前言
说到MySQL的MTS,相信很多同学都不陌生,从5.6开始基于schema的并行回放,到5.7的LOGICAL_CLOCK支持基于事务的并行回放,这些内容都有文章讲解,在本篇文章不再赘述。今天要讲的是,你知道如何查看并行回放是否存在性能瓶颈吗,是由于主库事务行为导致无法并行回放,还是由于worker线程不足,限制了并行回放的天花板?这都得从一个Note信息说起。
MY-010559
在开启了多线程回放的从库error log,我们经常能看到Note级别的日志信息MY-010559
![file]() 让我们来看看这些日志的含义
让我们来看看这些日志的含义
Seconds elapsed:当前时间与上次输出日志时间的间隔秒数
Events assigned:自slave协调线程启动后,累计处理分发给worker线程的event数量。简单理解为slave启动后处理的event数量。
Worker queues filled over overrun level:worker线程处理的event队列长度超过最大队列数(目前代码硬编码16384)的90%的次数,如果0则说明未发生该情况。
Waited due to worker queue full:worker线程处理的event队列长度达到最大(目前代码硬编码16384)的次数,如果为0则说明未发生该情况,是前面Worker queues filled over overrun level的情况升级。
Waited due to the total size:协调线程分发event大小达到replica_pending_jobs_size_max或者slave_pending_jobs_size_max限制而产生等待的次数。前面两个参数是限制worker线程处理event队列能够申请的最大内存(即大事务)。如果遇到此种大事务,在回放该大事务之前,会等待其他worker线程处理完已分配event,然后再进行该大事务的回放,回放过程中,后续的event回放,也会进入等待状态。总之,大事务回放特别影响并行回放的性能,只能串行回放。
Waited at clock conflicts:由于不能并行回放的累计等待时间,单位纳秒。如果并行回放策略设置的是DATABASE而不是LOGICAL_CLOCK,该值一直为0。
Waited (count) when workers occupied:协调线程休眠次数。有两种情况会累加此状态值:1、worker线程达到最大队列数(目前代码硬编码16384)的90%,此种情况协调线程最多休眠1毫秒;2、并行回放策略设置为LOGICAL_CLOCK时,由于没有空闲的worker线程导致无法分配事务的第一个event而产生的等待,此种情况协调线程会一直处于等待状态直到有空闲的worker线程能够处理回放。
Waited when workers occupied:等待空闲的worker线程累计时间,单位纳秒,对应Waited (count) when workers occupied的第二种等待情况。
代码分析
在8.0.26版本的代码中,我们通过错误信息关键字waited at clock conflicts查找,发现信息记录在变量ER_RPL_MTS_STATISTICS中,
![file]() 继续按变量查找,发现其使用在rpl_replica.cc文件的apply_event_and_update_pos函数中,主要逻辑代码如下
继续按变量查找,发现其使用在rpl_replica.cc文件的apply_event_and_update_pos函数中,主要逻辑代码如下
![file]() 可以看到,满足如下几个条件,日志信息就会输出
可以看到,满足如下几个条件,日志信息就会输出
- 并行回放为开启状态
- 并行回放的累计event数量对1024取模余1
- 当前时间减去上次日志时间间隔大于mts_online_stat_period(硬编码120)秒
- error log日志级别为info(log_error_verbosity=3)
上述几个条件,和并行回放的事务繁忙程度并没有太大的关系,满足条件即会记录日志。假如一个事务有4个event,参数设置正常,每两分钟执行256个事务,就会输出一条日志信息,一秒钟3个事务不到。
日志解析观察
在我的日志文件中,取了如下两条连续的信息
2023-07-09T08:58:01.001019+08:00 909 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'group_replication_applier': seconds elapsed = 180; events assigned = 11515905; worker queues filled over overrun level = 8314; waited due a Worker queue full = 0; waited due the total size = 0; waited at clock conflicts = 136628031500 waited (count) when Workers occupied = 242457 waited when Workers occupied = 2223254351900
