摘要:本文将聚焦于用户监控的原理及应用进行介绍。
本文分享自华为云社区《GaussDB(DWS)监控工具指南(二)用户级监控》,作者:幕后小黑爪 。
前言
资源监控是整个运维乃至整个产品生命周期重要的一环,事前及时语句发现故障,事后提供详实的数据用于追查定位问题。GaussDB(DWS)整个资源监控体系分为作业级监控、用户监控和资源池监控。本文将聚焦于用户监控的原理及应用进行介绍。
1、GuassDB(DWS)用户体系
对于一个产品来说,最简单的用户分类是普通用户、系统管理员、超级管理员三层体系。超级管理员拥有最高级的权限,普通用户作为最基本的用户,用户操作系统的部分权限,系统管理员也拥有部分权限,同时他也可改变普通用户的权限。超级管理员拥有所有权限,但是不轻易使用。
1.1 两层用户机制介绍
对于一个企业来说,对数据库的操作也是分部门运作,每个部门单独有的表,同时每个部门也有单独的优先级,有鉴于此,GaussDB(DWS)设计的用户体系也分为两层:
第一层为组用户,该层用户关联组资源池,不作为执行作业的用户使用。
第二层为业务用户,该层用户关联业务资源池,可作为执行作业的用户使用。
组用户之间可使用的资源也可单独设置。每个业务用户之间亦可设置单独的资源。相较于以往单层的用户机制而言,两层的用户机制可实现对用户资源进行粒度更小的管控。
示例:
# 创建cgroup控制组
gs_ssh -c "gs_cgroup -c -S ClassG1 -G wn1"
# 创建组资源池resource_pool_a绑定ClassG1控制组。
CREATE RESOURCE POOL resource_pool_a WITH (control_group = 'ClassG1');
# 创建业务资源池resource_pool_a1绑定wn1控制组。
CREATE RESOURCE POOL resource_pool_a1 WITH (control_group = 'ClassG1:wn1');
# 创建组用户关联到组资源池。例如,名称为“tenant_a”的组用户关联到“resource_pool_a”组资源池
CREATE USER tenant_a RESOURCE POOL 'resource_pool_a' PASSWORD '********';
# 创建业务用户关联到业务资源池和组用户。例如,名称为“tenant_a1”的业务用户关联到“resource_pool_a1”组资源池和“tenant_a”组用户。
CREATE USER tenant_a1 RESOURCE POOL 'resource_pool_a1' USER GROUP 'tenant_a' PASSWORD '********';
1.2 赋权
当我们需要普通用户访问某个表时,可使用grant语法对用户赋权限或者收回权限,该操作需要拥有sysadmin权限的用户进行,举个例子
# 将public表空间下的lineitem表的查询权限赋给user_1:
grant select on public.lineitem to user_1;
# 回收user_1的public表空间下的lineitem表的查询权限:
Revoke select on public.lineitem from user_1;
2、用户资源监控
2.1 目标
一般情况下,数仓产品会同时有多个用户对数据库进行操作,每个用户使用的资源量有差异,举个极端的例子,当某个用户下发了慢SQL,导致集群整体性能劣化,此时我们就需要确定这个作业是哪个用户下发的,然后找到对应的慢SQL,对其进行管理。
对于管理员用户而言,用户监控可以帮助管理员以用户的维度了解系统的性能状况,及时发现并解决资源瓶颈和故障,提高系统的可靠性和稳定性。还可区分每个用户在整个集群中使用的资源量,确定哪些用户使用的资源量超标,然后对超标的用户进行限制。
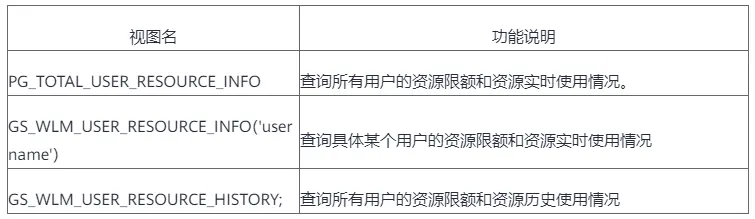
2.2 监控维度
用户监控支持对CPU、内存、存储空间、临时空间、算子落盘空间、磁盘IO、网络等方面的监控,通过对这些资源的监控,管理员可以了解系统的负载情况、进程的运行状态、磁盘空间的使用情况、网络带宽的利用率等信息。这些信息可以帮助管理员及时发现系统的异常情况,及时采取措施,避免系统崩溃或者服务中断。
使用示例:
postgres=# SELECT * FROM PG_TOTAL_USER_RESOURCE_INFO;
username | used_memory | total_memory | used_cpu | total_cpu | used_space | total_space | used_temp_space | total_temp_space | used_spill_space | total_spill_space | read_kbytes | write_kbytes | read_cou
nts | write_counts | read_speed | write_speed | send_speed | recv_speed
------------------+-------------+--------------+----------+-----------+------------+-------------+-----------------+------------------+------------------+-------------------+-------------+--------------+---------
----+--------------+------------+-------------+------------+------------
user_grp_1 | 0 | 4928 | 0 | 16 | 1573880 | -1 | 0 | -1 | 0 | -1 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0
perfadm | 0 | 0 | 0 | 0 | 0 | -1 | 0 | -1 | 0 | -1 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0
user_normal | 0 | 24643 | 0 | 16 | 0 | -1 | 0 | -1 | 0 | -1 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0
usr1 | 0 | 69763 | 0 | 40 | 0 | -1 | 0 | -1 | 0 | -1 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0
logical_cluster1 | 0 | 24643 | 0 | 16 | 1834424 | -1 | 0 | -1 | 0 | -1 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0
user_2 | 0 | 985 | 0 | 16 | 0 | -1 | 0 | -1 | 0 | -1 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0
