1.背景
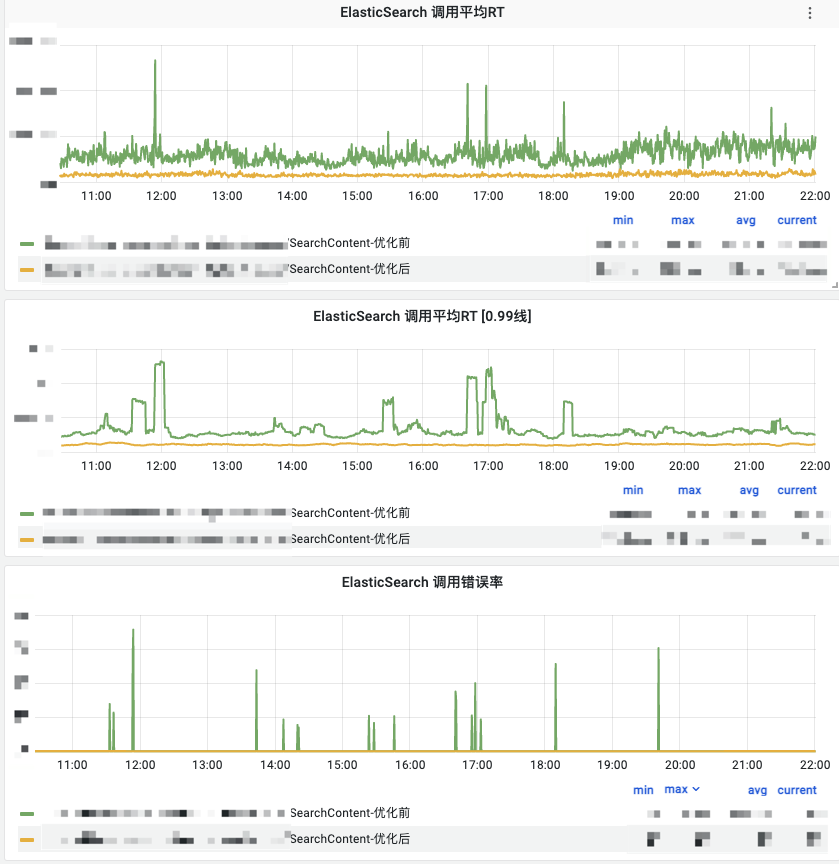
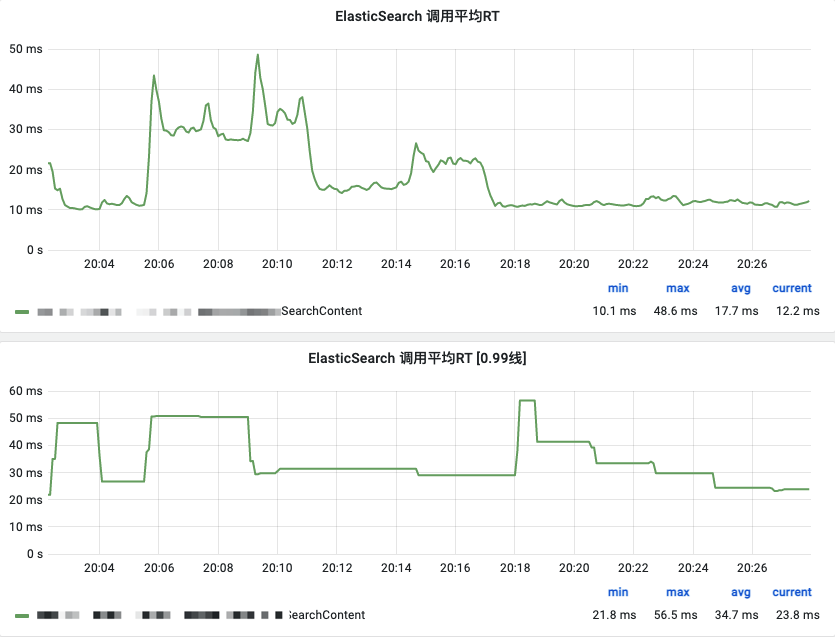
2020年以来内容标注结果搜索就是社区中后台业务的核心高频使用场景之一,为了支撑复杂的后台搜索,我们将社区内容的关键信息额外存了一份到Elasticsearch中作为二级索引使用。随着标注业务的细分、迭代和时间的推移,这个索引的文档数和搜索的RT开始逐步上升。下面是这个索引当前的监控情况。 ![1.png]()
本文介绍社区利用IndexSorting,将亿级文档搜索性能由最开始2000ms优化到50ms的过程。如果大家遇到相似的问题和场景,相信看完之后一定能够一行代码成吨收益。
2.探索过程
2.1 初步优化
最开始需求很简单,只需要取最新发布的动态分页展示。这时候实现也是简单粗暴,满足功能即可。查询语句如下:
{
"track_total_hits": true,
"sort": [
{
"publish_time": {
"order": "desc"
}
}
],
"size": 10
}
由于首页加载时没加任何筛选条件,于是变成了从亿级内容库中找出最新发布的10条内容。
针对这个查询很容易发现问题出现在大结果集的排序,要解决问题,自然的想到了两条路径:
- 去掉sort
- 缩小结果集
经过用户诉求和开发成本的权衡后,当时决定“先扛住,再优化”:在用户打开首页的时候,默认增加“发布时间在最近一周内”的筛选条件,这时语句变成了:
{
"track_total_hits": true,
"query": {
"bool": {
"filter": [
{
"range": {
"publish_time": {
"gte": 1678550400,
"lt": 1679155200
}
}
}
]
}
},
"sort": [
{
"publish_time": {
"order": "desc"
}
}
],
"size": 10
}
这个改动上线后,效果可以说是立竿见影,首页加载速度立马降到了200ms以内,平均RT60ms。这次改动也为我们减小了来自业务的压力,为后续的优化争取了不少调研的时间。