2023-07-09T09:00:01.648124+08:00 909 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'group_replication_applier': seconds elapsed = 120; events assigned = 11518977; worker queues filled over overrun level = 8314; waited due a Worker queue full = 0; waited due the total size = 0; waited at clock conflicts = 136644607700 waited (count) when Workers occupied = 242491 waited when Workers occupied = 2223755727800
第一条解析信息如下:
. 本次日志输出时间点为2023-07-09T08:58:01.001019
. 与上次日志输出间隔时间为180秒
. 累计处理event数量为11515905
. worker线程处理的event队列长度超过最大队列数(目前代码硬编码16384)的90%的累计次数8314次
. worker线程处理的event队列长度达到最大队列数(目前代码硬编码16384)的累计次数为0次
. 回放event大小达到replica_pending_jobs_size_max或者slave_pending_jobs_size_max的次数为0
. 由于不能并行回放而产生的累计等待时间为136628031500纳秒(约136.62秒)
. 协调线程累计休眠242457次
. 累计等待空闲worker线程的时间为2223254351900纳秒(约2223.33秒)
第二条解析信息如下:
. 本次日志输出时间点为2023-07-09T09:00:01.648124
. 与上次日志输出间隔时间为120秒
. 累计处理event数量为11518977,新增处理event数量3072(为1024的3倍)
. worker线程处理的event队列长度超过最大队列数(目前代码硬编码16384)的90%的累计次数8314次,新增0次
. worker线程处理的event队列长度达到最大队列数(目前代码硬编码16384)的累计次数为0次
. 回放event大小达到replica_pending_jobs_size_max或者slave_pending_jobs_size_max的次数为0
. 由于不能并行回放而产生的累计等待时间为136644607700纳秒(约136.64秒,新增等待约0.02秒)
. 协调线程累计休眠242457次,新增34次
. 累计等待空闲worker线程的时间为2223755727800纳秒(约2223.38,新增等待约0.05秒)
通过上述信息,可以看出,在日志阶段,系统处于空闲状态,处理事务数不多。 对比各个参数,在系统繁忙时,因为不能并行回放产生的等待时间为136.64秒,等待空闲的worker线程累计时间为2223.38,因此增大slave_parallel_workers的参数值,可以提升并行回放性能。
总结
[Note] [MY-010559]在我刚开始接触时,以为是系统出现了异常产生的日志,待真正了解其内容后,才发现通过该日志可以帮助我们了解MTS运行情况,针对性的做优化调整。
Enjoy GreatSQL :)
关于 GreatSQL
GreatSQL是适用于金融级应用的国内自主开源数据库,具备高性能、高可靠、高易用性、高安全等多个核心特性,可以作为MySQL或Percona Server的可选替换,用于线上生产环境,且完全免费并兼容MySQL或Percona Server。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
GreatSQL社区:
![image]()
社区有奖建议反馈: https://greatsql.cn/thread-54-1-1.html
社区博客有奖征稿详情: https://greatsql.cn/thread-100-1-1.html
(对文章有疑问或者有独到见解都可以去社区官网提出或分享哦~)
技术交流群:
微信&QQ群:
QQ群:533341697
微信群:添加GreatSQL社区助手(微信号:wanlidbc )好友,待社区助手拉您进群。
 让我们来看看这些日志的含义
让我们来看看这些日志的含义 继续按变量查找,发现其使用在rpl_replica.cc文件的apply_event_and_update_pos函数中,主要逻辑代码如下
继续按变量查找,发现其使用在rpl_replica.cc文件的apply_event_and_update_pos函数中,主要逻辑代码如下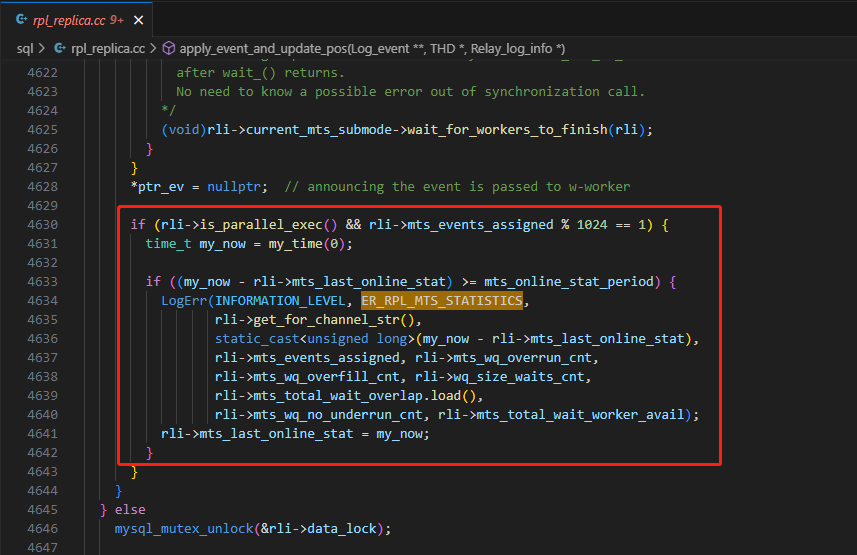 可以看到,满足如下几个条件,日志信息就会输出
可以看到,满足如下几个条件,日志信息就会输出
