openGauss 3.1.1是openGauss 5.0.0 release版本的Preview版本,希望广大社区伙伴和开发者基于此版本进行场景化验证,提前发现问题并反馈社区,社区将在LTS版本发布前进行问题修复。当前文档说明范围仅限企业版。
版本介绍
3.1.1与之前的版本特性功能保持兼容,主要功能如下:
继承功能:
- 基础功能:SQL标准语法、数据类型、表(包括临时表、全局临时表、外部表)、视图、物化视图、外键、索引(包括btree索引、Gin索引、hash索引)、序列、函数、触发器、聚合函数median、ROWNUM、UPSERT、、jsonb数据类型、GB18030字符集。
- 存储过程:存储过程、存储过程内commit/rollback、参数的存储过程/函数调用省略()、存储过程调试。
- 安全功能:认证、权限管理、网络通信安全、数据库审计、全密态数据库、动态数据脱敏、国密算法、防篡改账本数据库、内置角色和权限管理、透明加密、ANY权限管理等。
- 高可用:主备双机、级联备机、逻辑复制、极致RTO、备机扩容、基于Paxos分布式一致性协议(DCF)、两地三中心跨Region容灾。
- SQL引擎增强:范围分区、全局分区索引、LIST分区、HASH分区、基于范围分区的自动扩展分区、行存转向量化、自治事务、并行查询、Global Syscache、IPv6协议、postgis插件。
- 存储引擎增强:延迟备库、备机支持逻辑复制、并行逻辑解码、灰度升级、滚动升级、Hash索引、列存表主键唯一约束、Ustore存储引擎、段页式存储、发布订阅、行存表压缩、MOT内存表、NUMA-aware高性能优化等。
- 备份恢复:全量物理备份、逻辑备份、备机备份、增量备份和恢复、恢复到指定时间点(PITR)。
- AI能力:参数自调优、慢SQL发现、AI查询时间预测、数据库指标采集预测与异常监控、DBMind自治运维平台、智能优化器、智能索引推荐、deepSQL库内AI算法、库内AI算法支持XGBoost、multiclass和PCA。
- 运维能力:WDR诊断报告新增数据库运行指标、备机慢SQL诊断视图、unique sql自动淘汰。
- JDBC:支持JDBC客户端负载均衡及读写分离。
- CM:支持CM集群管理,CM支持自定义资源管控,支持对外状态查询和推送能力。
- 工具链:开发工具DataStudio、数据迁移工具chameleon。
- 中间件:shardingSphere、openLookeng。
- 周边生态:dblink,支持openEuler、CentOS、Ubuntu、FusionOS系统
- 其他:cmake脚本编译、容器化部署、kubernetes
新增功能:
- 主备共享存储
- MySQL兼容性增强
- CM部署和数据库部署解耦,CM支持增量升级
- MOT内存表能力增强
其中,主备共享存储特性是3.1.X版本引入的比较重要特性。下面重点介绍一下。
主备共享存储
特性简介
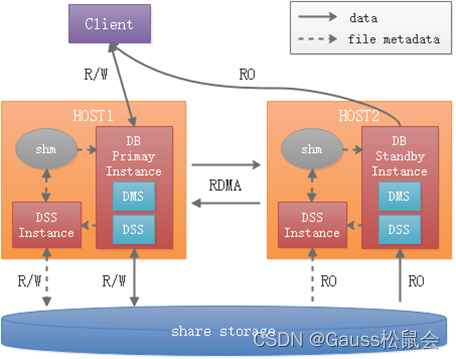
本特性提供主备机共享一份存储的能力,实现基于磁阵设备的主备共享存储HA部署形态,可选通过OCK RDMA提升备机实时一致性读能力_。_主备共享存储架构图如下图所示。
![在这里插入图片描述]()
图 1 主备共享架构图
客户价值
解决传统HA部署下存储容量较单机部署翻倍的问题,减少了存储容量,节省磁阵设备。可选通过OCK RDMA提升备机实时一致性读能力。
特性描述
-共享存储依赖两个自研的公共组件实现主备共享存储的能力:
- 分布式存储服务DSS(Distributed Storage Service)
DSS是独立进程,直接管理磁阵裸设备,并对外提供类似分布式文件系统的能力。通过共享内存和客户端API动态库,为数据库提供创建文件、删除文件、扩展和收缩文件、读写文件的能力。
- 分布式内存服务DMS(Distributed Memory Service)
DMS是动态库,集成在数据库内部,通过TCP/RDMA网络传输PAGE内容,将主备内存融合,提供内存池化能力,以此实现备机实时一致性读功能。
