphinscheduler-api模块配置文件中的数据库地址
![file]()
本地启动Standalone服务:修改dolphinscheduler-standalone-server模块配置文件中的数据库地址
同上
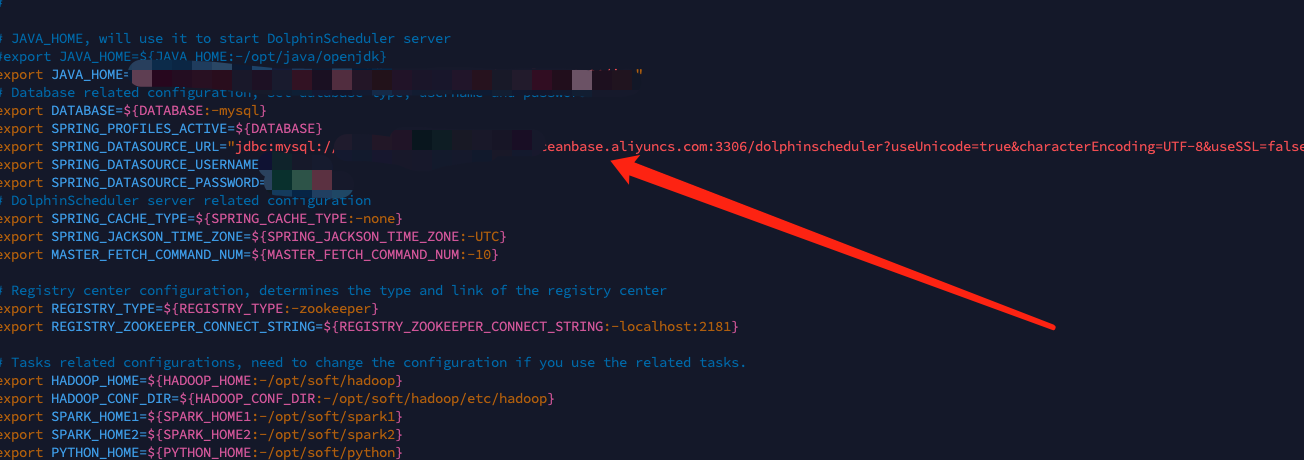
服务器部署:修改 /apache-dolphinscheduler-3.1.2-bin/bin/env/dolphinscheduler_env.sh中的数据库地址
![file]()
- 启动DolphinScheduler,正常访问登陆并其他模块都可正常操作即可验证OceanBase元数据库连接成功且正常使用:
![file]()
五. 切换过程中需要注意哪些事项
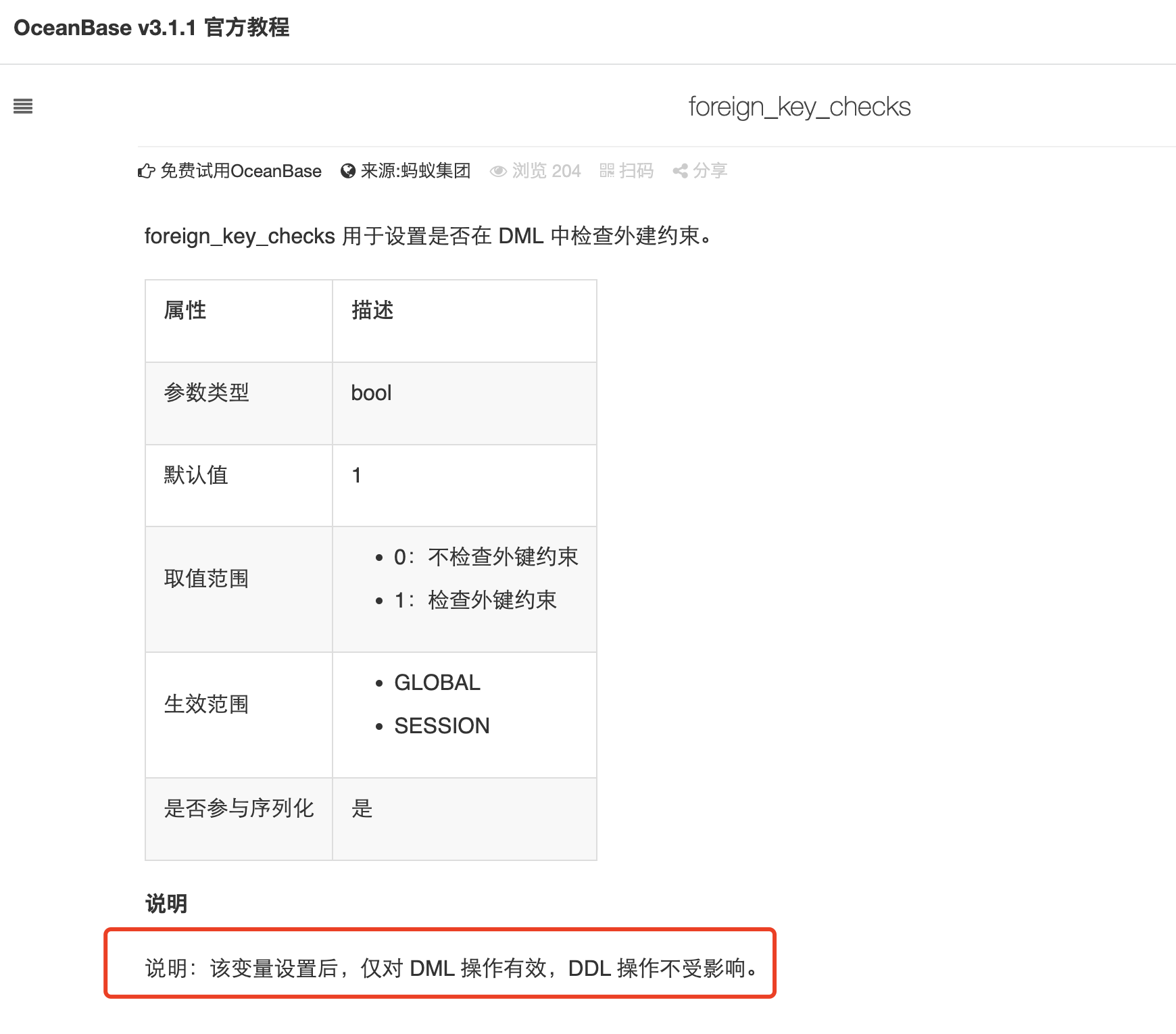
1.外键约束
在使用DolphinSchedulerSQL文件dolphinscheduler_mysql.sql初始化数据库时,SQL的开始会设置 SET FOREIGN_KEY_CHECKS=0 不检查外键约束,需要注意的是OceanBase社区版4.0之前是不支持DDL语句的外键约束的。例官方版本V3.1.1,
所以在这里我们要注意下OceanBase的版本兼容性。
![file]()
2. 数据迁移后插入报错
报错信息如下:
报错信息
Caused by: java.lang.ArrayIndexOutOfBoundsException: 0
at com.mysql.cj.protocol.a.NativePacketPayload.readInteger(NativePacketPayload.java:398)
at com.mysql.cj.protocol.a.NativePacketPayload.readString(NativePacketPayload.java:605)
at com.mysql.cj.protocol.a.NativeServerSessionStateController$NativeServerSessionStateChanges.init(NativeServerSessionStateController.java:112)
at com.mysql.cj.protocol.a.result.OkPacket.parse(OkPacket.java:66)