虽然搜索首页的加载速度明显快了,但是并没有实际解决根本问题——ES大结果集指定字段排序还是很慢。对业务来说,结果页上的一些边界功能的体验依旧不能尽如人意,比如导出、全量动态的搜索等等。这一点从监控上也能够较明显的看出:慢查询还是存在,并且还伴随着少量的接口超时。
![2.png]()
老实说这个时期我们对于ES的了解还比较基础,只能说会用、知道分片、倒排索引、相关性打分,然后就没有了。总之我们有了方向,开始奋起直追。
2.2 细致打磨
2.2.1 知识积累
带着之前遗留的问题,我们开始开始重新出发,从头学习ES。要优化搜索性能,首先我们要知道的是搜索是怎么做的。下面我们就以一个最简单的搜索为例,拆解一下整个搜索请求的过程。
(1)搜索请求
{
"track_total_hits":false,
"query": {
"bool": {
"filter": [
{
"term": {
"category_id.keyword": "xxxxxxxx"
}
}
]
}
},
"size": 10
}
精确查询category_id为"xxxxxxxx"的文档,取10条数据,不需要排序,不需要总数
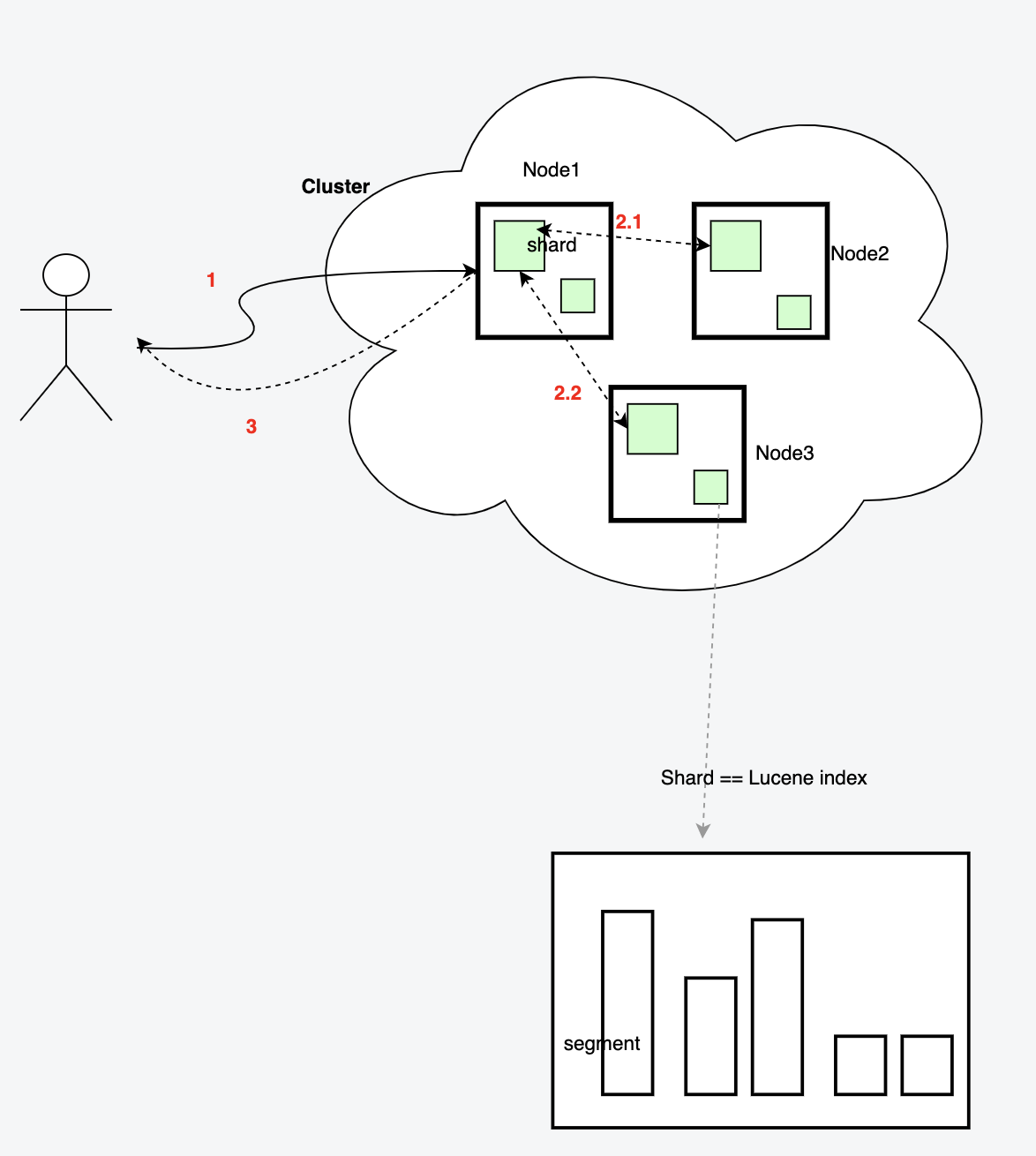
总流程分3步:
- 客户端发起请求到Node1
- Node1作为协调节点,将请求转发到索引的每个主分片或副分片中,每个分片在本地执行查询。
- 每个节点返回各自的数据,协调节点汇总后返回给客户端
如图可以大致描绘这个过程:
![3.png]()
我们知道ES是依赖Lucene提供的能力,真正的搜索发生在Lucene中,还需要继续了解Lucene中的搜索过程。
(2)Lucene
Lucene中包含了四种基本数据类型,分别是:
- Index:索引,由很多的Document组成。
- Document:由很多的Field组成,是Index和Search的最小单位。
- Field:由很多的Term组成,包括Field Name和Field Value。
- Term:由很多的字节组成。一般将Text类型的Field Value分词之后的每个最小单元叫做Term。
在介绍Lucene index的搜索过程之前,这里先说一下组成Lucene index的最小数据存储单元——Segment。