user_1 | 0 | 3942 | 0 | 16 | 1573880 | -1 | 0 | -1 | 0 | -1 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0
logical_cluster2 | 0 | 45120 | 0 | 24 | 0 | -1 | 0 | -1 | 0 | -1 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0
user_default | 0 | 24643 | 0 | 16 | 0 | -1 | 0 | -1 | 0 | -1 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0
wjx | 0 | 24643 | 0 | 16 | 0 | -1 | 0 | -1 | 0 | -1 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | 0
(10 rows)
postgres=# select * from GS_WLM_USER_RESOURCE_HISTORY;
username | timestamp | used_memory | total_memory | used_cpu | total_cpu | used_space | total_space | used_temp_space | total_temp_space | used_spill_space | total_spill_space | read_
kbytes | write_kbytes | read_counts | write_counts | read_speed | write_speed | send_speed | recv_speed
------------------+-------------------------------+-------------+--------------+----------+-----------+------------+-------------+-----------------+------------------+------------------+-------------------+------
-------+--------------+-------------+--------------+------------+-------------+------------+------------
user_grp_1 | 2023-05-22 16:51:03.380482+08 | 0 | 4928 | 0 | 16 | 1573880 | -1 | 0 | -1 | 0 | -1 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
wjx | 2023-05-22 16:51:03.380482+08 | 0 | 24643 | 0 | 16 | 0 | -1 | 0 | -1 | 0 | -1 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
user_default | 2023-05-22 16:51:03.380482+08 | 0 | 24643 | 0 | 16 | 0 | -1 | 0 | -1 | 0 | -1 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
logical_cluster2 | 2023-05-22 16:51:03.380482+08 | 0 | 45120 | 0 | 24 | 0 | -1 | 0 | -1 | 0 | -1 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
user_1 | 2023-05-22 16:51:03.380482+08 | 0 | 3942 | 0 | 16 | 1573880 | -1 | 0 | -1 | 0 | -1 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
user_2 | 2023-05-22 16:51:03.380482+08 | 0 | 985 | 0 | 16 | 0 | -1 | 0 | -1 | 0 | -1 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
logical_cluster1 | 2023-05-22 16:51:03.380482+08 | 0 | 24643 | 0 | 16 | 1834424 | -1 | 0 | -1 | 0 | -1 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
usr1 | 2023-05-22 16:51:03.380482+08 | 0 | 69763 | 0 | 40 | 0 | -1 | 0 | -1 | 0 | -1 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
user_normal | 2023-05-22 16:51:03.380482+08 | 0 | 24643 | 0 | 16 | 0 | -1 | 0 | -1 | 0 | -1 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
2.3 监控原理
内核在作业运行时,依据作业携带的用户信息,进行相关资源字段的累计,每隔一段时间将信息汇总至用户监控历史表中。此外,该功能的使用有些规格:
2.3.1 相关GUC参数
enable_logical_io_statistics:用户资源监控和资源池资源监控IO相关数值的开关,默认为on,开启后用户监控中io相关记录(read_kbytes、write_kbytes、read_counts、write_counts、read_speed和write_speed)会进行统计。
enable_user_metric_persistent:否开启用户/资源池历史资源监控转存功能,开启后会将监控记录转存到历史表中。
user_metric_retention_time:设置用户历史资源监控数据的保存天数,默认为7天
2.3.2 相关说明
当前用户监控可同时监控快慢车道的所有作业的CPU、IO和内存使用情况。
当用户在CN上进行查询时,显示的为所有DN资源池使用和资源限制的累积和。在DN查询时仅统计本DN上资源池使用和资源限制信息。
DN上数据收集周期为5s,CN每隔5s从DN上收集一次信息。辅助线程每30s自动进行持久化操作,持久化用户监控数据。
对于初始管理用户暂不进行资源监控,因为该用户是超级管理员用户,没必要监控。
2.4 案例分析
2.4.1 当出现内存不可用时,可通过该视图查看是哪个用户使用的内存过高
2.4.2 可以监控用户网络使用情况,比如网络的收发速率等。
点击关注,第一时间了解华为云新鲜技术~