at com.mysql.cj.protocol.a.NativeProtocol.readServerStatusForResultSets(NativeProtocol.java:1691)
at com.mysql.cj.protocol.a.TextResultsetReader.read(TextResultsetReader.java:116)
at com.mysql.cj.protocol.a.TextResultsetReader.read(TextResultsetReader.java:48)
at com.mysql.cj.protocol.a.NativeProtocol.read(NativeProtocol.java:1600)
at com.mysql.cj.protocol.a.NativeProtocol.readAllResults(NativeProtocol.java:1654)
at com.mysql.cj.protocol.a.NativeProtocol.sendQueryPacket(NativeProtocol.java:1000)
at com.mysql.cj.NativeSession.execSQL(NativeSession.java:666)
at com.mysql.cj.jdbc.ClientPreparedStatement.executeInternal(ClientPreparedStatement.java:930)
... 157 common frames omitted
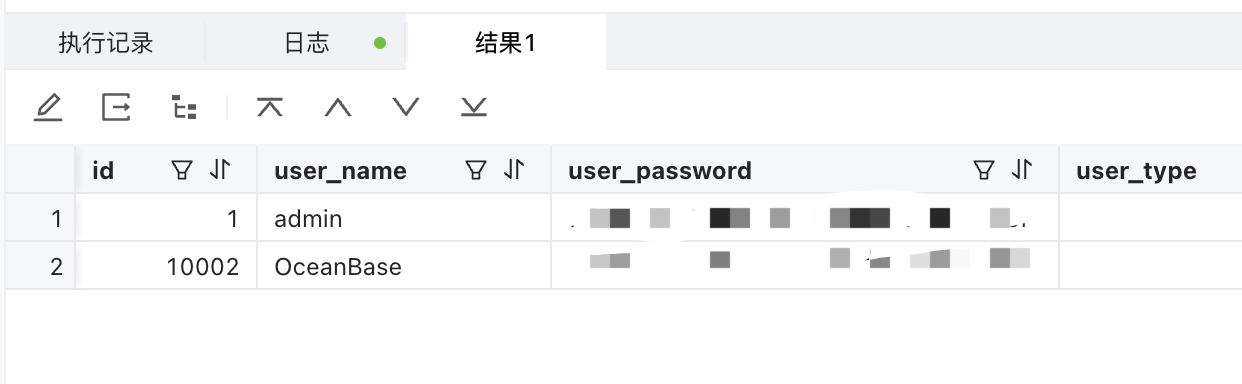
这种情况在切换为OceanBase数据库之后在数据插入时可能会发生。初始化数据时部分数据会带着ID将数据插入表中,之后再次插入数据此时默认主键自增从0开始,这时会出现默认自增步长从10001开始的情况如下:
![file]()
六. 总结
DolphinScheduler本身是一个非常强大的分布式调度系统,它可以帮助您轻松管理和调度大规模的数据任务。而当它与OceanBase结合使用时,它可以为您提供更具弹性、更安全、更可靠的数据存储方式。这种组合可以帮助您更好地解决大规模数据任务管理和调度的问题,同时提高您的工作效率和任务应用的可靠性。因此,如果您正在使用DolphinScheduler来管理和调度数据任务,强烈建议您尝试使用OceanBase作为其元数据库,让您的任务应用变得更加高效和可靠。
本文由 白鲸开源科技 提供发布支持!