Lucene index由许许多多的Segment组成,每一个Segment里面包含着文档的Term字典、Term字典的倒排表、文档的列式存储DocValues以及正排索引。它能够独立的直接对外提供搜索功能,几乎是一个缩小版的Lucene index。
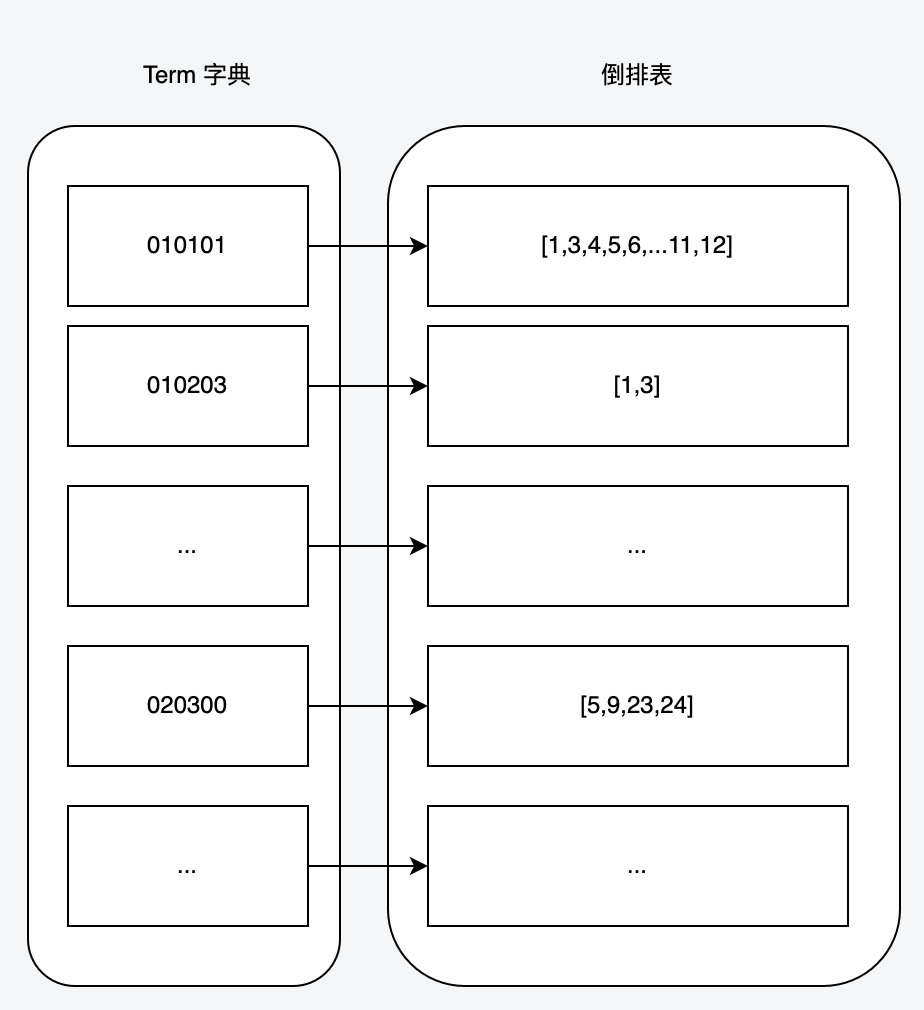
(3)Term字典和倒排表
![4.png]()
上图是Term字典和其倒排表的大致样子当然这里还有些重要数据结构,比如:
- FST:term索引,在内存中构建。可以快速实现单Term、Term范围、Term前缀和通配符查询。
- BKD-Tree:用于数值类型(包括空间点)的快速查找。
- SkipList:倒排表的数据结构
这里面的细节比较多,感兴趣的可以单独了解,这里不影响我们的整体搜索流程,不过多赘述。有了Term字典和倒排表我们就能直接拿到搜索条件匹配的结果集了,接下来只需要通过docID去正排索引中取回整个doc然后返回就完事儿了。这是ES的基本盘理论上不会慢,我们猜测慢查询发生在排序上。那给请求加一个排序会发生什么呢?比如:
{
"track_total_hits":false,
"query": {
"bool": {
"filter": [
{
"term": {
"category_id.keyword": "xxxxxxxx"
}
}
]
}
},
"sort": [
{
"publish_time": {
"order": "desc"
}
}
],
"size": 10
}
通过倒排表拿到的docId是无序的,现在指定了排序字段,最简单直接的办法是全部取出来,然后排序取前10条。这样固然能实现效果,但是效率却是可想而知。那么Lucene是怎么解决的呢?
(4)DocValues
倒排索引能够解决从词到文档的快速映射,但需要对检索结果进行分类、排序、数学计算等聚合操作时需要文档号到值的快速映射。而正排索引又过于臃肿庞大,怎么办呢?
这时候各位大佬可能就直接想到了列式存储,没有错,Lucene就引入了基于docId的列式存储结构——DocValues
| 文档号 |
列值 |
列值映射 |
| 0 |
2023-01-13 |
2 |
| 1 |
2023-01-12 |
1 |
| 2 |
2023-03-13 |
3 |
