摘要:Karmada 社区也在持续关注云成本的管理,在最近发布的 v1.5 版本中,支持用户在分发策略 PropagationPolicy/ClusterPropagationPolicy 中设置多个集群调度组,实现将业务调度到成本更低的集群组中去。
本文分享自华为云社区《Karmada 多云容器编排引擎支持多调度组,助力成本优化!》,作者:华为云云原生团队
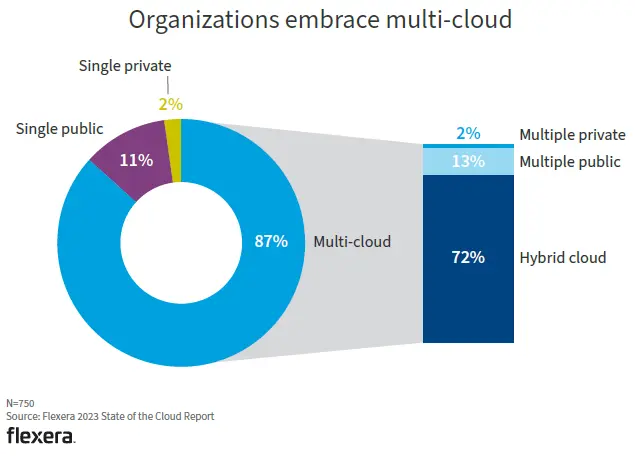
根据 Flexera 最新发布的《2023 年云现状调查报告》,在受访的750家企业中,使用多云的企业比例高达87%:
在使用多云的受访者中,排在前两位的多云挑战分别是:孤立在不同云上的应用程序和云之间的灾难恢复/故障切换。在所有组织中,最常用的多云工具是安全工具,紧随其后的是成本优化(Finops)工具。
此外,云成本的管理取代了安全性话题,成为当下云使用者面临的首要问题:
Karmada 社区也在持续关注云成本的管理,在最近发布的 v1.5 版本中,支持用户在分发策略 PropagationPolicy/ClusterPropagationPolicy 中设置多个集群调度组,实现将业务调度到成本更低的集群组中去。
多调度组
Karmada 的PropagationPolicy 支持声明单组集群,即.spec.placement.clusterAffinity,其 YAML 配置示例为:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinitiy:
- clusterNames:
- member1
- member2
Karmada v1.5 版本中,clusterAffinity 向 karmada-scheduler 提供一组候选集群,karmada-scheduler 根据相关限制(例如 spreadConstraint,插件过滤等)在候选集群之间做出调度决策,调度结果要么成功,要么失败。多调度组支持用户设置ClusterAffinities字段,在 PropagationPolicy 中声明多组集群,karmada-scheduler 可以依次来评估每个 clusterAffinity,进而做出决策。此功能允许 Karmada 调度程序在集群故障时首先将应用程序调度到低成本集群组,或将应用程序从主集群迁移到备份集群。
// Placement represents the rule for select clusters.
type Placement struct {
// ClusterAffinities 表示对 ClusterAffinityTerm 指示的多个集群组的调度限制。
// 调度程序将按照这些组在规范中出现的顺序逐个评估,不满足调度限制的组将被忽略,
// 这意味着除非该组中的所有集群也属于下一个组(同一集群可以属于多个组),
// 否则将不会选择此组中的所有集群。
// 如果没有一个组满足调度限制,则调度失败,这意味着不会选择集群。
// 注:ClusterAffinities 不能与 ClusterAffinity 共存。
// 如果未同时设置 ClusterAffinities 和 ClusterAffinity,则任何集群都可以作为调度候选集群。
//
// +optional
ClusterAffinities []ClusterAffinityTerm `json:"clusterAffinities,omitempty"`
}
// ClusterAffinityTerm selects a set of cluster.
type ClusterAffinityTerm struct {
// AffinityName 是集群组的名称.
// +required
AffinityName string `json:"affinityName"`
ClusterAffinity `json:",inline"`
}
云成本管理使用场景
用户可以使用多调度组来进行云成本的管理,例如:本地数据中心中的私有集群是主集群组,集群提供商提供的托管集群可以是辅助集群组,因此,Karmada 调度程序更愿意将工作负载调度到主集群组,只有在主集群组不满足限制(如缺乏资源)的情况下,才会考虑辅助集群组。下面我们给出一个针对成本优化进行调度的例子:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinities:
- affinityName: local-clusters
clusterNames:
- local-member1
- local-member2
- affinityName: cloud-clusters
clusterNames:
- huawei-member1
- huawei-member2
上面例子中配置有本地集群组(local-clusters)和云上集群组(cloud-clusters)共两个集群组,Karmada 在调度 Deployment/nginx 时,会优先尝试调度到本地集群组中的集群,如果失败(如缺乏资源),则继续选择云上集群组,从而实现在本地集群资源足够时,优先选择成本更低的本地集群的目标。
容灾与迁移场景
对于灾难恢复场景,系统管理员也可以定义主集群组和备份集群组,工作负载将首先调度到主集群组,当主集群组中的集群发生故障(如数据中心断电)时,Karmada 调度程序可以将工作负载迁移到备份集群组。
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinities:
- affinityName: primary-cluster
clusterNames:
- member1
- affinityName: backup-cluster
clusterNames:
- member2
上面的例子通过配置主集群组(primary-cluster)和备份集群组(backup-cluster),在调度 Deployment/nginx 时,如果主集群组满足要求,会调度到主集群组中的 member1 集群,当member1 集群故障时,调度器按顺序匹配新集群组,从而将业务迁移到备份集群组中的member2 上,这样就达成了容灾的目的。
总结
支持多调度组设置为用户提供了更丰富的多集群资源分发策略选择,Karmada 后续也会继续探索云成本的管理,大家有任何感兴趣的想法,都欢迎大家来 Karmada 社区进行讨论与分享。
附:Karmada社区交流地址
项目地址:https://github.com/karmada-io/karmada
Slack地址:https://slack.cncf.io/
点击关注,第一时间了解华为云新鲜技术~