
“伶荔”(Linly) 开源大规模中文语言模型
为了开发高性能中文基础模型,填补中文基础模型百亿到千亿级预训练参数的空白,大数据系统计算技术国家工程实验室团队在人工智能项目伶荔(Linly)框架下,推出了伶荔说系列中文语言大模型,目前包含中文基础模型和对话模型。
其中,中文基础模型以LLaMA为底座,利用中文和中英平行增量预训练,将它在英文上强大语言能力迁移到中文上。更进一步,汇总了目前公开的多语言指令数据,对中文模型进行了大规模指令跟随训练,实现了Linly-ChatFlow对话模型。

根据介绍,相比已有的中文开源模型,伶荔模型具有以下优势:
- 在32*A100 GPU上训练了不同量级和功能的中文模型,对模型充分训练并提供强大的baseline。据知,33B的Linly-Chinese-LLAMA是目前最大的中文LLaMA模型。
- 公开所有训练数据、代码、参数细节以及实验结果,确保项目的可复现性,用户可以选择合适的资源直接用于自己的流程中。
- 项目具有高兼容性和易用性,提供可用于CUDA和CPU的量化推理框架,并支持Huggingface格式。
目前公开可用的模型有:
- Linly-Chinese-LLaMA:中文基础模型,基于LLaMA在高质量中文语料上增量训练强化中文语言能力,现已开放 7B、13B 和 33B 量级,65B正在训练中。
- Linly-ChatFlow:中文对话模型,在400万指令数据集合上对中文基础模型指令精调,现已开放7B、13B对话模型。
- Linly-ChatFlow-int4 :ChatFlow 4-bit量化版本,用于在CPU上部署模型推理。
进行中的项目:
- Linly-Chinese-BLOOM:基于BLOOM中文增量训练的中文基础模型,包含7B和175B模型量级,可用于商业场景。
项目特点
Linly项目具有以下特点:
1. 大规模中文增量训练,利用翻译数据提速中文模型收敛
在训练数据方面,项目尽可能全面的收集了各类中文语料和指令数据。无监督训练使用了上亿条高质量的公开中文数据,包括新闻、百科、文学、科学文献等类型。和通常的无监督预训练不同,项目在训练初期加入了大量中英文平行语料,帮助模型将英文能力快速迁移到中文上。
在指令精调阶段,项目汇总了开源社区的指令数据资源,包括多轮对话、多语言指令、GPT4/ChatGPT问答、思维链数据等等,经过筛选后使用500万条数据进行指令精调得到Linly-ChatFlow模型。训练使用的数据集也在项目里提供。
训练流程如图所示:
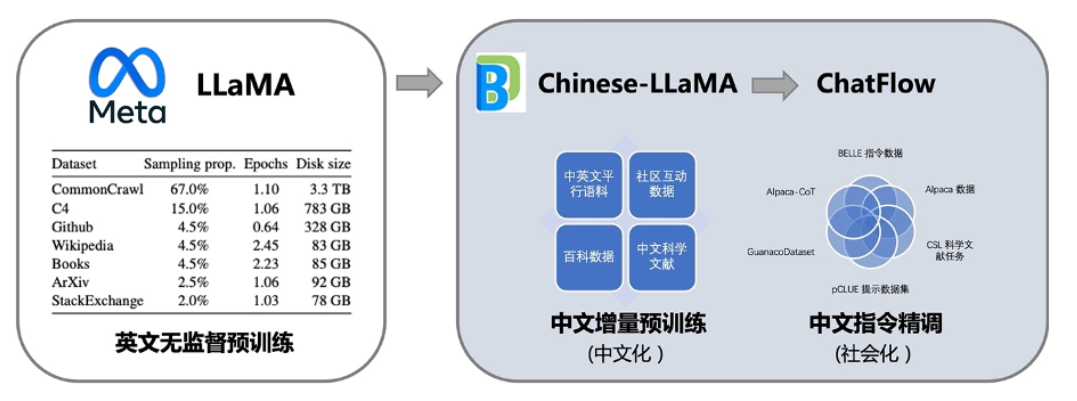
2. 全参数训练,覆盖多个模型量级
目前基于LLaMA的中文模型通常使用LoRA方法进行训练,LoRA冻结预训练的模型参数,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数,来实现快速适配。虽然LoRA能够提升训练速度且降低设备要求,但性能上限低于全参数训练。为了使模型获得尽可能强的中文语言能力,该项目对所有参数量级都采用全参数训练,开销大约是LoRA的3-5倍。
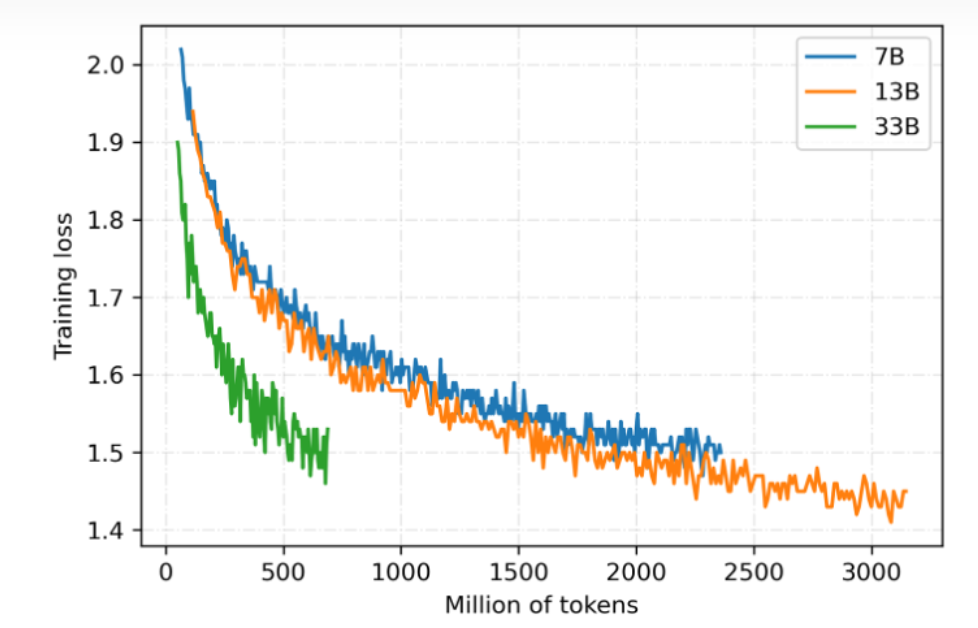
伶荔语言模型利用TencentPretrain多模态预训练框架,集成DeepSpeed ZeRO3以FP16流水线并行训练。目前已开放7B、13B、33B模型权重,65B模型正在训练中。模型仍在持续迭代,将定期更新,损失收敛情况如图所示:
3. 可支持本地CPU int4推理、消费级GPU推理
大模型通常具有数百亿参数量,提高了使用门槛。为了让更多用户使用Linly-ChatFlow模型,开发团队在项目中集成了高可用模型量化推理方案,支持int4量化CPU推理可以在手机或者笔记本电脑上使用,int8量化使用CUDA加速可以在消费级GPU推理13B模型。此外,项目中还集成了微服务部署,用户能够一键将模型部署成服务,方便二次开发。
未来工作
据透露,伶荔说系列模型目前仍处于欠拟合,正在持续训练中,未来33B和65B的版本或将带来更惊艳的性能。在另一方面,项目团队不仅公开了对话模型,还公开了中文基础模型和相应的训练代码与数据集,向社区提供了一套可复现的对话模型方案,目前也有团队基于其工作实现了金融、医学等领域的垂直领域对话模型。
在之后的工作,项目团队将继续对伶荔说系列模型进行改进,包括尝试人类反馈的强化学习(RLHF)、适用于中文的字词结合tokenizer、更高效的GPU int3/int4量化推理方法等等。伶荔项目还将针对虚拟人、医疗以及智能体场景陆续推出伶荔系列大模型。
 关注公众号
关注公众号 低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。
持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
转载内容版权归作者及来源网站所有,本站原创内容转载请注明来源。
- 上一篇