比如上表中的DocValues=[2023-01-13, 2023-01-12,2023-03-13]
如果列值是字符串,Lucene会把原来的字符串值按照字典排序生成数字ID,这样的预处理能进一步加快排序速度。于是我们得到了DocValues=[2, 1, 3]
Docvalues的列式存储形式可以加快我们的遍历的速度。到这里一个常规的搜索取前N条记录的请求算是真正的拆解完成。这里不讨论词频、相关性打分、聚合等功能的分析,所以本文对整个过程和数据结构做了大幅简化。如果对这部分感兴趣,欢迎一起讨论。
此时排序慢的问题也逐渐浮出了水面:尽管Docvalues又是列式存储,又是将复杂值预处理为简单值避免了查询时的复杂比较,但是依旧架不住我们需要排序的数据集过大。
看起来ES尽力了,它好像确实不擅长解决我们这个场景的慢查询问题。
不过有灵性的各位读者肯定想到了,如果能把倒排表按照我们预先指定的顺序存储好,就能省下整个排序的时间。
2.2.2 IndexSorting
很快ES官方文档《How to tune for search speed》中提到了一个搜索优化手段——索引排序(Index Sorting)出现在了我们的视野中。
从文档上的描述我们可以知道,索引排序对于搜索性能的提升主要在两个方面:
- 对于多条件并列查询(a and b and ...),索引排序可以帮助我们把不符合条件的文档存在一起,跳过大量的不匹配的文档。但是此技巧仅适用于经常用于筛选的低基数字段。
- 提前中断:当搜索排序和索引排序指定的顺序一样时,只需要比较每个段的前 N 个文档,其他的文档仅需要用于总数计算。比如:我们的文档中有一个时间戳,而我们经常需要按照时间戳来搜索和排序,这时候如果指定的索引排序和搜索排序一致,通常能够极大的提高搜索排序的效率。
提前中断!!!简直是缺什么来什么,于是我们开始围绕这一点展开调研。
(1)开启索引排序
{
"settings": {
"index": {
"sort.field": "publish_time", // 可指定多个字段
"sort.order": "desc"
}
},
"mappings": {
"properties": {
"content_id": {
"type": "long"
},
"publish_time": {
"type": "long"
},
...