共享存储通过分布式存储服务DSS组件实现主备共享一份存储。与传统建库相比,共享存储基于磁阵建库将目录分为三种类型,每实例独占且不共享、每实例独占且共享、所有实例共享。其中需要共享的目录均需存放到磁阵设备上,而不共享的目录存放在本地盘上。另外备机建库只需要建隶属于自己的目录,不需要再次创建所有实例共享的目录结构。主备共享存储新增了相关GUC参数,以及将系统表存储方式从页式切换到段页式。
共享存储通过分布式内存服务DMS组件实现主备页面实时交换,提供备机实时一致性能力。即主机事务提交后,在备机立即能够读到,不存在延迟读现象(事务隔离级别为Read-Committed)。
共享存储通过OCK RDMA降低DMS主备页面交换时延。TCP下的备机一致性读进行时延对比,开启OCK RDMA,备机一致性读时延至少要降低20%。
特性约束
主备共享存储方案依赖于磁阵设备,磁阵的LUN需要支持SCSI3的PR协议(包括PR OUT(“PERSISTENT RESERVE OUT”)PR IN(“PERSISTENT RESERVE IN”)和INQUIRY), 用于实现集群IO FENCE。除此之外, 还需要支持SCSI3的CAW协议(COMPARE AND WRITE),用于实现共享磁盘锁。如Dorado 5000 V3磁阵设备。
实现的主备共享存储HA部署形态只支持1主1备和1主2备场景,其他场景为体验版未测试过,不承诺。
由于主备共享存储依赖类似分布式文件系统的功能来实现备机实时一致性读能力,因此要求文件元数据变更越少越好。基于性能考虑,只支持段页式表。
只支持主备部署在同一磁阵设备上,不支持容灾部署,也不支持主备混合部署(如主和备部署在不同的磁阵设备上)。
主备页面交换通过RDMA加速,依赖CX5网卡,并且依赖OCK RDMA动态库。
暂不支持备机重建及节点替换、节点修复等能力。
不支持从传统HA部署升级到基于主备共享存储部署。
共享存储模式下gs_xlogdump_xid,gs_xlogdump_lsn,gs_xlogdump_tablepath,gs_xlogdump_parsepage_tablepath、pg_create_logical_replication_slot、gs_verify_and_tryrepair_page、gs_repair_page、gs_repair_file函数功能不支持使用。
共享存储模式下T_CreatePublicationStmt、T_AlterPublicationStmt、T_CreateSubscriptionStmt、T_AlterSubscriptionStmt、T_DropSubscriptionStmt订阅功能不支持使用。
共享存储模式下不支持全局临时表。
安装部分对应的也新增了共享存储场景的支持。cluster_config_template.xml配置文件模板示例:
...
<!-- 共享存储模式开关 -->
<PARAM name="enable_dss" value="on"/>
<!-- dss实例目录 -->
<PARAM name="dss_home" value="/opt/huawei/install/data/dss"/>
<!-- dss共享卷名 -->
<PARAM name="ss_dss_vg_name" value="data"/>
<!-- dss挂载卷组名和卷组信息,包含共享卷 -->
<PARAM name="dss_vg_info" value="data:/dev/sdb,p0:/dev/sdc,p1:/dev/sdd"/>
<!-- cm投票卷 -->
<PARAM name="votingDiskPath" value="/dev/sde"/>
<!-- cm共享卷 -->
<PARAM name="shareDiskDir" value="/dev/sdf"/>
<!-- dss开启ssl认证开关 -->
<PARAM name="dss_ssl_enable" value="on"/>
<!-- mes通信协议类型 -->
<PARAM name="ss_interconnect_type" value="TCP"/>
<!-- rdma绑定cpu序列 -->
<PARAM name="ss_rdma_work_config" value="1 7"/>
欢迎有兴趣和条件的同学可以对主备共享存储特性进行场景化验证。