JetBrains 公布 WebStorm 2023.2 路线图
JetBrains 已公布了 WebStorm 2023.2 版本的路线图,以便用户可以率先了解到官方的规划以及能够预览一下未来能够用上的新功能。 主要聚焦于以下内容: 稳定的新UI。这是此版本中的优先事项之一。 CSS 嵌套支持。WebStorm 2023.2 计划将添加对CSS 嵌套功能的支持 (WEB-57875)。它提供了将一个样式规则嵌套在另一个样式规则中的能力,子规则的选择器与父规则的选择器相对应。这增加了 CSS 样式表的模块化和可维护性。 Vue.js 改进。在过去的一年里,开发团队致力于 Vue 支持并修复了许多问题,包括添加改进的New Component action(WEB-56464),预计将在WebStorm 2023.1.1 错误修复更新中可用。同时,其还计划继续改进 Vue.js 支持,特别是通过增加对依赖注入函数provide和inject所提供的属性的支持。 能够在 watch 模式下自动运行 Jest 测试。将为 Jest 测试添加一个 watch 模式,可以从工具窗口快速打开和关闭 (WEB-50559)。 Solid.js 和 Preact 支...
- 下一篇
wu-easy-excel-starter 版本:1.2.0-JDK1.8-SNAPSHOT
1.新增注解 EasyFile 注解支持字符串导出为文件 2.新增EasyExcel 注解支持对象导出文件 介绍 wu-easy-excel-starter是一款面向对象的excel、文件导出框架。 实现的功能: 1)针对Java中任何对象直接返回给web,在返回web过程自动将对象转换成想要的数据(Excel、File) 2)前端传一个Excel过来,后端接口接收到的其实已经是Bean了 快速导出excel模块 依赖引入 <dependency> <groupId>com.wu</groupId> <artifactId>wu-easy-excel-starter</artifactId> <version>1.0.1-SNAPSHOT</version> </dependency> 基本用法 @Data public class UseExcel { @EasyExcelFiled(name = "id") private Integer id;...
相关文章
文章评论
共有0条评论来说两句吧...
文章二维码
点击排行

推荐阅读






最新文章
- Docker安装Oracle12C,快速搭建Oracle学习环境
- Docker使用Oracle官方镜像安装(12C,18C,19C)
- CentOS7安装Docker,走上虚拟化容器引擎之路
- Docker快速安装Oracle11G,搭建oracle11g学习环境
- CentOS7编译安装Cmake3.16.3,解决mysql等软件编译问题
- CentOS7编译安装Gcc9.2.0,解决mysql等软件编译问题
- CentOS8安装Docker,最新的服务器搭配容器使用
- Hadoop3单机部署,实现最简伪集群
- CentOS6,7,8上安装Nginx,支持https2.0的开启
- CentOS8编译安装MySQL8.0.19
 微信收款码
微信收款码 支付宝收款码
支付宝收款码