}
}
}
如上面的例子,文档在写入磁盘时会按照 publish_time 字段的递减序进行排序。
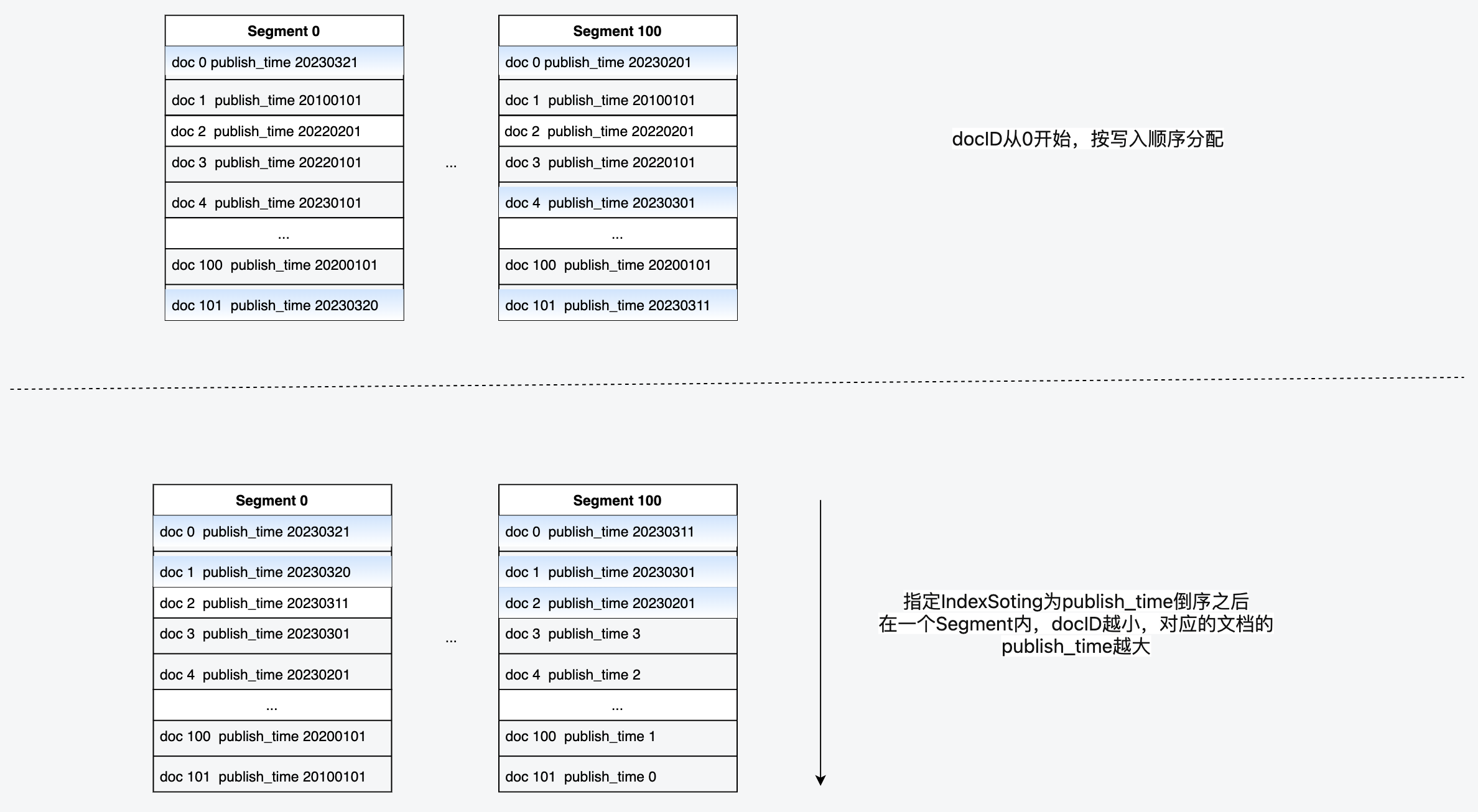
在前面的段落中我们反复提到了docID和正排索引。这里我们顺带简单介绍下他们的关系,首先Segment中的每个文档,都会被分配一个docID,docID从0开始,顺序分配。在没有IndexSorting时,docID是按照文档写入的顺序进行分配的,在设置了IndexSorting之后,docID的顺序就与IndexSorting的顺序一致。
下图描述了docID和正排索引的关系:
![5.png]()
那么再次回头来看看我们最开始的查询:
{
"track_total_hits":true,
"sort": [
{
"publish_time": {
"order": "desc"
}
}
],
"size": 10
}
在Lucene中进行查询时,发现结果集的倒排表顺序刚好是publish_time降序排序的,所以查询到前10条数据之后即可返回,这就做到了提前中断,省下了排序开销。那么代价是什么呢?
(2)代价
IndexSorting和查询时排序不一样,本质是在写入时对数据进行预处理。所以排序字段只能在创建时指定且不可更改。并且由于写入时要对数据进行排序,所以也会对写入性能也会有一定负面影响。
之前我们提到了Lucene本身对排序也有各种优化,所以如果搜索结果集本身没有那么多的数据,那么就算不开启这个功能,也能有不错的RT。
另外由于多数时候还是要计算总数,所以开启索引排序之后只能提前中断排序过程,还是要对结果集的总数进行count。如果能够不查总数,或者说通过另外的方式获取总数,那么能够更好的利用这个特性。
小结:
- 针对大结果集的排序取前N条的场景下,索引排序能显著提高搜索性能。
- 索引排序只能在创建索引时指定,不可更改。如果你有多个指定字段排序的场景,可能需要慎重选择排序字段。
- 不获取总数能更好的利用索引排序。
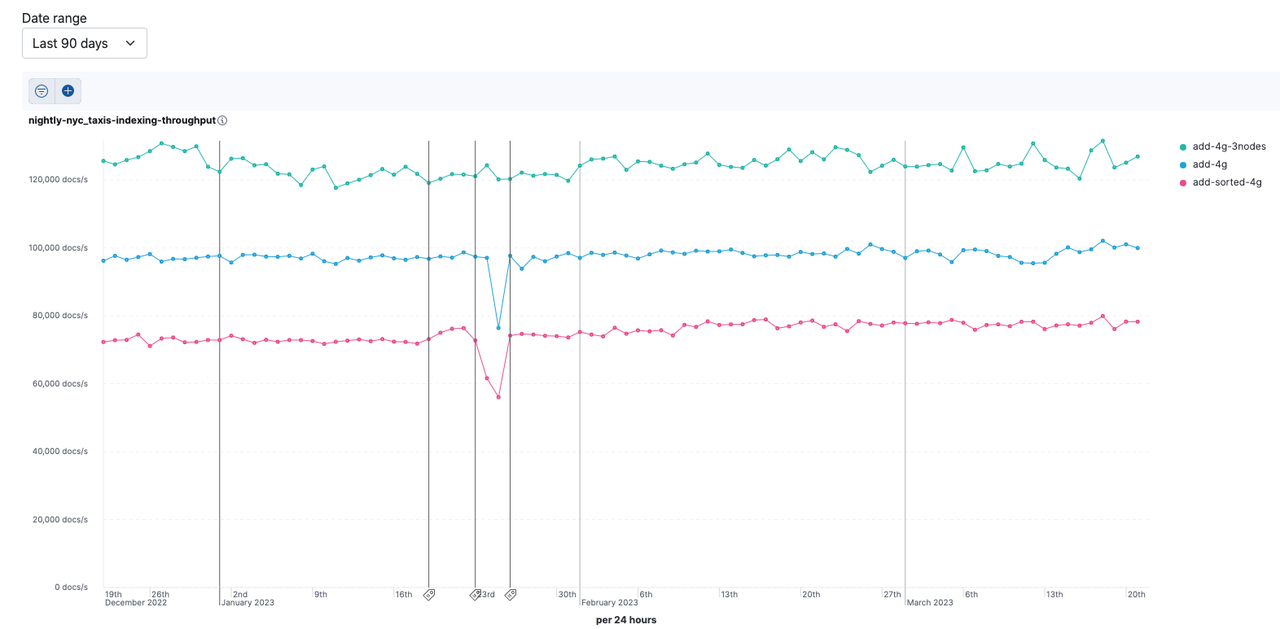
- 开启索引排序会一定程度降低写性能。 这里贴一条ElaticsearchBenchmarks的数据截图供大家参考。
![6.png]()
见:Elasticsearch Benchmarks
2.3 效果
由于我们的业务远远没有达到ES的写入瓶颈,而且也少有频繁变更排序字段的场景。在经过短暂的权衡之后,确定索引排序正是我们需要的,于是开始使用线上真实数据对索引排序的效果进行简单的性能测试。
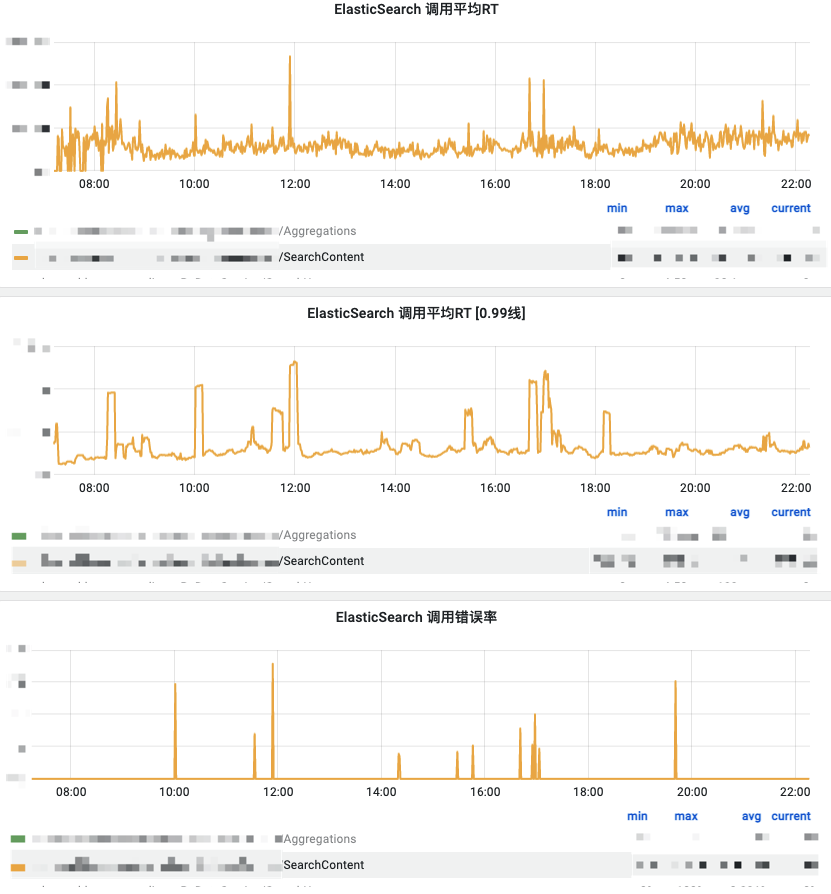
(1)性能测试:首页
![7.png]()
(2)性能测试:其他
这里开启索引排序后,随机几个常规条件和时间窗口的搜索组合测试
![8.png]()
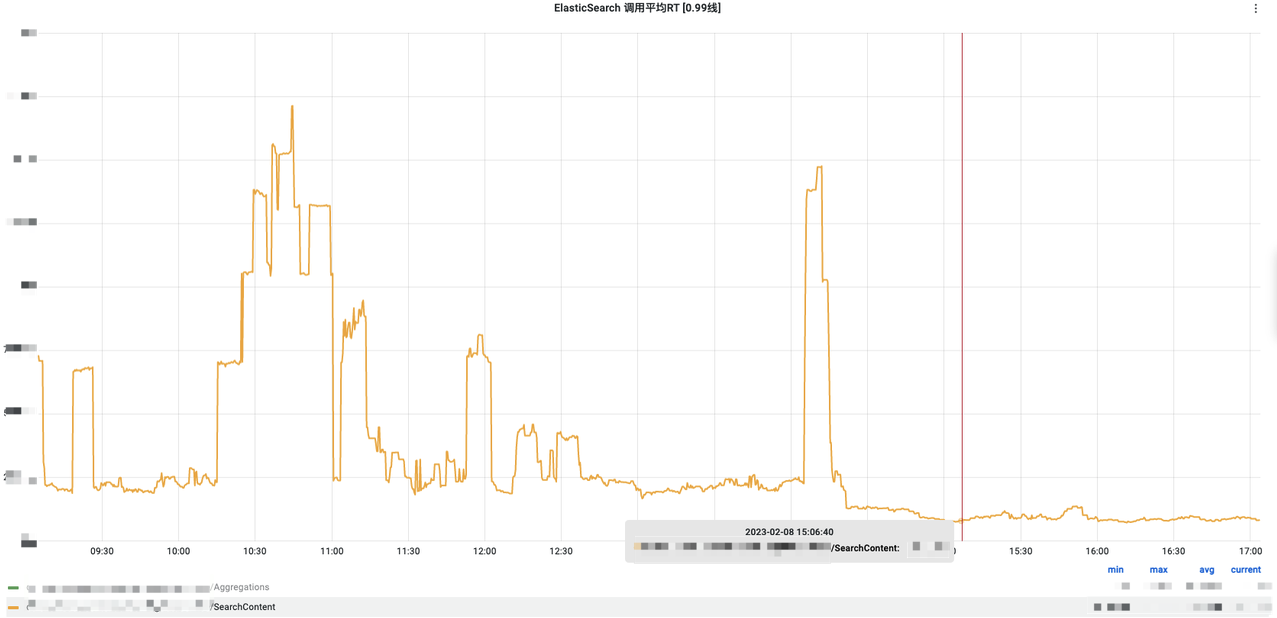
可以看到效果非常明显,没有以前的那种尖刺,RT也很稳定,于是我们决定正式上线这个功能。
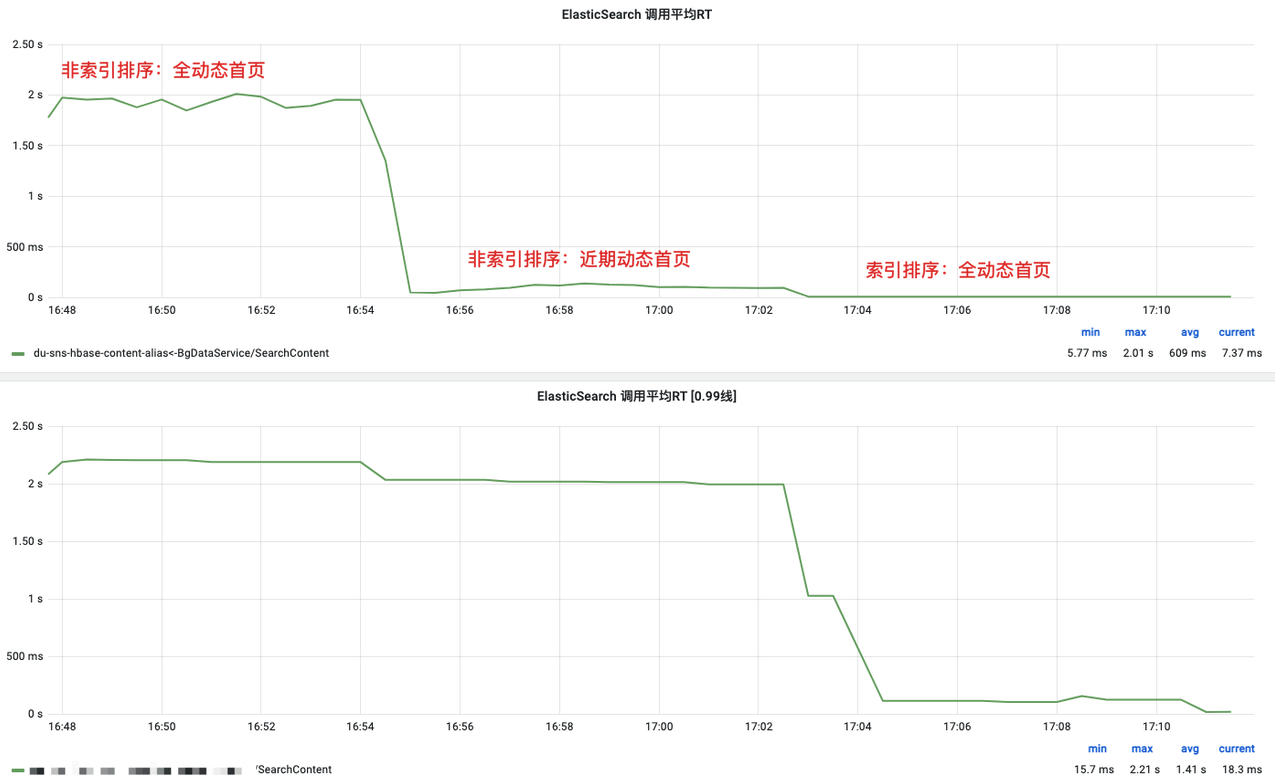
(3)线上效果
慢查询
![9.png]() !
!
整体前后对比
![10.png]()
和我们预期的基本一样,搜索RT大幅降低,慢查询完全消失。
2.4 后续优化
在探索过程中,其实还发现了一些其他的优化手段,鉴于开发成本和收益,有些我们并没有完全应用于生产环境。这里列出其中几点,希望能给大家一些启发。
- 不获取总数: 大部分场景下,不查询总数都能减少开销,提高性能。ES 7.x之后的搜索接口默认不返回总数了,由此可见一斑。
- 自定义routing规则: 从上文的查询过程我们可以看到,ES会轮询所有分片以获取想要的数据,如果我们能控制数据的分片落点,那么也能节省不少开销。比如说:如果我们将来如果有大量的场景都是查某个用户的动态,那么可以控制按照用户分片,这样就避免了分片轮询,也能提升搜索效率。
- keyword: 不是所有的数字都应该按照数值字段来存,如果你的数字值很少用于范围查询,但是经常被用作term查询,并且对搜索rt很敏感。那么keyword才是最适合的存储方式。
- 数据预处理:就像IndexSoting一样,如果我们能够在写入时预处理好数据,也能节省搜索时的开销。这一点配合
_ingest/pipeline 也许能发挥意想不到的效果。
3.写在最后
相信看到这里的大家都能看出,我们的优化中也没有涉及到十分高深的技术难点,我们只是在解决问题的过程中,逐步从小白转变成了一个初学者。来一个大牛也许从一开始就能直接绕过我们的弯路,不过万里之行始于足下,最后这里总结一点经验和感受分享给大家,希望能给与我们一样的初学者一些参考。
ES在大结果集指定字段排序的场景下性能不佳,我们使用时应该尽量避免出现这种场景。如果无法避免,合适的IndexSorting设置能大幅提升排序性能。
优化永无止境,权衡好成本和收益,集中资源解决最优先和重要的问题才是我们应该做的。
文:海带
本文属得物技术原创,来源于:得物技术官网
未经得物技术许可严禁转载,否则依法追究法律责任! 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
 !
!